This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With ML-powered anomaly detection, customers can find outliers in their data without the need for manual analysis, custom development, or ML domain expertise. Using Amazon Glue Data Quality for anomaly detection Dataengineers and analysts can use AWS Glue Data Quality to measure and monitor their data.
General Purpose Tools These tools help manage the unstructured data pipeline to varying degrees, with some encompassing data collection, storage, processing, analysis, and visualization. DagsHub's DataEngine DagsHub's DataEngine is a centralized platform for teams to manage and use their datasets effectively.
Some industries rely not only on traditional data but also need data from sources such as security logs, IoT sensors, and web applications to provide the best customer experience. For example, before any video streaming services, users had to wait for videos or audio to get downloaded.
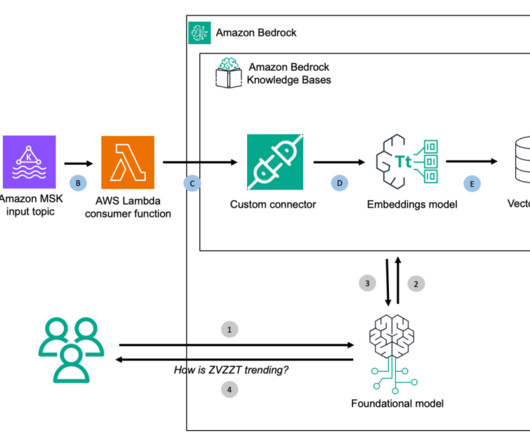
Solution overview: Build a generative AI stock price analyzer with RAG For this post, we implement a RAG architecture with Amazon Bedrock Knowledge Bases using a custom connector and topics built with Amazon Managed Streaming for ApacheKafka (Amazon MSK) for a user who may be interested to understand stock price trends.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










Let's personalize your content