This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
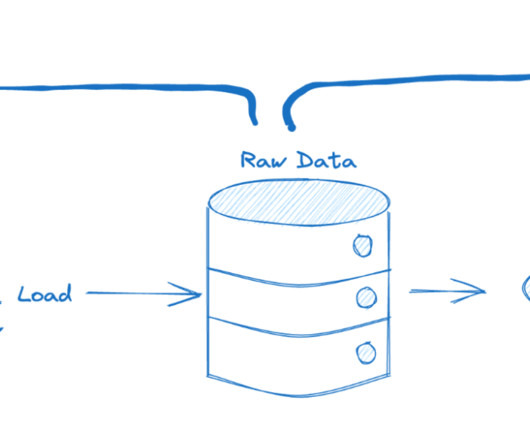
When it comes to data, there are two main types: datalakes and data warehouses. What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications. Which one is right for your business?
While there is a lot of discussion about the merits of data warehouses, not enough discussion centers around datalakes. We talked about enterprise data warehouses in the past, so let’s contrast them with datalakes. Both data warehouses and datalakes are used when storing big data.
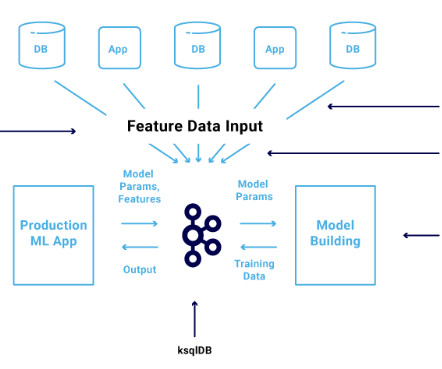
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
DataLakes have been around for well over a decade now, supporting the analytic operations of some of the largest world corporations. Such data volumes are not easy to move, migrate or modernize. The challenges of a monolithic datalake architecture Datalakes are, at a high level, single repositories of data at scale.
Architecturally the introduction of Hadoop, a file system designed to store massive amounts of data, radically affected the cost model of data. Organizationally the innovation of self-service analytics, pioneered by Tableau and Qlik, fundamentally transformed the user model for data analysis. Disruptive Trend #1: Hadoop.
Rockets legacy data science environment challenges Rockets previous data science solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided Data Science Experience development tools. This also led to a backlog of data that needed to be ingested.
Here comes the role of Hive in Hadoop. Hive is a powerful data warehousing infrastructure that provides an interface for querying and analyzing large datasets stored in Hadoop. In this blog, we will explore the key aspects of Hive Hadoop. What is Hadoop ? Thus ensuring optimal performance.
Discover the nuanced dissimilarities between DataLakes and Data Warehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are DataLakes and Data Warehouses. It acts as a repository for storing all the data.
Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms. In this blog, we will discuss: What is the Open Table format (OTF)? It can also be integrated into major data platforms like Snowflake.
Best 8 data version control tools for 2023 (Source: DagsHub ) Introduction With business needs changing constantly and the growing size and structure of datasets, it becomes challenging to efficiently keep track of the changes made to the data, which leads to unfortunate scenarios such as inconsistencies and errors in data.
But what most people don’t realize is that behind the scenes, Uber is not just a transportation service; it’s a data and analytics powerhouse. Every day, millions of riders use the Uber app, unwittingly contributing to a complex web of data-driven decisions. This enables them to batch queries based on speed or accuracy.
This blog was originally written by Keith Smith and updated for 2023 by Nick Goble & Dominick Rocco. You’ve probably heard of the Snowflake Data Cloud , but did you know that Snowflake also offers a revolutionary set of libraries and runtimes called Snowpark? What is Snowflake’s Snowpark?
And where data was available, the ability to access and interpret it proved problematic. Big data can grow too big fast. Left unchecked, datalakes became data swamps. Some datalake implementations required expensive ‘cleansing pumps’ to make them navigable again. Subscribe to Alation's Blog.
In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different data platform solution. Hence, DataLake emerged, which handles unstructured and structured data with huge volume. All phases of the data-information lifecycle.
And you should have experience working with big data platforms such as Hadoop or Apache Spark. Additionally, data science requires experience in SQL database coding and an ability to work with unstructured data of various types, such as video, audio, pictures and text.
Summary: This blog delves into the multifaceted world of Big Data, covering its defining characteristics beyond the 5 V’s, essential technologies and tools for management, real-world applications across industries, challenges organisations face, and future trends shaping the landscape.
Prior joining AWS, as a Data/Solution Architect he implemented many projects in Big Data domain, including several datalakes in Hadoop ecosystem. As a Data Engineer he was involved in applying AI/ML to fraud detection and office automation.
A well-structured syllabus for Big Data encompasses various aspects, including foundational concepts, technologies, data processing techniques, and real-world applications. This blog aims to provide a comprehensive overview of a typical Big Data syllabus, covering essential topics that aspiring data professionals should master.
This highlights the two companies’ shared vision on self-service data discovery with an emphasis on collaboration and data governance. 2) When data becomes information, many (incremental) use cases surface. Paxata booth visitors encompassed a broad range of roles, all with data responsibility in some shape or form.
As a cornerstone of your data architecture the EDM is a serious undertaking whether it is enabled by building on existing technologies or by deploying a single tool that includes all of the functions needed to successfully implement one. Here’s how The Eckerson Group breaks it down: Subscribe to Alation's Blog.
These tools may have their own versioning system, which can be difficult to integrate with a broader data version control system. For instance, our datalake could contain a variety of relational and non-relational databases, files in different formats, and data stored using different cloud providers. DVC Git LFS neptune.ai
With its user-friendly interface and robust architecture, NiFi simplifies the complexities of data integration, making it an essential component for modern data-driven enterprises. This blog delves into the fundamentals of Apache NiFi, its architecture, and how it can leverage for effective data flow management.
Finding that data is often half the battle. This is why the ability to quickly search and discover data across the enterprise is the first step towards data-driven decision making. In this blog, we will discuss how data catalogs accelerate search & discovery. Subscribe to Alation's Blog.
Introduction Business Intelligence (BI) architecture is a crucial framework that organizations use to collect, integrate, analyze, and present business data. This architecture serves as a blueprint for BI initiatives, ensuring that data-driven decision-making is efficient and effective.
If you’ve been watching how Snowflake Data Cloud has been growing and changing over the years, you’ll see that two tools have made very large impacts on the Modern Data Stack: Fivetran and dbt. Data volumes exploded as web, mobile, and IoT took off. ETL systems just couldn’t handle the massive flows of raw data.
Accordingly, one of the most demanding roles is that of Azure Data Engineer Jobs that you might be interested in. The following blog will help you know about the Azure Data Engineering Job Description, salary, and certification course. Data Warehousing concepts and knowledge should be strong.
.” Part of GoDaddy’s transformation was to get the right customer data consolidated in one place and make it accessible to every employee for data-driven decision making. This meant a large Hadoop deployment, self-service analytics tools available to every employee with Tableau, and a data catalog from Alation.
Summary: This blog explains how to build efficient data pipelines, detailing each step from data collection to final delivery. Introduction Data pipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
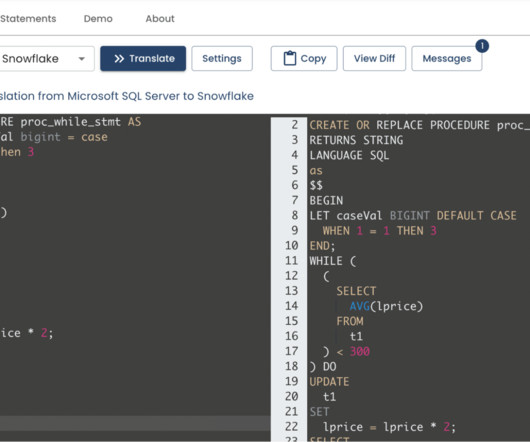
In this blog, we’re going to answer these questions and more. Walking you through the biggest challenges we have found when migrating our customer’s data from a legacy system to Snowflake. You’re in luck because this blog is for anyone ready to move or thinking about moving to Snowflake who wants to know what’s in store for them.
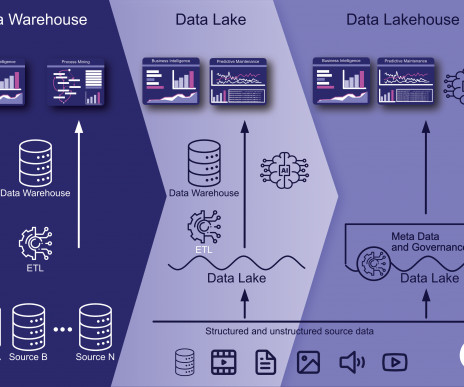
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines DataLake und eines Data Warehouse kombiniert. Die Definition eines Data Lakehouse Ein Data Lakehouse ist eine moderne Datenspeicher- und -verarbeitungsarchitektur, die die Vorteile von DataLakes und Data Warehouses vereint.
Big Data tauchte als Buzzword meiner Recherche nach erstmals um das Jahr 2011 relevant in den Medien auf. Big Data wurde zum Business-Sprech der darauffolgenden Jahre. In der Parallelwelt der ITler wurde das Tool und Ökosystem Apache Hadoop quasi mit Big Data beinahe synonym gesetzt. Retrieved August 1, 2020.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content