
How Carrier predicts HVAC faults using AWS Glue and Amazon SageMaker
AWS Machine Learning Blog
SEPTEMBER 5, 2023
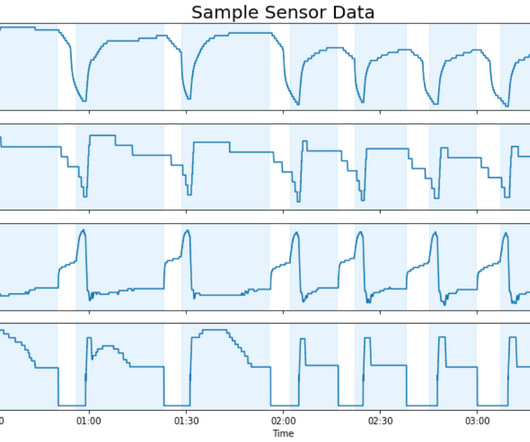
In this post, we show how the Carrier and AWS teams applied ML to predict faults across large fleets of equipment using a single model. We first highlight how we use AWS Glue for highly parallel data processing. This dramatically reduces the size of data while capturing features that characterize the equipment’s behavior.













Let's personalize your content