

How Rocket Companies modernized their data science solution on AWS
AWS Machine Learning Blog
FEBRUARY 21, 2025
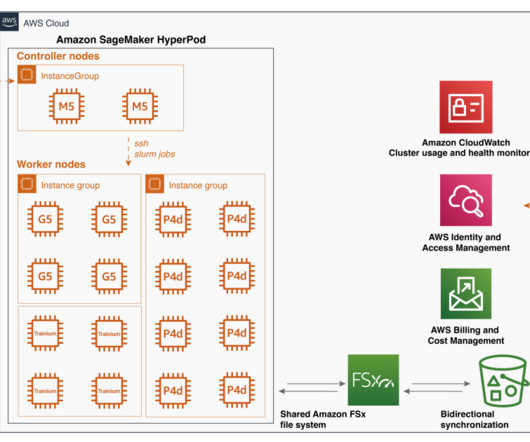
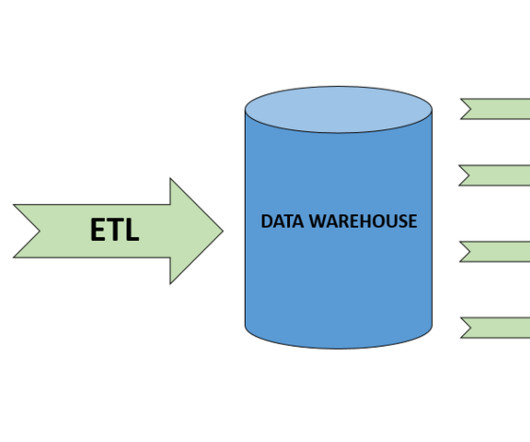
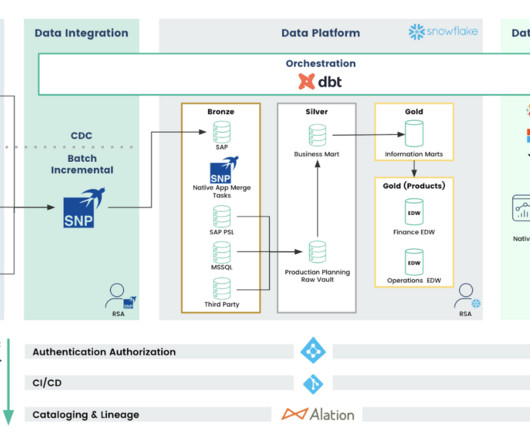
The Hadoop environment was hosted on Amazon Elastic Compute Cloud (Amazon EC2) servers, managed in-house by Rockets technology team, while the data science experience infrastructure was hosted on premises. Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink.






























Let's personalize your content