This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datapipelines are essential in our increasingly data-driven world, enabling organizations to automate the flow of information from diverse sources to analytical platforms. What are datapipelines? Purpose of a datapipelineDatapipelines serve various essential functions within an organization.
Artificial intelligence (AI) and natural language processing (NLP) technologies are evolving rapidly to manage live data streams. They power everything from chatbots and predictive analytics to dynamic content creation and personalized recommendations.
Complex Event Processing (CEP) is at the forefront of modern analytics, enabling organizations to extract valuable insights from vast streams of real-time data. As industries evolve, the ability to process and respond to events in the moment becomes mission-critical. What is Complex Event Processing (CEP)?
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
Microsoft Fabric aims to reduce unnecessary data replication, centralize storage, and create a unified environment with its unique data fabric method. Microsoft Fabric is a cutting-edge analytics platform that helps data experts and companies work together on data projects. What is Microsoft Fabric?
The concept of streaming data was born of necessity. More than ever, advanced analytics, ML, and AI are providing the foundation for innovation, efficiency, and profitability. But insights derived from day-old data don’t cut it. Business success is based on how we use continuously changing data.
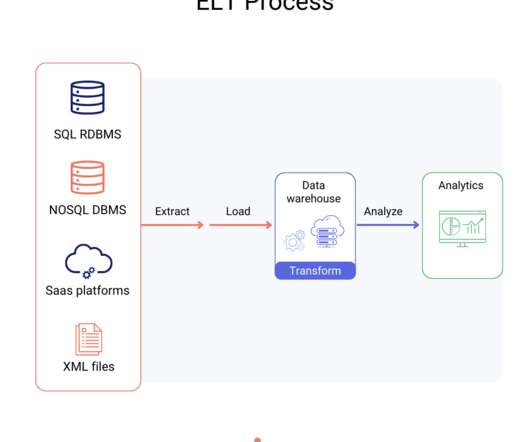
An ELT pipeline is a datapipeline that extracts (E) data from a source, loads (L) the data into a destination, and then transforms (T) data after it has been stored in the destination. If you can’t import all your data, you may only have a partial picture of your business.
Through simple conversations, business teams can use the chat agent to extract valuable insights from both structured and unstructured data sources without writing code or managing complex datapipelines. This will provision the backend infrastructure and services that the sales analytics application will rely on.
Though you may encounter the terms “data science” and “dataanalytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, dataanalytics is the act of examining datasets to extract value and find answers to specific questions.
Hosted at one of Mindspace’s coworking locations, the event was a convergence of insightful talks and professional networking. Mindspace , a global coworking and flexible office provider with over 45 locations worldwide, including 13 in Germany, offered a conducive environment for this knowledge-sharing event.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
Six core principles of a realtime streaming pipeline Drawing on Matus Tomleins stepbystep Implementation Guide: Building an AIReady DataPipeline Architecture , you can anchor any streaming stack around six nonnegotiables: Explicit data requirements. Schemafirst design. Robust ingestion. Duallayer storage.
Data Observability and Monitoring Data observability is the ability to monitor and troubleshoot datapipelines. Data monitoring is the process of collecting and analyzing data about datapipelines to identify and resolve problems. Interested in attending an ODSC event?
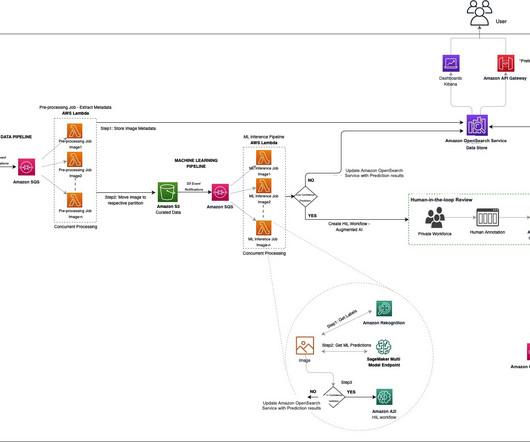
Solution overview In brief, the solution involved building three pipelines: Datapipeline – Extracts the metadata of the images Machine learning pipeline – Classifies and labels images Human-in-the-loop review pipeline – Uses a human team to review results The following diagram illustrates the solution architecture.
The following diagram illustrates the datapipeline for indexing and query in the foundational search architecture. The listing writer microservice publishes listing change events to an Amazon Simple Notification Service (Amazon SNS) topic, which an Amazon Simple Queue Service (Amazon SQS) queue subscribes to.
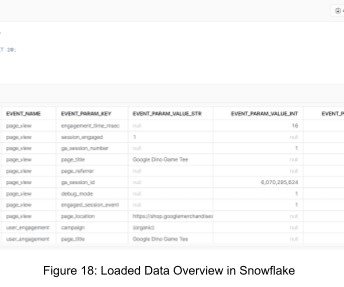
Google Analytics 4 (GA4) is a powerful tool for collecting and analyzing website and app data that many businesses rely heavily on to make informed business decisions. However, there might be instances where you need to migrate the raw eventdata from GA4 to Snowflake for more in-depth analysis and business intelligence purposes.
If the question was Whats the schedule for AWS events in December?, AWS usually announces the dates for their upcoming # re:Invent event around 6-9 months in advance. Rajesh Nedunuri is a Senior Data Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team.
Retailers are also dealing with online shopping surges that add new complexities to existing data strategies due to an influx of raw, unprepped, and largely underutilized data. . Analytics agility is a competitive advantage in retail today—and it will be table stakes for retail success tomorrow. What is a modern data stack?
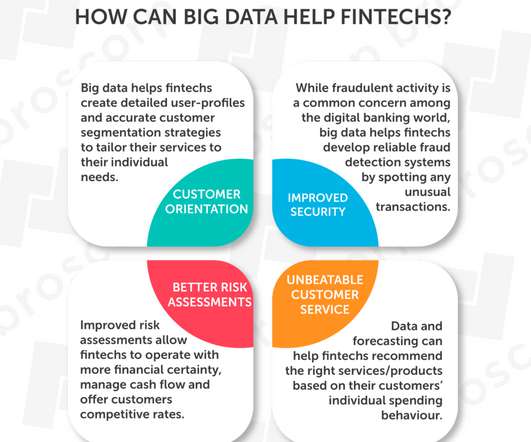
billion on financial analytics by 2030. And Big Data is one such excellent opportunity ! Big Data is the collection and processing of huge volumes of different data types, which financial institutions use to gain insights into their business processes and make key company decisions. Improving Risk Assessment.
This post is co-written with Suhyoung Kim, General Manager at KakaoGames DataAnalytics Lab. The result of these events can be evaluated afterwards so that they make better decisions in the future. With this proactive approach, Kakao Games can launch the right events at the right time. However, this approach is reactive.
In this post we highlight how the AWS Generative AI Innovation Center collaborated with the AWS Professional Services and PGA TOUR to develop a prototype virtual assistant using Amazon Bedrock that could enable fans to extract information about any event, player, hole or shot level details in a seamless interactive manner.
Leveraging real-time analytics to make informed decisions is the golden standard for virtually every business that collects data. If you have the Snowflake Data Cloud (or are considering migrating to Snowflake ), you’re a blog away from taking a step closer to real-time analytics.
Whereas AIOps is a comprehensive discipline that includes a variety of analytics and AI initiatives that are aimed at optimizing IT operations, MLOps is specifically concerned with the operational aspects of ML models, promoting efficient deployment, monitoring and maintenance.
Apache Kafka and Apache Flink working together Anyone who is familiar with the stream processing ecosystem is familiar with Apache Kafka: the de-facto enterprise standard for open-source event streaming. Apache Kafka streams get data to where it needs to go, but these capabilities are not maximized when Apache Kafka is deployed in isolation.
— Features In machine learning, a feature is data that is used as the input for ML models to make predictions. Source: Advancing AnalyticsData scientists and data engineers often spend a large amount of their time crafting features, as they are the basic building blocks of datasets. Spark, Flink, etc.)
Data Engineering : Building and maintaining datapipelines, ETL (Extract, Transform, Load) processes, and data warehousing. Career Support Some bootcamps include job placement services like resume assistance, mock interviews, networking events, and partnerships with employers to aid in job placement.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
Whether logs are coming from Amazon Web Services (AWS), other cloud providers, on-premises, or edge devices, customers need to centralize and standardize security data. After the security log data is stored in Amazon Security Lake, the question becomes how to analyze it. Deploy the trained ML model to a SageMaker inference endpoint.
Kafka And ETL Processing: You might be using Apache Kafka for high-performance datapipelines, stream various analyticsdata, or run company critical assets using Kafka, but did you know that you can also use Kafka clusters to move data between multiple systems.
That means feeding them streams of high-quality information about user actions, events, and context in real time. So, what exactly is AI-ready data? Simply put, AI-ready data is structured, high-quality information that can be easily used to train machine learning models and run AI applications with minimal engineering effort .
DataAnalytics in the Age of AI, When to Use RAG, Examples of Data Visualization with D3 and Vega, and ODSC East Selling Out Soon DataAnalytics in the Age of AI Let’s explore the multifaceted ways in which AI is revolutionizing dataanalytics, making it more accessible, efficient, and insightful than ever before.
Apache Kafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. With Apache Kafka, developers can build applications that continuously use streaming data records and deliver real-time experiences to users.
Event-driven businesses across all industries thrive on real-time data, enabling companies to act on events as they happen rather than after the fact. Flink jobs, designed to process continuous data streams, are key to making this possible. They are able to adapt to changing demands quickly to seize new opportunities.
In the later part of this article, we will discuss its importance and how we can use machine learning for streaming data analysis with the help of a hands-on example. What is streaming data? A streaming datapipeline is an enhanced version which is able to handle millions of events in real-time at scale.
Not only does it involve the process of collecting, storing, and processing data so that it can be used for analysis and decision-making, but these professionals are responsible for building and maintaining the infrastructure that makes this possible; and so much more. Think of data engineers as the architects of the data ecosystem.
AWS Lambda is an event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers. Rushikesh Jagtap is a Solutions Architect with 5+ years of experience in AWS Analytics services.
As the name suggests, real-time operating systems (RTOS) handle real-time applications that undertake data and event processing under a strict deadline. For big data to harness these sources, it is important to have the ability to integrate data and make them interoperable across different sources.
In our previous blog, Top 5 Fivetran Connectors for Financial Services , we explored Fivetran’s capabilities that address the data integration needs of the finance industry. Now, let’s cover the healthcare industry, which also has a surging demand for data and analytics, along with the underlying processes to make it happen.
Institute of Analytics The Institute of Analytics is a non-profit organization that provides data science and analytics courses, workshops, certifications, research, and development. The courses and workshops cover a wide range of topics, from basic data science concepts to advanced machine learning techniques.
Retailers are also dealing with online shopping surges that add new complexities to existing data strategies due to an influx of raw, unprepped, and largely underutilized data. . Analytics agility is a competitive advantage in retail today—and it will be table stakes for retail success tomorrow. What is a modern data stack?
Introduction The Formula 1 Prediction Challenge: 2024 Mexican Grand Prix brought together data scientists to tackle one of the most dynamic aspects of racing — pit stop strategies. With every second on the track critical, the challenge showcased how data can shape decisions that define race outcomes.
Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. It involves developing datapipelines that efficiently transport data from various sources to storage solutions and analytical tools. ETL is vital for ensuring data quality and integrity.
Apache Kafka For data engineers dealing with real-time data, Apache Kafka is a game-changer. This open-source streaming platform enables the handling of high-throughput data feeds, ensuring that datapipelines are efficient, reliable, and capable of handling massive volumes of data in real-time.
As a proud member of the Connect with Confluent program , we help organizations going through digital transformation and IT infrastructure modernization break down data silos and power their streaming datapipelines with trusted data. Let’s cover some additional information to know before attending.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























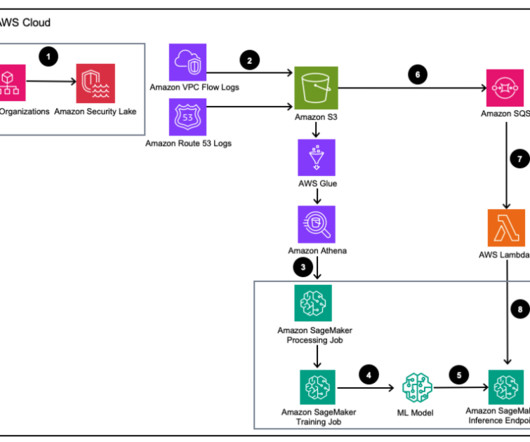



















Let's personalize your content