This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
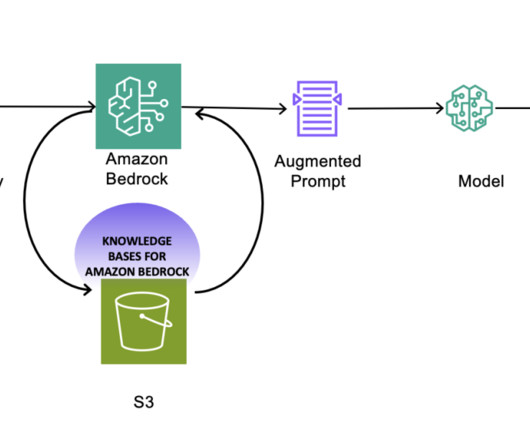
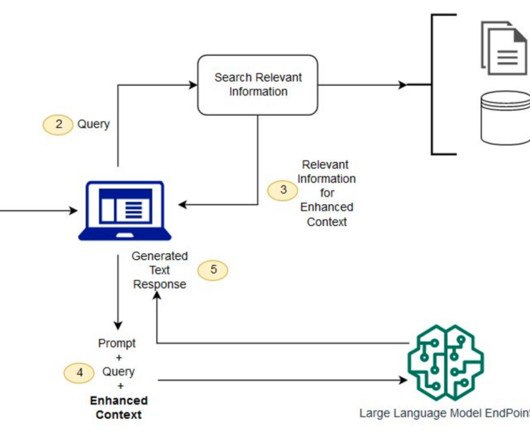
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies and AWS. Solution overview The following diagram provides a high-level overview of AWS services and features through a sample use case.
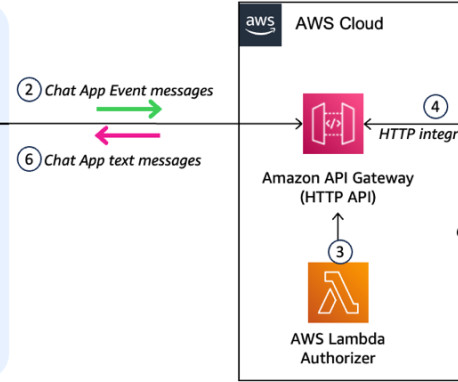
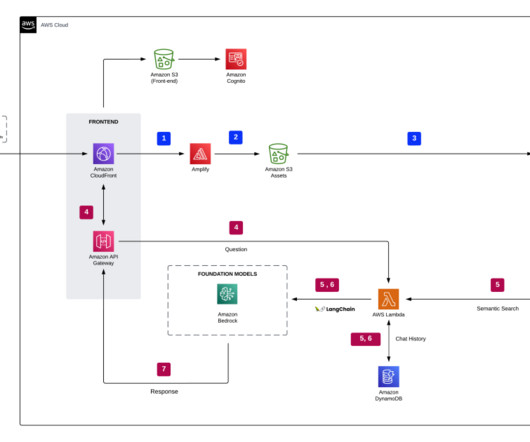
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
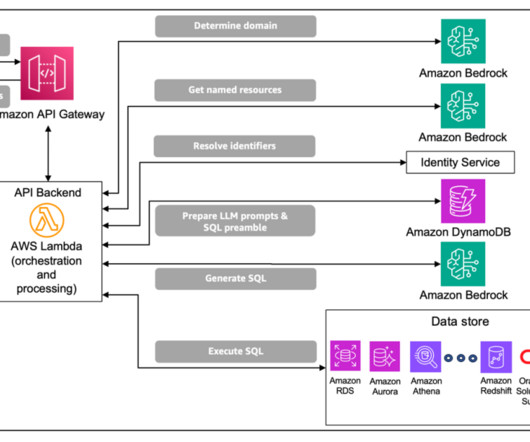
These tables house complex domain-specific schemas, with instances of nested tables and multi-dimensional data that require complex database queries and domain-specific knowledge for data retrieval. As a result, NL2SQL solutions for enterprise data are often incomplete or inaccurate.
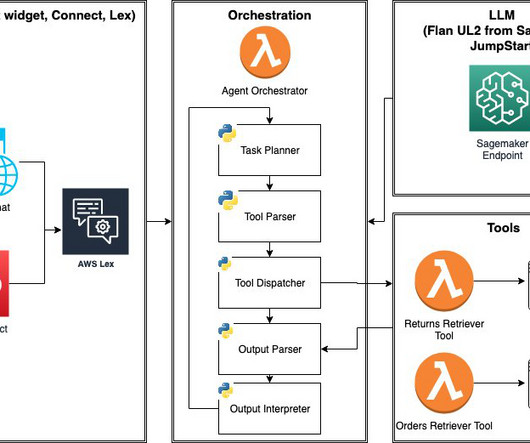
The Lambda function runs the database query against the appropriate OpenSearch Service indexes, searching for exact matches or using fuzzy matching for partial information. For specific part inquiries, the agent consults the action groups available to the agent and invokes the correct action (API) to retrieve relevant information.
In this post, we save the data in JSON format, but you can also choose to store it in your preferred SQL or NoSQL database. Prerequisites To perform this solution, complete the following: Create and activate an AWS account. Make sure your AWS credentials are configured correctly. Install Python 3.7
Also, traditional database management tasks, including backups, upgrades and routine maintenance drain valuable time and resources, hindering innovation. By using fit-for-purpose databases, customers can efficiently run workloads, using the appropriate engine at the optimal cost to optimize analytics for the best price-performance.
Prerequisites Before you begin, make sure you have the following prerequisites in place: An AWS account and role with the AWS Identity and Access Management (IAM) privileges to deploy the following resources: IAM roles. Open the AWS Management Console, go to Amazon Bedrock, and choose Model access in the navigation pane.
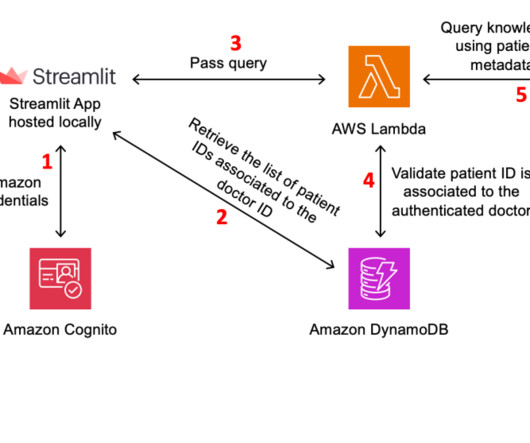
To assist in this effort, AWS provides a range of generative AI security strategies that you can use to create appropriate threat models. For all data stored in Amazon Bedrock, the AWS shared responsibility model applies. The high-level steps are as follows: For our demo , we use a web application UI built using Streamlit.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! are the sessions dedicated to AWS DeepRacer ! Generative AI is at the heart of the AWS Village this year. You marked your calendars, you booked your hotel, and you even purchased the airfare. And last but not least (and always fun!)
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The following demo shows Agent Creator in action.
Because Amazon Bedrock is serverless, you don’t have to manage infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with. The framework for connecting Anthropic Claude 2 and CBRE’s sample database was implemented using LangChain.
Tens of thousands of cloud computing professionals and enthusiasts will gather in Las Vegas for Amazon Web Services’ (AWS) re:Invent 2024 from December 2-6. AWS re:Invent 2024: Generative AI in focus at Las Vegas event Attendees can expect a robust emphasis on generative AI throughout the event, with over 500 sessions planned.
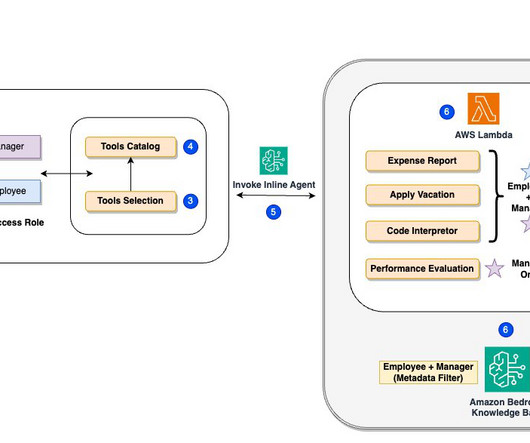
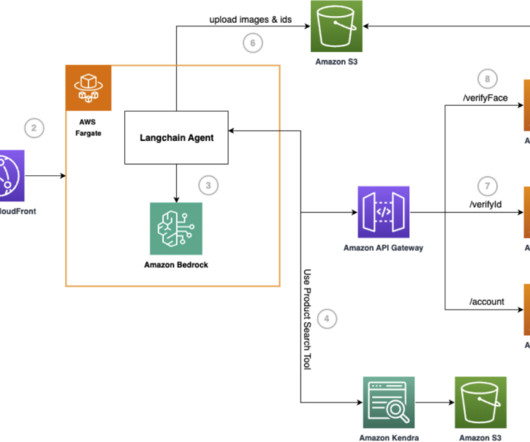
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. AWS Lambda functions for executing specific actions (such as submitting vacation requests or expense reports).
Managing your Amazon Lex bots using AWS CloudFormation allows you to create templates defining the bot and all the AWS resources it depends on. AWS CloudFormation provides and configures those resources on your behalf, removing the risk of human error when deploying bots to new environments. Resources: # 1.
Discover your data and put it to work using familiar AWS tools to complete end-to-end development workflows, including data analysis, data processing, model training, generative AI app building, and more, in a single governed environment. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources.
Often, LLMs need to interact with other software, databases, or APIs to accomplish complex tasks. In this post, we introduce LLM agents and demonstrate how to build and deploy an e-commerce LLM agent using Amazon SageMaker JumpStart and AWS Lambda. Next, we show how to implement a simple agent loop using AWS services.
Why IBM Consulting and AWS? IBM is a Premier Consulting Partner for AWS, with 19,000+ AWS certified professionals across the globe, 16 service validations and 15 AWS competencies—becoming the fastest Global GSI to secure more AWS competencies and certifications among Top-16 AWS Premier GSI’s within 18 months.
Instead of relying solely on their pre-trained knowledge, RAG allows models to pull data from documents, databases, and more. This means that as new data becomes available, it can be added to the retrieval database without needing to retrain the entire model. Memory efficiency – LLMs require significant memory to store parameters.
In this post, we show you how SnapLogic , an AWS customer, used Amazon Bedrock to power their SnapGPT product through automated creation of these complex DSL artifacts from human language. SnapLogic background SnapLogic is an AWS customer on a mission to bring enterprise automation to the world.
In this quest, IBM and AWS have forged a strategic alliance, aiming to transition AI’s business potential from mere talk to tangible action. The AWS-IBM partnership is a symphony of strengths The collaboration between IBM and AWS is more than just a tactical alliance; it’s a symphony of strengths.
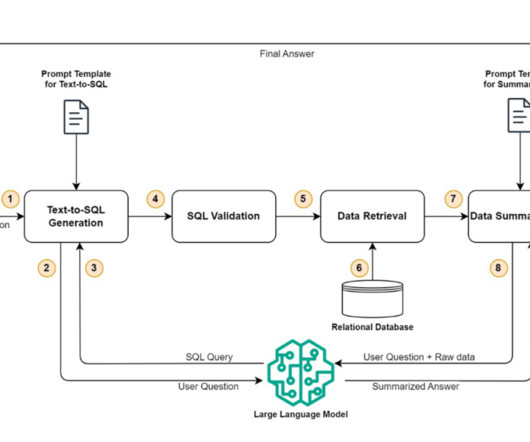
Text-to-SQL generation This step takes the user’s questions as input and converts that into a SQL query that can be used to retrieve the claim- or benefit-related information from a relational database. Data retrieval After the query has been validated, it is used to retrieve the claims or benefits data from a relational database.
Amazon DocumentDB is a fully managed native JSON document database that makes it straightforward and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. Enter a connection name such as demo and choose your desired Amazon DocumentDB cluster. Finally, select your read preference.
The SageMaker Studio domains are deployed in VPC only mode, which creates an elastic network interface for communication between the SageMaker service account (AWS service account) and the platform account’s VPC. This process of ordering a SageMaker domain is orchestrated through a separate workflow process (via AWS Step Functions ).
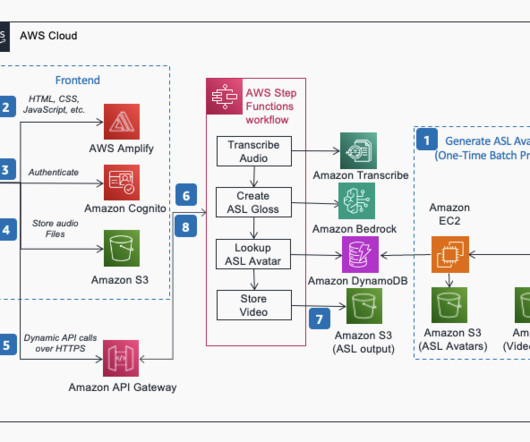
AWS makes it possible for organizations of all sizes and developers of all skill levels to build and scale generative AI applications with security, privacy, and responsible AI. In this post, we dive into the architecture and implementation details of GenASL, which uses AWS generative AI capabilities to create human-like ASL avatar videos.
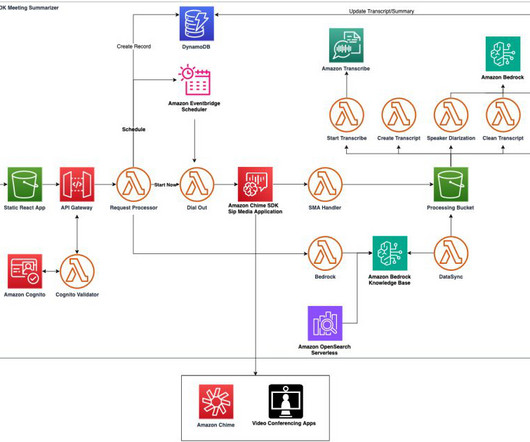
To address this challenge, we’ve developed the Amazon Chime SDK Meeting Summarizer application deployed with the Amazon Cloud Development Kit (AWS CDK). Solution overview The following infrastructure diagram provides an overview of the AWS services that are used to create this meeting summarization bot. How are you spk_0: doing ?
The new Amazon Relational Database Service (Amazon RDS) for Db2 offering allows customers to migrate their existing, self-managed Db2 databases to the cloud and accelerate strategic modernization initiatives. In our recent webcast , IBM, AWS, customers and partners came together for an interactive session.
In November 2022, we announced that AWS customers can generate images from text with Stable Diffusion models in Amazon SageMaker JumpStart , a machine learning (ML) hub offering models, algorithms, and solutions. AWS provides a plethora of options and services to facilitate this endeavor.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Prerequisites To continue with the examples in this post, you need to create the required AWS resources.
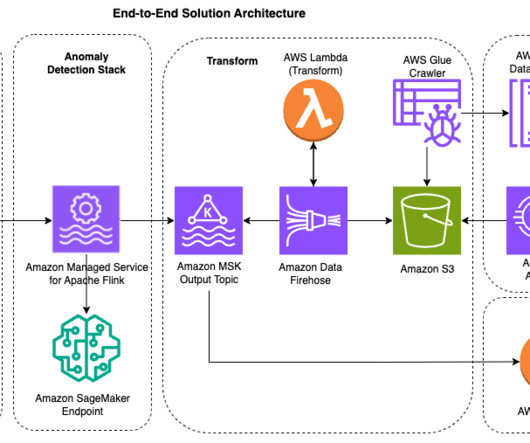
In this post, we demonstrate how to build a robust real-time anomaly detection solution for streaming time series data using Amazon Managed Service for Apache Flink and other AWS managed services. It offers an AWS CloudFormation template for straightforward deployment in an AWS account. anomalyScore":0.0,"detectionPeriodStartTime":"2024-08-29
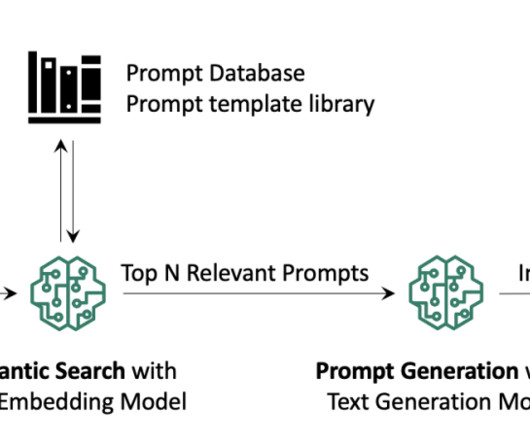
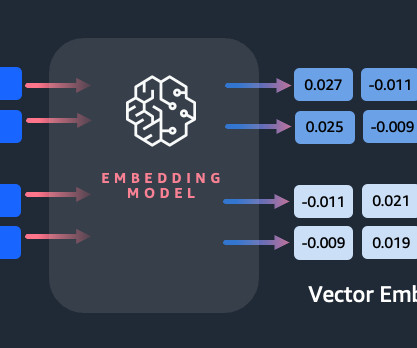
In addition to semantic search, you can use embeddings to augment your prompts for more accurate results through Retrieval Augmented Generation (RAG)—but in order to use them, you’ll need to store them in a database with vector capabilities. You can use it via either the Amazon Bedrock REST API or the AWS SDK. Nitin Eusebius is a Sr.
With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the Amazon Web Services (AWS) tools without having to manage infrastructure. The following diagram depicts a high-level RAG architecture. Choose Next.
Our solution provides practical guidance on addressing this challenge by using a generative AI assistant on AWS. The approach uses Retrieval Augmented Generation (RAG) , which combines text generation capabilities with database querying to provide contextually relevant responses to customer inquiries.
We are excited to announce a new version of the Amazon SageMaker Operators for Kubernetes using the AWS Controllers for Kubernetes (ACK). ACK is a framework for building Kubernetes custom controllers, where each controller communicates with an AWS service API. They are also supported by AWS CloudFormation. Release v1.2.9
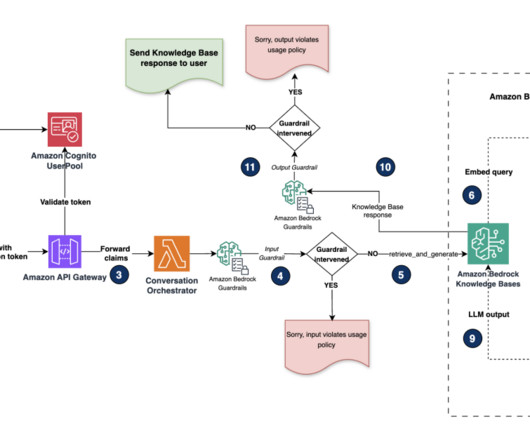
Knowledge Bases for Amazon Bedrock allows you to build performant and customized Retrieval Augmented Generation (RAG) applications on top of AWS and third-party vector stores using both AWS and third-party models. RAG is a popular technique that combines the use of private data with large language models (LLMs).
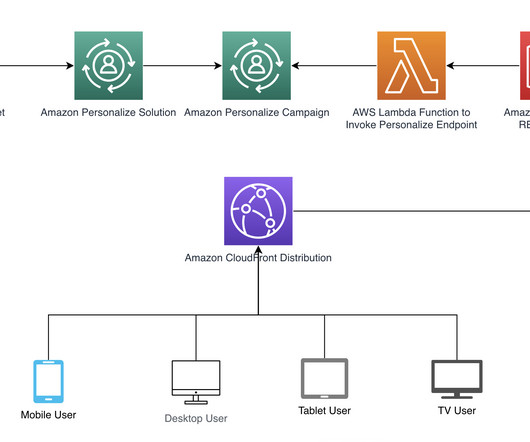
Automatically deriving context is achieved through Amazon CloudFront headers that are included in requests such as a REST API in Amazon API Gateway that calls an AWS Lambda function to retrieve recommendations. We provide a AWS CloudFormation template to create the necessary resources.
For multiple-choice reasoning, we prompt AI21 Labs Jurassic-2 Mid on a small sample of questions from the AWS Certified Solutions Architect – Associate exam. Prerequisites This walkthrough assumes the following prerequisites: An AWS account with a ml.t3.medium We use Cohere Command and AI21 Labs Jurassic-2 Mid for this demo.
AWS is uniquely positioned to help you address these challenges through generative AI, with a broad and deep range of AI/ML services and over 20 years of experience in developing AI/ML technologies. Because RAG uses a semantic search, it can find more relevant material in the database than just a keyword match alone.
Built on AWS technologies like AWS Lambda , Amazon API Gateway , and Amazon DynamoDB , this tool automates the creation of customizable templates and supports both text and image inputs. The following diagram illustrates the solution architecture.
For production use, it is recommended to use a more robust frontend framework such as AWS Amplify , which provides a comprehensive set of tools and services for building scalable and secure web applications. The process is straightforward, thanks to the user-friendly interface and step-by-step guidance provided by the AWS Management Console.
They want to capitalize on generative AI and translate the momentum from betas, prototypes, and demos into real-world productivity gains and innovations. Optimized to provide a fast response on AWS infrastructure, the Llama 2 models available via Amazon Bedrock are ideal for dialogue use cases.
The final retrieval augmentation workflow covers the following high-level steps: The user query is used for a retriever component, which does a vector search, to retrieve the most relevant context from our database. A vector database provides efficient vector similarity search by providing specialized indexes like k-NN indexes.
Modern Cloud Analytics (MCA) combines the resources, technical expertise, and data knowledge of Tableau, Amazon Web Services (AWS) , and our respective partner networks to help organizations maximize the value of their end-to-end data and analytics investments. Core product integration and connectivity between Tableau and AWS.
Modern Cloud Analytics (MCA) combines the resources, technical expertise, and data knowledge of Tableau, Amazon Web Services (AWS) , and our respective partner networks to help organizations maximize the value of their end-to-end data and analytics investments. Core product integration and connectivity between Tableau and AWS.
This is accomplished through the integration of AWS IAM Identity Center , which serves as the authoritative identity source and validates users. If you haven’t created one yet, refer to Build private and secure enterprise generative AI apps with Amazon Q Business and AWS IAM Identity Center for instructions.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content