This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction ApacheKafka is a framework for dealing with many real-time data streams in a way that is spread out. It was made on LinkedIn and shared with the public in 2011.
You can safely use an ApacheKafkacluster for seamless data movement from the on-premise hardware solution to the data lake using various cloud services like Amazon’s S3 and others. 5 Key Comparisons in Different ApacheKafka Architectures. 5 Key Comparisons in Different ApacheKafka Architectures.
ApacheKafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. With ApacheKafka, developers can build applications that continuously use streaming data records and deliver real-time experiences to users. How does ApacheKafka work?
ApacheKafka is a well-known open-source event store and stream processing platform and has grown to become the de facto standard for data streaming. ApacheKafka transfers data without validating the information in the messages. Kafka does not examine the metadata of your messages.
However, IBM MQ and ApacheKafka can sometimes be viewed as competitors, taking each other on in terms of speed, availability, cost and skills. MQ and ApacheKafka: Teammates Simply put, they are different technologies with different strengths, albeit often perceived to be quite similar.
This data, often referred to as Big Data , encompasses information from various sources, including social media interactions, online transactions, sensor data, and more. Clusters : Clusters are groups of interconnected nodes that work together to process and store data.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
They often use ApacheKafka as an open technology and the de facto standard for accessing events from a various core systems and applications. IBM provides an Event Streams capability build on ApacheKafka that makes events manageable across an entire enterprise.
Leveraging real-time analytics to make informed decisions is the golden standard for virtually every business that collects data. What is ApacheKafka, and How is it Used in Building Real-time Data Pipelines? ApacheKafka is an open-source event distribution platform. Example: openssl rsa -in C:tmpnew_rsa_key_v1.p8
Wednesday, June 14th Me, my health, and AI: applications in medical diagnostics and prognostics: Sara Khalid | Associate Professor, Senior Research Fellow, Biomedical Data Science and Health Informatics | University of Oxford Iterated and Exponentially Weighted Moving Principal Component Analysis : Dr. Paul A.
ApacheKafka is a high-performance, highly scalable event streaming platform. To unlock Kafka’s full potential, you need to carefully consider the design of your application. It’s all too easy to write Kafka applications that perform poorly or eventually hit a scalability brick wall. So, what can you do?
In recognizing the benefits of event-driven architectures, many companies have turned to ApacheKafka for their event streaming needs. ApacheKafka enables scalable, fault-tolerant and real-time processing of streams of data—but how do you manage and properly utilize the sheer amount of data your business ingests every second?
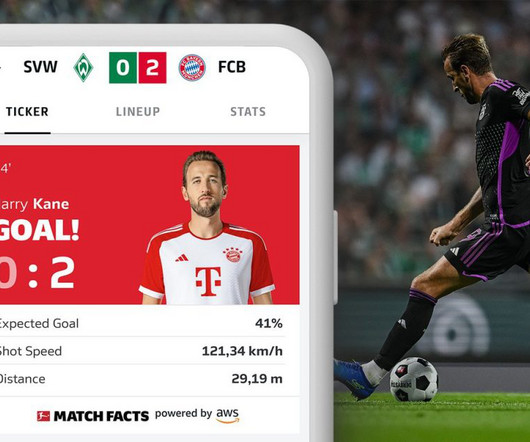
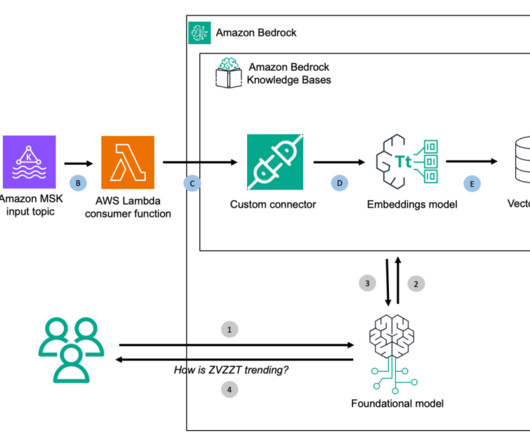
m How it’s implemented In our quest to accurately determine shot speed during live matches, we’ve implemented a cutting-edge solution using Amazon Managed Streaming for ApacheKafka (Amazon MSK). Simultaneously, the shot speed data finds its way to a designated topic within our MSK cluster. km/h with a distance to goal of 20.61
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Processing frameworks like Hadoop enable efficient data analysis across clusters. Data lakes and cloud storage provide scalable solutions for large datasets.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Processing frameworks like Hadoop enable efficient data analysis across clusters. Data lakes and cloud storage provide scalable solutions for large datasets.
This involves working closely with data analysts and data scientists to ensure that data is stored, processed, and analyzed efficiently to derive insights that inform decision-making. With the rise of big data, data engineering has become critical for organizations looking to make sense of the vast amounts of information at their disposal.
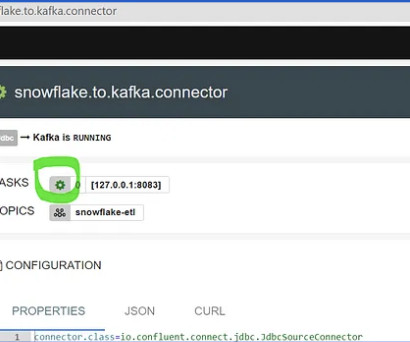
The data is then transformed to fit a common data model that includes patient demographic information, clinical data, and patient satisfaction scores. The events can be published to a message broker such as ApacheKafka or Google Cloud Pub/Sub. Here’s a high-level overview of how the MapReduce pattern works: A.
The goal is to ensure that data is available, reliable, and accessible for analysis, ultimately driving insights and informed decision-making within organisations. Their work ensures that data flows seamlessly through the organisation, making it easier for Data Scientists and Analysts to access and analyse information.
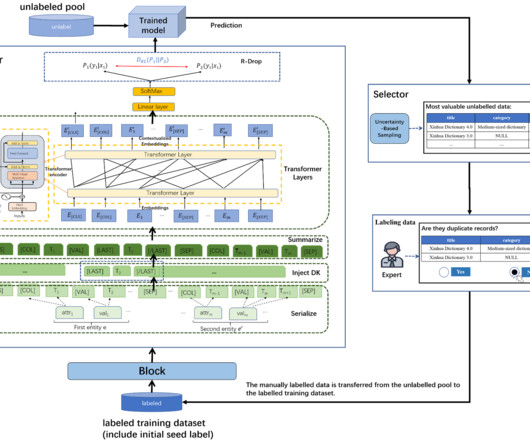
Clustering: Clustering can group texts using features like embedding vectors or TF-IDF vectors. Duplicate texts naturally tend to fall into the same clusters. Unsupervised algorithms like K-Means clustering, DBSCAN are prevalently used to create the text clusters. imshow(original_image) axes[0].set_title('Original
One thing is clear : unstructured data doesn’t mean it lacks information. All forms of data must have some form of information, or else they won’t be considered data. Here’s the structured equivalent of this same data in tabular form: With structured data, you can use query languages like SQL to extract and interpret information.
Organisations must develop strategies to store and manage this vast amount of information effectively. Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers.
Before you start looking into the specific tools, you can find a summary table containing the most important information on the covered orchestration tool. Also, while it is not a streaming solution, we can still use it for such a purpose if combined with systems such as ApacheKafka. This removes the need for complex CI/CD.
Overview In the era of Big Data , organizations inundated with vast amounts of information generated from various sources. Apache NiFi, an open-source data ingestion and distribution platform, has emerged as a powerful tool designed to automate the flow of data between systems.
Real-time Data Stream Analysis: Use Python with libraries like ApacheKafka and Apache Spark to process and analyze real-time data streams from sources like Twitter, sensors, or website logs. Pricing Management: To improve product price plans, analyze pricing information, rival pricing, and consumer behavior.
Automating myriad steps associated with pipeline data processing, helps you convert the data from its raw shape and format to a meaningful set of information that is used to drive business decisions. Server update locks the entire cluster. This is what data processing pipelines do for you. It supports multiple file formats.
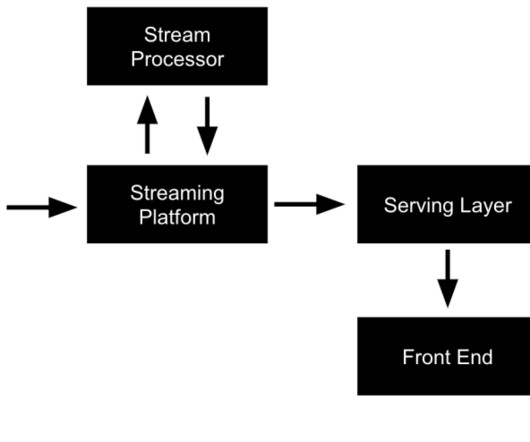
Building a Business with a Real-Time Analytics Stack, Streaming ML Without a Data Lake, and Google’s PaLM 2 Building a Pizza Delivery Service with a Real-Time Analytics Stack The best businesses react quickly and with informed decisions. Here’s a use case of how you can use a real-time analytics stack to build a pizza delivery service.
ApacheKafka, Amazon Kinesis) 2 Data Preprocessing (e.g., They also act as a data representation form that retains the key information, patterns, and features, providing a lower-dimensional representation of high-dimensional data that retains key patterns and information. 1 Data Ingestion (e.g.,
Retrieval Augmented Generation (RAG) enhances AI responses by combining the generative AI models capabilities with information from external data sources, rather than relying solely on the models built-in knowledge. The next step is to use a SageMaker Studio terminal instance to connect to the MSK cluster and create the test stream topic.
Introduction to Big Data Tools In todays data-driven world, organisations are inundated with vast amounts of information generated from various sources, including social media, IoT devices, transactions, and more. Big Data tools are essential for effectively managing and analysing this wealth of information.
They act as a middleman, helping different systems exchange information smoothly. Two of the most popular message brokers are RabbitMQ and ApacheKafka. In this blog, we will explore RabbitMQ vs Kafka, their key differences, and when to use each. Thats where message brokers come in. Where is RabbitMQ Used?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content