This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: Associative classification in datamining combines association rule mining with classification for improved predictive accuracy. Despite computational challenges, its interpretability and efficiency make it a valuable technique in data-driven industries. Lets explore each in detail.
Last Updated on August 6, 2024 by Editorial Team Author(s): Stephen Chege-Tierra Insights Originally published on Towards AI. What is K Means Clustering K-Means is an unsupervised machine learning approach that divides the unlabeled dataset into various clusters. The cluster centroid in the space is first randomly assigned.
Summary: Clustering in datamining encounters several challenges that can hinder effective analysis. Key issues include determining the optimal number of clusters, managing high-dimensional data, and addressing sensitivity to noise and outliers. What is Clustering?
Machines, artificial intelligence (AI), and unsupervised learning are reshaping the way businesses vie for a place under the sun. The unsupervised ML algorithms are used to: Find groups or clusters; Perform density estimation; Reduce dimensionality. Overall, unsupervised algorithms get to the point of unspecified data bits.
Meta Description: Discover the key functionalities of datamining, including data cleaning, integration. Summary: Datamining functionalities encompass a wide range of processes, from data cleaning and integration to advanced techniques like classification and clustering.
Accordingly, data collection from numerous sources is essential before data analysis and interpretation. DataMining is typically necessary for analysing large volumes of data by sorting the datasets appropriately. What is DataMining and how is it related to Data Science ? What is DataMining?
Last Updated on February 1, 2024 by Editorial Team Author(s): Towards AI Editorial Team Originally published on Towards AI. This episode is perfect for those curious about how AI is not just a tool but a collaborator in the creative process, transforming traditional art forms and pioneering new expressions of creativity.
By creating backups of the archived data, organizations can ensure that their data is safe and recoverable in case of a disaster or data breach. Databases are the unsung heroes of AI Furthermore, data archiving improves the performance of applications and databases. How can AI help with data archiving?
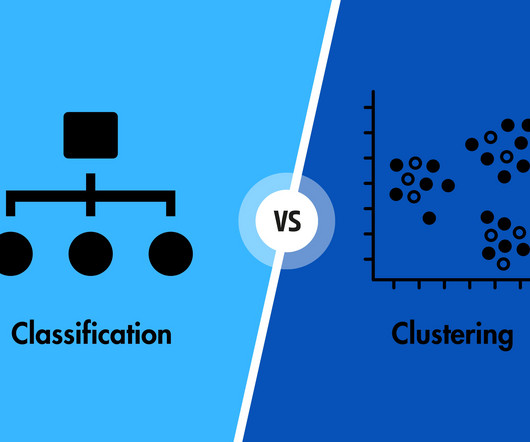
Certainly, these predictions and classification help in uncovering valuable insights in datamining projects. ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. Both the hierarchical clustering and contentious clustering methods are seen as dendrogram.
On own account, we from DATANOMIQ have created a web application that monitors data about job postings related to Data & AI from multiple sources (Indeed.com, Google Jobs, Stepstone.de For DATANOMIQ this is a show-case of the coming Data as a Service ( DaaS ) Business.
Author(s): Jennifer Wales Originally published on Towards AI. TOP 20 AI CERTIFICATIONS TO ENROLL IN 2025 Ramp up your AI career with the most trusted AI certification programs and the latest artificial intelligence skills. Led by AI geniuses Dr. Read on to explore the best 20 courses worldwide.
Data scientists are continuously advancing with AI tools and technologies to enhance their capabilities and drive innovation in 2024. The integration of AI into data science has revolutionized the way data is analyzed, interpreted, and utilized.
This data is then processed, transformed, and consumed to make it easier for users to access it through SQL clients, spreadsheets and Business Intelligence tools. Data warehousing also facilitates easier datamining, which is the identification of patterns within the data which can then be used to drive higher profits and sales.
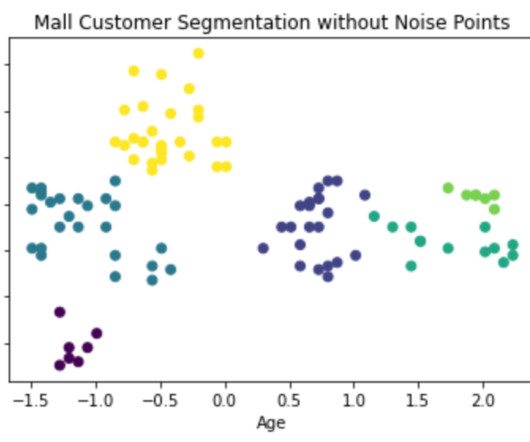
Photo by Aditya Chache on Unsplash DBSCAN in Density Based Algorithms : Density Based Spatial Clustering Of Applications with Noise. Earlier Topics: Since, We have seen centroid based algorithm for clustering like K-Means.Centroid based : K-Means, K-Means ++ , K-Medoids. & One among the many density based algorithms is “DBSCAN”.
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machine learning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves. Fine-tuning is quite easy.
Data science is analyzing and predicting data, It is an emerging field. Some of the applications of data science are driverless cars, gaming AI, movie recommendations, and shopping recommendations. Since the field covers such a vast array of services, data scientists can find a ton of great opportunities in their field.
In the rapidly expanding field of artificial intelligence (AI), machine learning tools play an instrumental role. Already a multi-billion-dollar industry, AI is having a profound impact on every aspect of life, business, and society. These tools are becoming increasingly sophisticated, enabling the development of advanced applications.
Machine Learning is a subset of artificial intelligence (AI) that focuses on developing models and algorithms that train the machine to think and work like a human. It entails developing computer programs that can improve themselves on their own based on expertise or data. It can be either agglomerative or divisive.
At its core, decision intelligence involves collecting and integrating relevant data from various sources, such as databases, text documents, and APIs. This data is then analyzed using statistical methods, machine learning algorithms, and datamining techniques to uncover meaningful patterns and relationships.
Last Updated on March 19, 2023 by Editorial Team Author(s): Chinmay Bhalerao Originally published on Towards AI. Random variable: Statistics and datamining are concerned with data. How do we link sample spaces and events to data? and those chosen people will be sampled from all student's sample space.
Evolutionary computing has been successfully applied to various problem domains, including optimization, machine learning, scheduling, datamining, and many others. These methods explore different cluster configurations and optimize clustering criteria to find the best partitioning of data.
Last Updated on May 9, 2023 by Editorial Team Author(s): Sriram Parthasarathy Originally published on Towards AI. This code can cover a diverse array of tasks, such as creating a KMeans cluster, in which users input their data and ask ChatGPT to generate the relevant code.
Use cases include visualising distributions, relationships, and categorical data, effortlessly enhancing the aesthetics of your plots. It offers simple and efficient tools for datamining and Data Analysis. Scikit-learn covers various classification , regression , clustering , and dimensionality reduction algorithms.
Here, we delve into exciting trends that are shaping the evolution of this powerful technique: Continuous Learning and Adaptation Advancements in machine learning pave the way for ARM algorithms that can continuously learn and adapt to evolving data patterns. No, ARM algorithms can be implemented within various datamining software tools.
By using it, managers reduce the costs of creating the cloud system and gain more time to analyze data. That way, you won’t be trapped in rigid structures that were built around multiple compute clusters. Conclusion Indeed BigQuery responds to all the business issues relating to the world of data (or Business Intelligence).
Introduction Artificial Intelligence (AI) transforms industries by enabling machines to mimic human intelligence. Python’s simplicity, versatility, and extensive library support make it the go-to language for AI development. Python is renowned for its simplicity and versatility, making it an ideal choice for AI applications.
Predictive analytics is a method of using past data to predict future outcomes. It relies on tools like datamining , machine learning , and statistics to help businesses make decisions. Classification Models : These models help businesses categorize data, like whether a customer will stay or leave.
Jeff Hammerbacher, Former Data Manager, Facebook The world has changed since then. Over the past ten years, we've gotten to see a lot of attempts to apply data science and AI for social impact. There are huge ethical implications from design decisions in data science and AI, but use lags behind available tools.
Machine Learning Machine Learning is a critical component of modern Data Analysis, and Python has a robust set of libraries to support this: Scikit-learn This library helps execute Machine Learning models, automating the process of generating insights from large volumes of data.
Customer Segmentation using K-Means Clustering One of the most crucial uses of data science is customer segmentation. You will need to use the K-clustering method for this GitHub datamining project. This renowned unsupervised machine learning approach splits data into K clusters based on similarities.
Summary: The blog explores the synergy between Artificial Intelligence (AI) and Data Science, highlighting their complementary roles in Data Analysis and intelligent decision-making. Introduction Artificial Intelligence (AI) and Data Science are revolutionising how we analyse data, make decisions, and solve complex problems.
Role in Extracting Insights from Raw Data Raw data is often complex and unorganised, making it difficult to derive useful information. Data Analysis plays a crucial role in filtering and structuring this data. Techniques: Data Visualisation: Graphs, charts, and plots to help visualise trends and outliers.
Mastering programming, statistics, Machine Learning, and communication is vital for Data Scientists. A typical Data Science syllabus covers mathematics, programming, Machine Learning, datamining, big data technologies, and visualisation. This skill allows the creation of predictive models and insights from data.
Topic Modeling Topic modeling is a text-mining technique used to uncover underlying themes or topics within a large collection of documents. It helps in discovering hidden patterns and organizing text data into meaningful clusters. Cluster similar documents based on their content and explore relationships between topics.
But the most important challenges center on data. When it comes to AI, your proprietary data is your moat. Using your data properly creates a competitive advantage no one can take away. The generalized nature of their training data and the semi-random nature of their outputs create unignorable shortfalls in accuracy.
Summary : This article equips Data Analysts with a solid foundation of key Data Science terms, from A to Z. Introduction In the rapidly evolving field of Data Science, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
But the most important challenges center on data. When it comes to AI, your proprietary data is your moat. Using your data properly creates a competitive advantage no one can take away. The generalized nature of their training data and the semi-random nature of their outputs create unignorable shortfalls in accuracy.
It is developed by Facebook’s AI Research Lab (FAIR) and authored by Adam Paszke, Sam Gross, Soumith Chintala, and Gregory Chanan. Scikit-Learn Scikit-Learn, or simply called SKLearn, is the most popular machine learning framework that supports various algorithms for classification, regression, and clustering. It’s a bit complex.
But the most important challenges center on data. When it comes to AI, your proprietary data is your moat. Using your data properly creates a competitive advantage no one can take away. The generalized nature of their training data and the semi-random nature of their outputs create unignorable shortfalls in accuracy.
How to become a data scientist Data transformation also plays a crucial role in dealing with varying scales of features, enabling algorithms to treat each feature equally during analysis Noise reduction As part of data preprocessing, reducing noise is vital for enhancing data quality.
Expansive Hiring The IT and service sector is actively hiring Data Scientists. In fact, these industries majorly employ Data Scientists. Python, DataMining, Analytics and ML are one of the most preferred skills for a Data Scientist. The post How to optimize your LinkedIn as a Data Scientist?
Server Side Execution Plan When you trigger a Snowpark operation, the optimized SQL code and instructions are sent to the Snowflake servers where your data resides. This eliminates unnecessary data movement, ensuring optimal performance. Snowflake spins up a virtual warehouse, which is a cluster of compute nodes, to execute the code.
Challenge #1: Data Cleaning and Preprocessing Data Cleaning refers to adding the missing data in a dataset and correcting and removing the incorrect data from a dataset. On the other hand, Data Pre-processing is typically a datamining technique that helps transform raw data into an understandable format.
Applications: It is extensively used for statistical analysis, data visualisation, and machine learning tasks such as regression, classification, and clustering. Recent Advancements: The R community continues to release updates and packages, expanding its capabilities in data visualisation and machine learning algorithms in 2024.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content