This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
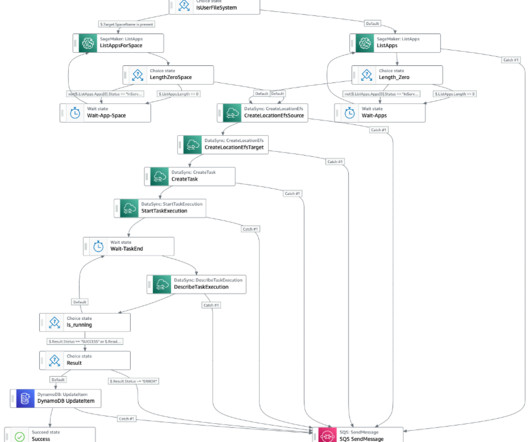
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
These tables house complex domain-specific schemas, with instances of nested tables and multi-dimensional data that require complex database queries and domain-specific knowledge for data retrieval. As a result, NL2SQL solutions for enterprise data are often incomplete or inaccurate.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies and AWS. Solution overview The following diagram provides a high-level overview of AWS services and features through a sample use case.
Agent function calling represents a critical capability for modern AI applications, allowing models to interact with external tools, databases, and APIs by accurately determining when and how to invoke specific functions. You can track these job status details in both the AWS Management Console and AWS SDK.
This engine uses artificial intelligence (AI) and machine learning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. Organizations typically can’t predict their call patterns, so the solution relies on AWS serverless services to scale during busy times.
Traditionally, RAG systems were text-centric, retrieving information from large text databases to provide relevant context for language models. First, it enables you to include both image and text features in a single database and therefore reduces complexity. You may be prompted to subscribe to this model through AWS Marketplace.
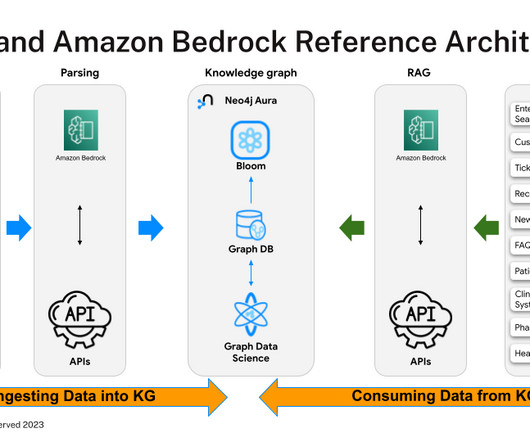
Graph database company Neo4j Inc. said today it’s embarking on a multiyear strategic collaboration with the cloud computing giant Amazon Web Services …
SageMaker Unified Studio combines various AWS services, including Amazon Bedrock , Amazon SageMaker , Amazon Redshift , Amazon Glue , Amazon Athena , and Amazon Managed Workflows for Apache Airflow (MWAA) , into a comprehensive data and AI development platform. Navigate to the AWS Secrets Manager console and find the secret -api-keys.
Amazon Bedrock is a fully managed service provided by AWS that offers developers access to foundation models (FMs) and the tools to customize them for specific applications. The workflow steps are as follows: AWS Lambda running in your private VPC subnet receives the prompt request from the generative AI application.
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. Pre-built templates tailored to various use cases are included, significantly enhancing both employee and customer experiences.
Amazon AWS, the cloud computing giant, has been perceived as playing catch-up with its rivals Microsoft Azure and Google Cloud in the emerging and exciting field of generative AI. But this week, at its annual AWS Re:Invent conference, Amazon plans to showcase its ambitious vision for generative AI, …
Technical challenges with multi-modal data further include the complexity of integrating and modeling different data types, the difficulty of combining data from multiple modalities (text, images, audio, video), and the need for advanced computerscience skills and sophisticated analysis tools.
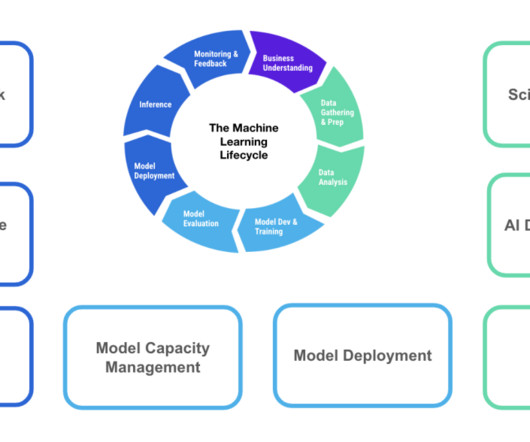
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post. It uses managed AWS services like SageMaker and Amazon Bedrock to enable the entire ML lifecycle. This post is co-authored by Jay Kshirsagar and Ronald Quan from Qualtrics.
By automating document ingestion, chunking, and embedding, it eliminates the need to manually set up complex vector databases or custom retrieval systems, significantly reducing development complexity and time. The solution’s scalability quickly accommodates growing data volumes and user queries thanks to AWS serverless offerings.
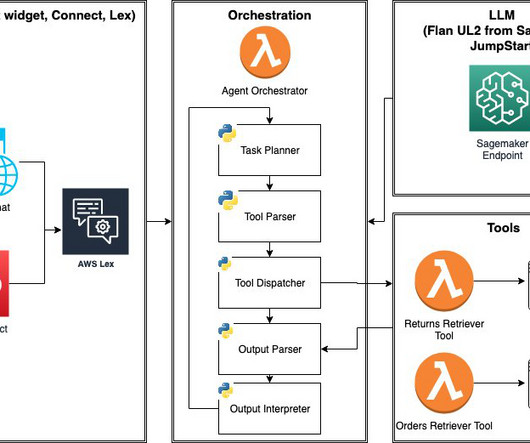
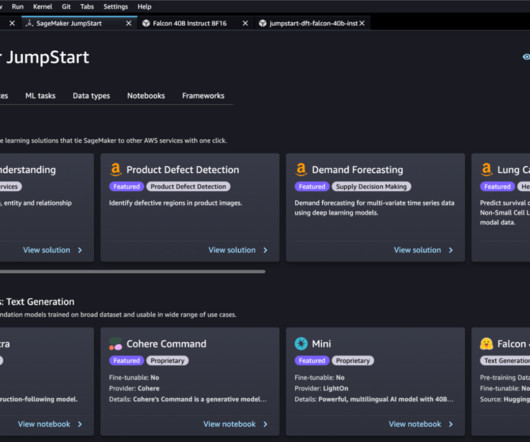
Often, LLMs need to interact with other software, databases, or APIs to accomplish complex tasks. In this post, we introduce LLM agents and demonstrate how to build and deploy an e-commerce LLM agent using Amazon SageMaker JumpStart and AWS Lambda. Next, we show how to implement a simple agent loop using AWS services.
In this two-part series, we demonstrate how you can deploy a cloud-based FL framework on AWS. In the second post , we present the use cases and dataset to show its effectiveness in analyzing real-world healthcare datasets, such as the eICU data , which comprises a multi-center critical care database collected from over 200 hospitals.
In this post, we show you how SnapLogic , an AWS customer, used Amazon Bedrock to power their SnapGPT product through automated creation of these complex DSL artifacts from human language. SnapLogic background SnapLogic is an AWS customer on a mission to bring enterprise automation to the world.
run_opensearch.sh Running OpenSearch Locally A script to start OpenSearch using Docker for local testing before deploying to AWS. Register the Sentence Transformer model in AWS OpenSearch: AWS users must ensure that OpenSearch can access the model before indexing. These can be used for evaluation and comparison.
To mitigate these challenges, we propose a federated learning (FL) framework, based on open-source FedML on AWS, which enables analyzing sensitive HCLS data. In this two-part series, we demonstrate how you can deploy a cloud-based FL framework on AWS. In the first post , we described FL concepts and the FedML framework.
Building a production-ready solution in AWS involves a series of trade-offs between resources, time, customer expectation, and business outcome. The AWS Well-Architected Framework helps you understand the benefits and risks of decisions you make while building workloads on AWS.
The customer review analysis workflow consists of the following steps: A user uploads a file to dedicated data repository within your Amazon Simple Storage Service (Amazon S3) data lake, invoking the processing using AWS Step Functions. In the first step, an AWS Lambda function reads and validates the file, and extracts the raw data.
Instead of relying solely on their pre-trained knowledge, RAG allows models to pull data from documents, databases, and more. This means that as new data becomes available, it can be added to the retrieval database without needing to retrain the entire model. Prerequisites You must have the following prerequisites: An AWS account.
This post shows you how to set up RAG using DeepSeek-R1 on Amazon SageMaker with an OpenSearch Service vector database as the knowledge base. You will execute scripts to create an AWS Identity and Access Management (IAM) role for invoking SageMaker, and a role for your user to create a connector to SageMaker.
With the rapid growth of generative artificial intelligence (AI), many AWS customers are looking to take advantage of publicly available foundation models (FMs) and technologies. This democratizes access to generative AI and improves efficiency in writing complex queries without needing to learn SQL or understand complex database schemas.
This post is a follow-up to Generative AI and multi-modal agents in AWS: The key to unlocking new value in financial markets. Action groups – Action groups are interfaces that an agent uses to interact with the different underlying components such as APIs and databases.
Despite the existence of AWS Application Discovery Service or the presence of some form of configuration management database (CMDB), customers still face many challenges. Customization and adaptability : Action groups allow users to customize migration workflows to suit specific AWS environments and requirements.
Our solution provides practical guidance on addressing this challenge by using a generative AI assistant on AWS. The approach uses Retrieval Augmented Generation (RAG) , which combines text generation capabilities with database querying to provide contextually relevant responses to customer inquiries.
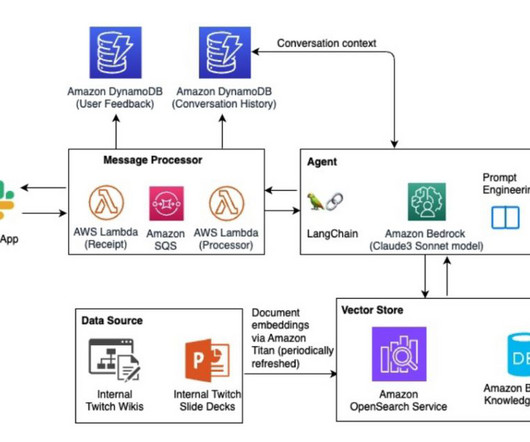
This content is then transformed into a vector database optimized for efficient information retrieval. In the RAG pipeline, the retriever taps into this vector database to surface relevant information, and the LLM generates tailored responses to Twitch user queries submitted through a Slack assistant.
This post provides an overview of a custom solution developed by the AWS Generative AI Innovation Center (GenAIIC) for Deltek , a globally recognized standard for project-based businesses in both government contracting and professional services. It uses a vector database structure to efficiently store and query large volumes of data.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Prerequisites To continue with the examples in this post, you need to create the required AWS resources.
In this post, we show you how Amazon Web Services (AWS) helps in solving forecasting challenges by customizing machine learning (ML) models for forecasting. In this post, we access Amazon SageMaker Canvas through the AWS console. About the Authors Aditya Pendyala is a Principal Solutions Architect at AWS based out of NYC.
The application sends the user query to the vector database to find similar documents. The QnA application submits a request to the SageMaker JumpStart model endpoint with the user query and context returned from the vector database. Basic familiarity with SageMaker and AWS services that support LLMs.
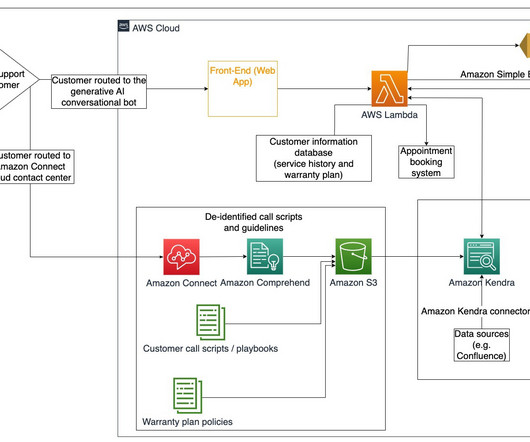
This post takes you through the most common challenges that customers face when searching internal documents, and gives you concrete guidance on how AWS services can be used to create a generative AI conversational bot that makes internal information more useful. The web application front-end is hosted on AWS Amplify.
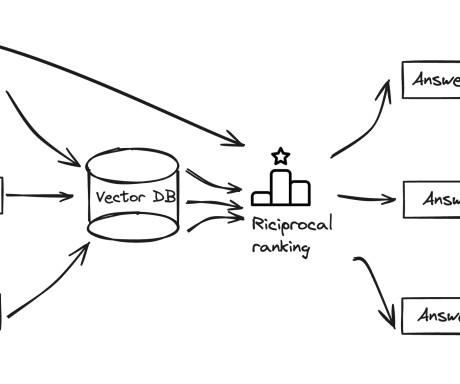
The final retrieval augmentation workflow covers the following high-level steps: The user query is used for a retriever component, which does a vector search, to retrieve the most relevant context from our database. A vector database provides efficient vector similarity search by providing specialized indexes like k-NN indexes.
Moreover, as of November 2022, Studio supports shared spaces to accelerate real-time collaboration and multiple Amazon SageMaker domains in a single AWS Region for each account. First, we demonstrate how to perform backup and recovery if you create a new Studio domain, user, and space profiles using AWS CloudFormation templates.
Browse to locate loan dataset from the Snowflake database Select the two loans datasets by dragging and dropping them from the left side of the screen to the right. For more information on how to accelerate your journeys from data to business insights, see SageMaker Canvas immersion day and AWS user guide. Product Manager at AWS.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB.
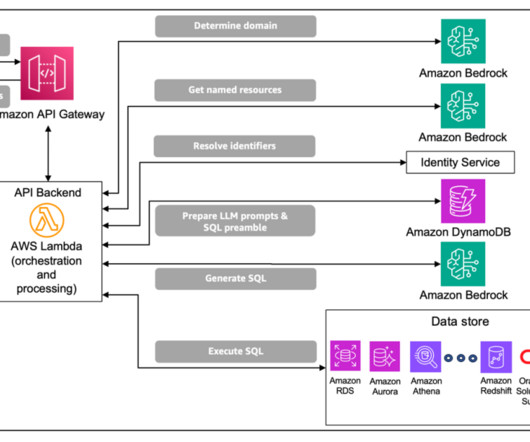
In this post, we discuss how CCC Intelligent Solutions (CCC) combined Amazon SageMaker with other AWS services to create a custom solution capable of hosting the types of complex artificial intelligence (AI) models envisioned. Step-by-step solution Step 1 A client makes a request to the AWS API Gateway endpoint.
Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Around this time, industry observers reported NVIDIA’s strategy pivoting from its traditional gaming and graphics focus to moving into scientific computing and data analytics.
Data Science extracts insights and builds predictive models from processed data. Big Data technologies include Hadoop, Spark, and NoSQL databases. Data Science uses Python, R, and machine learning frameworks. This might involve querying databases, scraping websites, accessing APIs, or using existing datasets.
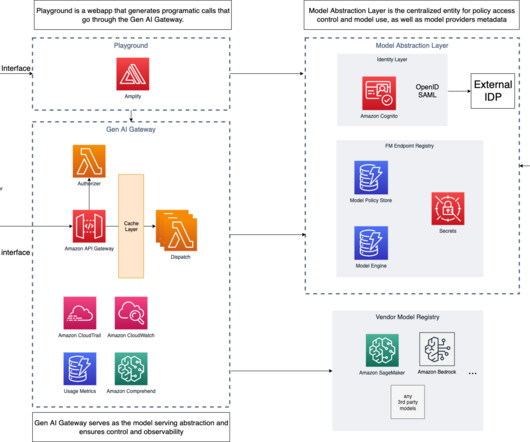
In this post, we define what a Generative AI Gateway is, its benefits, and how to architect one on AWS. AWS services can help in building a model abstraction layer (MAL) as follows: The generative AI manager creates a registry table using Amazon DynamoDB. Finally, a retroactive audit is available through AWS CloudTrail.
Solution architecture The mmRAG solution is based on a straightforward concept: to extract different data types separately, you generate text summarization using a VLM from different data types, embed text summaries along with raw data accordingly to a vector database, and store raw unstructured data in a document store.
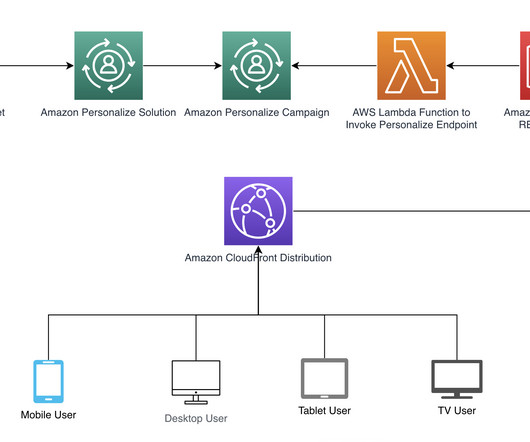
Automatically deriving context is achieved through Amazon CloudFront headers that are included in requests such as a REST API in Amazon API Gateway that calls an AWS Lambda function to retrieve recommendations. We provide a AWS CloudFormation template to create the necessary resources.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















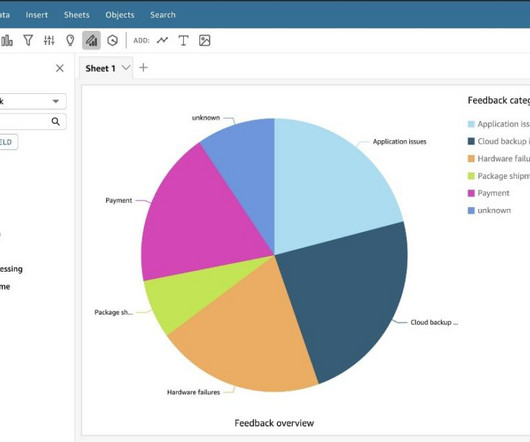
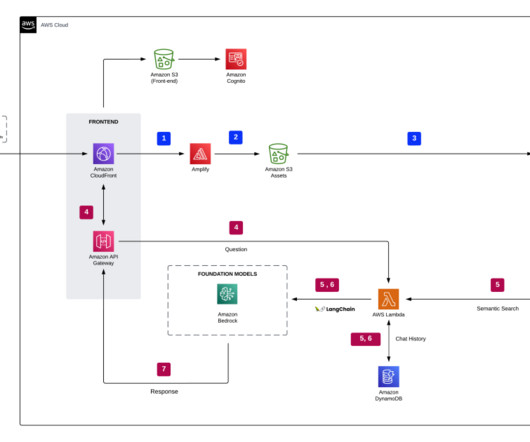


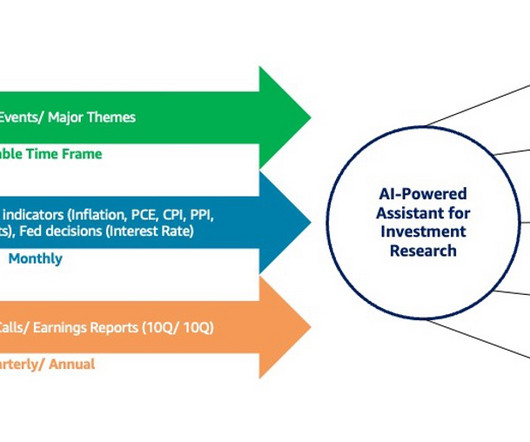

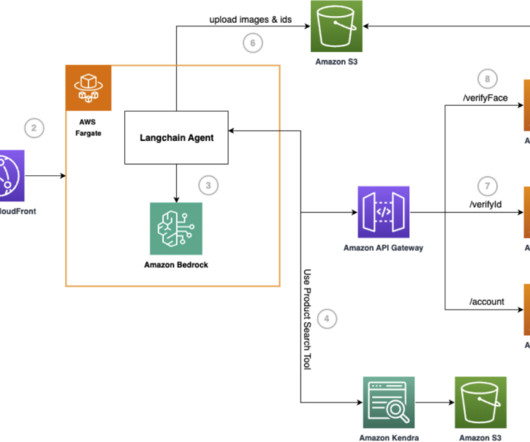














Let's personalize your content