This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Reading Larry Burns’ “DataModel Storytelling” (TechnicsPub.com, 2021) was a really good experience for a guy like me (i.e., someone who thinks that datamodels are narratives). However, this post is not a review of Larry’s book. The post Tales of DataModelers appeared first on DATAVERSITY.
The primary aim is to make sense of the vast amounts of data generated daily by combining statistical analysis, programming, and data visualization. It is divided into three primary areas: data preparation, datamodeling, and data visualization.
I’ve found that while calculating automation benefits like time savings is relatively straightforward, users struggle to estimate the value of insights, especially when dealing with previously unavailable data. We were developing a datamodel to provide deeper insights into logistics contracts.
This article is an excerpt from the book Expert DataModeling with Power BI, Third Edition by Soheil Bakhshi, a completely updated and revised edition of the bestselling guide to Power BI and datamodeling. No-code/low-code experience using a diagram view in the data preparation layer similar to Dataflows.
Machine learning requires computation on large data sets, which means that a strong foundation in fundamental skills such as computer architecture, algorithms, data structures, and complexity is crucial. It is essential to delve deeply into programming books and explore new concepts to gain a competitive edge in the field.
Trained with 570 GB of data from books and all the written text on the internet, ChatGPT is an impressive example of the training that goes into the creation of conversational AI. They are designed to understand and generate human-like language by learning from a large dataset of texts, such as books, articles, and websites.
It has helped to write a book. The world is full of uncreative boilerplate content that humans have to write: catalog entries, financial reports, back covers for books (I’ve written more than a few), and so on. Many applications built on language models use a hidden layer of prompts to tell the model what is and isn’t allowed.
where each book represents a record, each chapter represents a field, and each shelf represents a table. These databases are the most common type used today and store data in a structured format using tables, rows, and columns. Some of the most popular relational databases include Oracle, MySQL, and Microsoft SQL Server.
Introduction: The Customer DataModeling Dilemma You know, that thing we’ve been doing for years, trying to capture the essence of our customers in neat little profile boxes? For years, we’ve been obsessed with creating these grand, top-down customer datamodels. Yeah, that one.
You see them all the time with a headline like: “data science, machine learning, Java, Python, SQL, or blockchain, computer vision.” We’re assuming that data scientists, for the most part, don’t want to write transformations elsewhere. It’s two things. But at the end of the day, that’s what it is, right?
In a world of ever-evolving data tools and technologies, some approaches stand the test of time. Thats the case Dustin DorseyPrincipal Data Architect at Onyx makes for dimensional datamodeling , a practice born in the 1990s that continues to provide clarity, performance, and scalability in modern data architecture.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










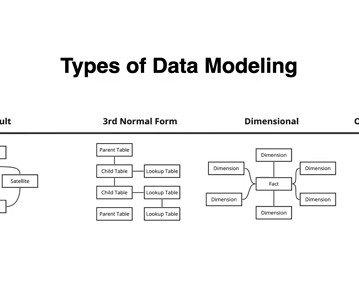






Let's personalize your content