This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
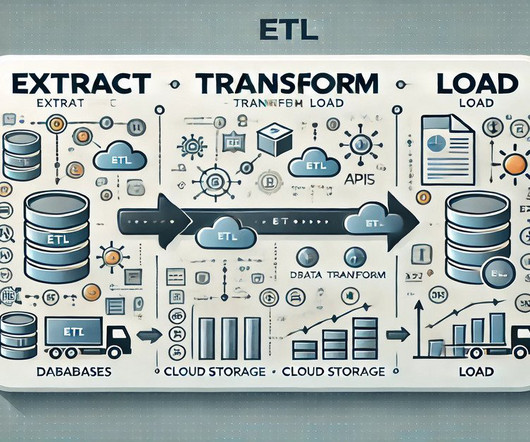
This article was published as a part of the Data Science Blogathon. Introduction ETL is the process that extracts the data from various data sources, transforms the collected data, and loads that data into a common data repository. AzureData Factory […].
Introduction Integrating data proficiently is crucial in today’s era of data-driven decision-making. AzureData Factory (ADF) is a pivotal solution for orchestrating this integration. What is AzureData Factory […] The post What is AzureData Factory (ADF)?
Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier. What is an ETL datapipeline in ML? Datapipelines often run real-time processing.
Together with Azure by Microsoft, and Google Cloud Platform from Google, AWS is one of the three mousquetters of Cloud based platforms, and a solution that many businesses use in their day to day. That’s where Amazon Web Services shines, offering a comprehensive suite of tools that simplify the entire process.
Cloud Computing, APIs, and Data Engineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. Data Engineering Platforms Spark is still the leader for datapipelines but other platforms are gaining ground. Google Cloud is starting to make a name for itself as well.
The global Big Data and Data Engineering Services market, valued at USD 51,761.6 This article explores the key fundamentals of Data Engineering, highlighting its significance and providing a roadmap for professionals seeking to excel in this vital field. What is Data Engineering? million by 2028. from 2025 to 2030.
To provide you with a comprehensive overview, this article explores the key players in the MLOps and FMOps (or LLMOps) ecosystems, encompassing both open-source and closed-source tools, with a focus on highlighting their key features and contributions. It could help you detect and prevent datapipeline failures, data drift, and anomalies.
Cloud Services The only two to make multiple lists were Amazon Web Services (AWS) and Microsoft Azure. Most major companies are using one of the two, so excelling in one or the other will help any aspiring data scientist. Saturn Cloud is picking up a lot of momentum lately too thanks to its scalability.
Originally posted on OpenDataScience.com Read more data science articles on OpenDataScience.com , including tutorials and guides from beginner to advanced levels! Register now before ticket prices go up ! Subscribe to our weekly newsletter here and receive the latest news every Thursday.
This individual is responsible for building and maintaining the infrastructure that stores and processes data; the kinds of data can be diverse, but most commonly it will be structured and unstructured data. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable.
If using a network policy with Snowflake, be sure to add Fivetran’s IP address list , which will ensure AzureData Factory (ADF) AzureData Factory is a fully managed, serverless data integration service built by Microsoft. Source data formats can only be Parquer, JSON, or Delimited Text (CSV, TSV, etc.).
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Big Data Processing: Apache Hadoop, Apache Spark, etc.
Introduction In today’s hyper-connected world, you hear the terms “Big Data” and “Data Science” thrown around constantly. They pop up in news articles, job descriptions, and tech discussions. What exactly is Big Data? It can be confusing!
Apache Kafka For data engineers dealing with real-time data, Apache Kafka is a game-changer. This open-source streaming platform enables the handling of high-throughput data feeds, ensuring that datapipelines are efficient, reliable, and capable of handling massive volumes of data in real-time.
There are many platforms and sources that generate this kind of data. In this article, we will go through the basics of streaming data, what it is, and how it differs from traditional data. We will also get familiar with tools that can help record this data and further analyse it.
This article was co-written by Mayank Singh & Ayush Kumar Singh Your organization’s datapipelines will inevitably run into issues, ranging from simple permission errors to significant network or infrastructure incidents. Failed Webhooks If webhooks are configured and the webhook event fails, a notification will be sent out.
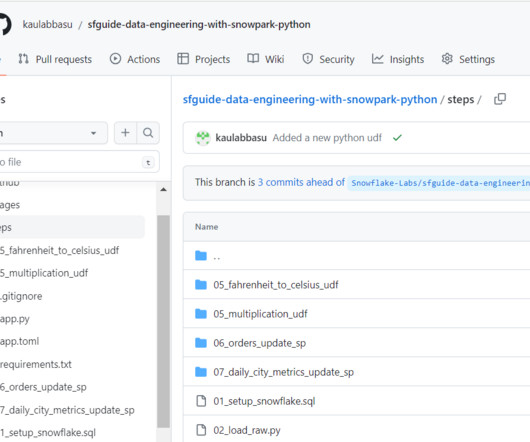
Developers can seamlessly build datapipelines, ML models, and data applications with User-Defined Functions and Stored Procedures. You can set up your own environment in your local system and then check in/deploy the code back to Snowflake using Snowpark (more on this later in the article).
The right ETL platform ensures data flows seamlessly across systems, providing accurate and consistent information for decision-making. Effective integration is crucial to maintaining operational efficiency and data accuracy, as modern businesses handle vast amounts of data. What is ETL in Data Integration?
Increase your productivity in software development with Generative AI As I mentioned in Generative AI use case article, we are seeing AI-assisted developers. I include some reference for this field in that article, but as time goes by, it is necessary to dedicate a particular article to survey this field in-depth.
As data is the foundation of any machine learning project, it is essential to have a system in place for tracking and managing changes to data over time. However, data versioning control is frequently given little attention, leading to issues such as data inconsistencies and the inability to reproduce results.
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
We are going to discuss all of them later in this article. In this article, you will delve into the key principles and practices of MLOps, and examine the essential MLOps tools and technologies that underpin its implementation. Conclusion After reading this article, you now know about MLOps and its role in the machine learning space.
In this article, you’ll discover what a Snowflake data warehouse is, its pros and cons, and how to employ it efficiently. The platform enables quick, flexible, and convenient options for storing, processing, and analyzing data. What makes Snowflake so unique, and are there any caveats to it?
Managing unstructured data is essential for the success of machine learning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. This article will discuss managing unstructured data for AI and ML projects. How to properly manage unstructured data.
However, in scenarios where dataset versioning solutions are leveraged, there can still be various challenges experienced by ML/AI/Data teams. Data aggregation: Data sources could increase as more data points are required to train ML models. Existing datapipelines will have to be modified to accommodate new data sources.
Get a Demo DATA + AI SUMMIT Data + AI Summit Happening Now Watch the free livestream of the keynotes! This standard simplifies pipeline development across batch and streaming workloads. Years of real-world experience have shaped this flexible, Spark-native approach for both batch and streaming pipelines.
By focusing on measurable solutions: differential privacy techniques to protect user data, bias-mitigation benchmarks to identify gaps, and reproducible tracking with tools like neptune.ai This article isnt just about why ethics matterits about how you can take action now to build trustworthy LLMs. to ensure accountability.
Whether you rely on cloud-based services like Amazon SageMaker , Google Cloud AI Platform, or Azure Machine Learning or have developed your custom ML infrastructure, Comet integrates with your chosen solution. It goes beyond compatibility with open-source solutions and extends its support to managed services and in-house ML platforms.
Learn from the practical experience of four ML teams on collaboration in this article. Data scientists and machine learning engineers need an infrastructure layer that lets them scale their work without having to be networking experts. (in This article defines architecture as the way the highest-level components are wired together.
In this article, you will learn about version control for ML models, and why it is crucial in ML. We will demonstrate how you can use any of these tools in a later section of the article. Data Versioning In ML projects, keeping track of datasets is very important because the data can change over time.
High demand has risen from a range of sectors, including crypto mining, gaming, generic data processing, and AI. An important part of the datapipeline is the production of features, both online and offline. The same WSJ article states “No one alpha is important.
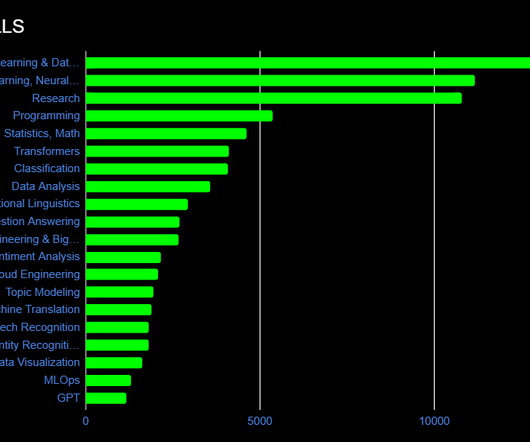
Uncomfortable reality: In the era of large language models (LLMs) and AutoML, traditional skills like Python scripting, SQL, and building predictive models are no longer enough for data scientist to remain competitive in the market. Coding skills remain important, but the real value of data scientists today is shifting. It depends.
Data Analysis and Transition to Machine Learning: Skills: Python, SQL, Excel, Tableau and Power BI are relevant skills for entry-level data analysis roles. Next Steps: Transition into data engineering (PySpark, ETL) or machine learning (TensorFlow, PyTorch). MySQL, PostgreSQL) and non-relational (e.g.,
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content