This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post Introduction to ApacheKafka: Fundamentals and Working appeared first on Analytics Vidhya. Introduction Have you ever wondered how Instagram recommends similar kinds of reels while you are scrolling through your feed or ad recommendations for similar products that you were browsing on Amazon?
Introduction ApacheKafka is an open-source publish-subscribe messaging application initially developed by LinkedIn in early 2011. It is a famous Scala-coded data processing tool that offers low latency, extensive throughput, and a unified platform to handle the data in real-time.
The generation and accumulation of vast amounts of data have become a defining characteristic of our world. This data, often referred to as BigData , encompasses information from various sources, including social media interactions, online transactions, sensor data, and more. databases), semi-structured data (e.g.,
ApacheKafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. With ApacheKafka, developers can build applications that continuously use streaming data records and deliver real-time experiences to users. How does ApacheKafka work?
Data engineers play a crucial role in managing and processing bigdata. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. They must also ensure that data privacy regulations, such as GDPR and CCPA , are followed.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. It utilises the Hadoop Distributed File System (HDFS) and MapReduce for efficient data management, enabling organisations to perform bigdata analytics and gain valuable insights from their data.
Summary: This article provides a comprehensive guide on BigData interview questions, covering beginner to advanced topics. Introduction BigData continues transforming industries, making it a vital asset in 2025. The global BigData Analytics market, valued at $307.51 What is BigData?
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
Summary: BigData encompasses vast amounts of structured and unstructured data from various sources. Key components include data storage solutions, processing frameworks, analytics tools, and governance practices. Key Takeaways BigData originates from diverse sources, including IoT and social media.
Summary: BigData encompasses vast amounts of structured and unstructured data from various sources. Key components include data storage solutions, processing frameworks, analytics tools, and governance practices. Key Takeaways BigData originates from diverse sources, including IoT and social media.
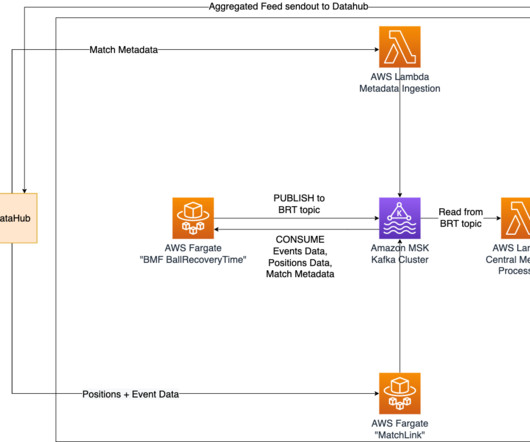
How it’s implemented Positional data from an ongoing match, which is recorded at a sampling rate of 25 Hz, is utilized to determine the time taken to recover the ball. This allows for seamless communication of positional data and various outputs of Bundesliga Match Facts between containers in real time.
The session participants will learn the theory behind compound sparsity, state-of-the-art techniques, and how to apply it in practice using the Neural Magic platform.
Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation. With a user-friendly interface and robust features, NiFi simplifies complex data workflows and enhances real-time data integration.
The events can be published to a message broker such as ApacheKafka or Google Cloud Pub/Sub. The message broker can then distribute the events to various subscribers such as data processing pipelines, machine learning models, and real-time analytics dashboards. Here’s a high-level overview of how the MapReduce pattern works: A.
Defining clear objectives and selecting appropriate techniques to extract valuable insights from the data is essential. Here are some project ideas suitable for students interested in bigdata analytics with Python: 1. Implement real-time analytics to monitor trends or anomalies in the data.
Introduction Data Engineering is the backbone of the data-driven world, transforming raw data into actionable insights. As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. million by 2028.
Data Lakes Data lakes are centralized repositories designed to store vast amounts of raw, unstructured, and structured data in their native format. They enable flexible data storage and retrieval for diverse use cases, making them highly scalable for bigdata applications.
Listed below are some of the common types of data pipeline tools: Commercial vs open-source data pipeline tools When a business needs full control over the development process and wants to build highly customizable complex solutions, open-source tools come in handy. No built-in data quality functionality. No expert support.
1 Data Ingestion (e.g., ApacheKafka, Amazon Kinesis) 2 Data Preprocessing (e.g., Embeddings provide a lower-dimensional representation of high-dimensional data that retains key patterns and information. Other areas in ML pipelines: transfer learning, anomaly detection, vector similarity search, clustering, etc.
Summary: BigData tools empower organizations to analyze vast datasets, leading to improved decision-making and operational efficiency. Ultimately, leveraging BigData analytics provides a competitive advantage and drives innovation across various industries.
Choosing between them depends on your systems needsRabbitMQ is best for workflows, while Kafka is ideal for event-driven architectures and bigdata processing. Two of the most popular message brokers are RabbitMQ and ApacheKafka. Kafka excels in real-time data streaming and scalability.
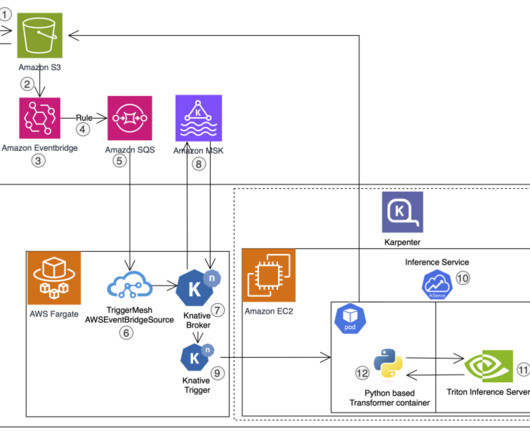
For the time being, we use Amazon EKS to offload the management overhead to AWS, but we could easily deploy on a standard Kubernetes cluster if needed. The resources in the Kubernetes cluster are deployed in a private subnet. It is backed by Amazon Managed Streaming for ApacheKafka (Amazon MSK) (8).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content