This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Traditional keyword-based search mechanisms are often insufficient for locating relevant documents efficiently, requiring extensive manual review to extract meaningful insights. This solution improves the findability and accessibility of archival records by automating metadata enrichment, document classification, and summarization.
The traditional approach of manually sifting through countless research documents, industry reports, and financial statements is not only time-consuming but can also lead to missed opportunities and incomplete analysis. Along the way, it also simplified operations as Octus is an AWS shop more generally.
For many of these use cases, businesses are building Retrieval Augmented Generation (RAG) style chat-based assistants, where a powerful LLM can reference company-specific documents to answer questions relevant to a particular business or use case. Generate a grounded response to the original question based on the retrieved documents.
Expand to generative AI use cases with your existing AWS and Tecton architecture After you’ve developed ML features using the Tecton and AWSarchitecture, you can extend your ML work to generative AI use cases. You can also find Tecton at AWS re:Invent. This process is shown in the following diagram.
Let’s transition to exploring solutions and architectural strategies. Approaches to researcher productivity To translate our strategic planning into action, we developed approaches focused on refining our processes and systemarchitectures. No one writes any code manually.
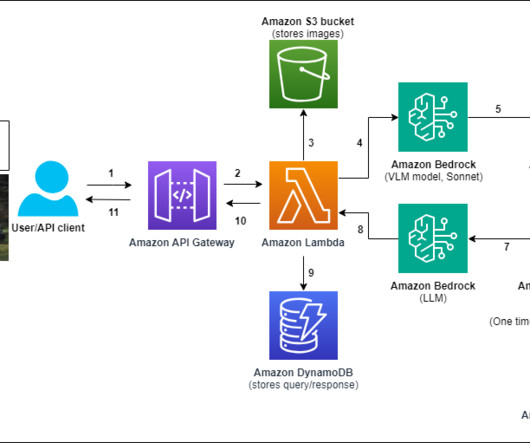
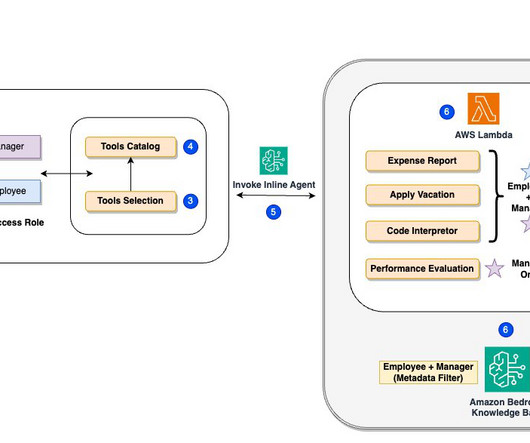
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. AWS Lambda functions for executing specific actions (such as submitting vacation requests or expense reports). Nitin Eusebius is a Sr.
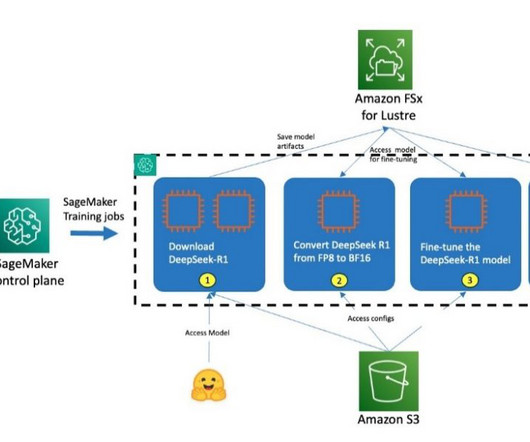
You can execute each step in the training pipeline by initiating the process through the SageMaker control plane using APIs, AWS Command Line Interface (AWS CLI), or the SageMaker ModelTrainer SDK. These steps are encapsulated in a prologue script and are documented step-by-step under the Fine-tuning section.
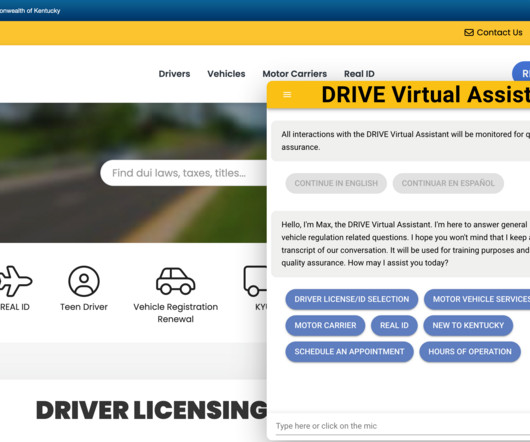
Solution overview To tackle these challenges, the KYTC team reviewed several contact center solutions and collaborated with the AWS ProServe team to implement a cloud-based contact center and a virtual agent named Max. Amazon Lex and the AWS QnABot Amazon Lex is an AWS service for creating conversational interfaces.
It involves transforming textual data into numerical form, known as embeddings, representing the semantic meaning of words, sentences, or documents in a high-dimensional vector space. Combine this with the serverless BentoCloud or an auto-scaling group on a cloud platform like AWS to ensure your resources match the demand.
AWS FSI customers, including NASDAQ, State Bank of India, and Bridgewater, have used FMs to reimagine their business operations and deliver improved outcomes. To use Automated Reasoning checks, you first create an Automated Reasoning policy by encoding a set of logical rules and variables from available source documentation.
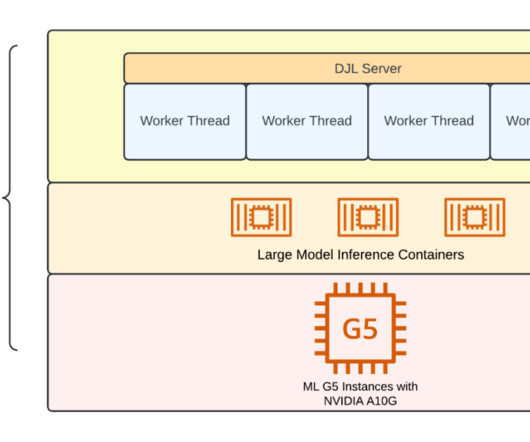
Due to their massive size and the need to train on large amounts of data, FMs are often trained and deployed on large compute clusters composed of thousands of AI accelerators such as GPUs and AWS Trainium. Alternatively and recommended, you can deploy a ready-made EKS cluster with a single AWS CloudFormation template. The fsdp-ray.py
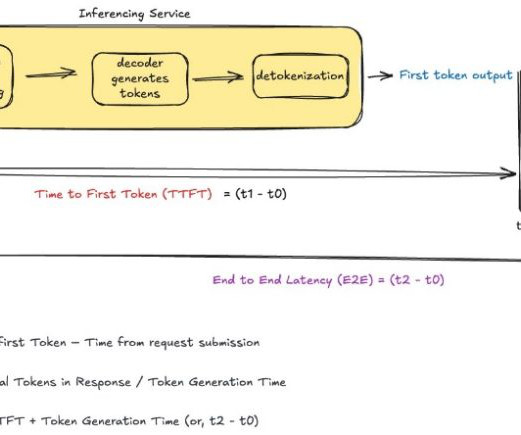
This optimization is available in the US East (Ohio) AWS Region for select FMs, including Anthropics Claude 3.5 In this section, we explore how different system components and architectural decisions impact overall application responsiveness. Rupinder Grewal is a Senior AI/ML Specialist Solutions Architect with AWS.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













Let's personalize your content