Unifying Your Data Ecosystem with Delta Lake Integration
databricks
MAY 9, 2023
As organizations are maturing their data infrastructure and accumulating more data than ever before in their data lakes, Open and Reliable table formats.
 Blog Data Engineering Data Lakes
Blog Data Engineering Data Lakes 
databricks
MAY 9, 2023
As organizations are maturing their data infrastructure and accumulating more data than ever before in their data lakes, Open and Reliable table formats.

databricks
JUNE 6, 2023
Apache Parquet is one of the most popular open source file formats in the big data world today. Being column-oriented, Apache Parquet allows.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Data Science Blog
MAY 20, 2024
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in data science and data engineering. It offers full BI-Stack Automation, from source to data warehouse through to frontend.

IBM Data Science in Practice
MAY 19, 2025
The Data Dilemma: From Chaos toClarity In the world of data management, weve all beenthere: A simple request spirals into a maze of thingslike: A CSV labeled final_v2_final_final.csv A Parquet file in a forgotten S3folder A table with brokenlineage An abandoned SQL notebook from yearsago What starts as a data lake often becomes a dataswamp!
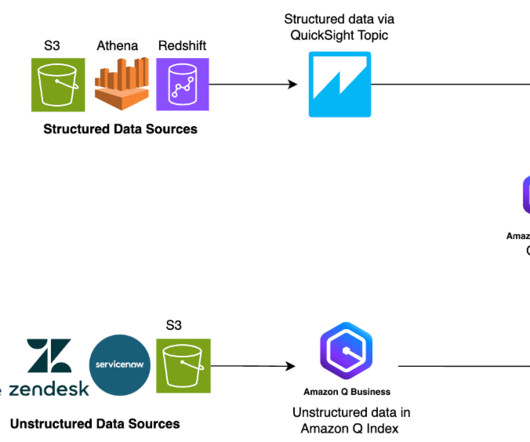
MAY 14, 2025
Their information is split between two types of data: unstructured data (such as PDFs, HTML pages, and documents) and structured data (such as databases, data lakes, and real-time reports). Different types of data typically require different tools to access them. Traditionally, businesses face a challenge.

phData
SEPTEMBER 19, 2023
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a Data Lake? Consistency of data throughout the data lake.

Alation
FEBRUARY 20, 2020
When it was no longer a hard requirement that a physical data model be created upon the ingestion of data, there was a resulting drop in richness of the description and consistency of the data stored in Hadoop. You did not have to understand or prepare the data to get it into Hadoop, so people rarely did.

Expert insights. Personalized for you.
































Let's personalize your content