This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For this post we’ll use a provisioned Amazon Redshift cluster. Set up the Amazon Redshift cluster We’ve created a CloudFormation template to set up the Amazon Redshift cluster. Implementation steps Load data to the Amazon Redshift cluster Connect to your Amazon Redshift cluster using Query Editor v2.
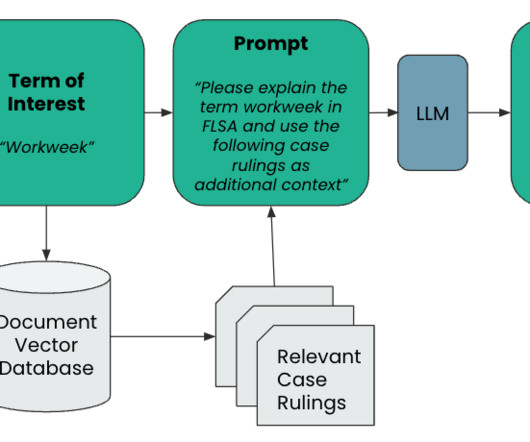
Additionally, we dive into integrating common vector database solutions available for Amazon Bedrock Knowledge Bases and how these integrations enable advanced metadata filtering and querying capabilities. Metadata filtering allows you to segment data inside of an OpenSearch Serverless vector database.
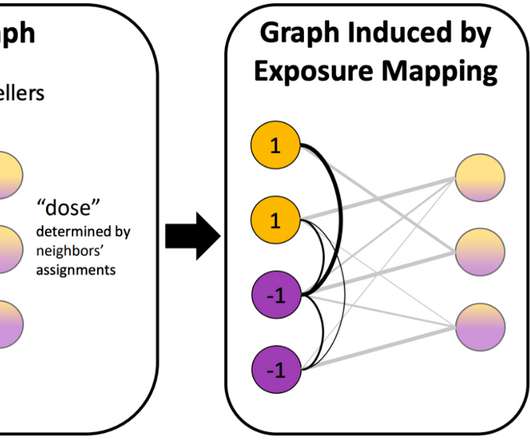
In 2022, we continued this journey, and advanced the state-of-the-art in several related areas. We continued our efforts in developing new algorithms for handling large datasets in various areas, including unsupervised and semi-supervised learning , graph-based learning , clustering , and large-scale optimization.
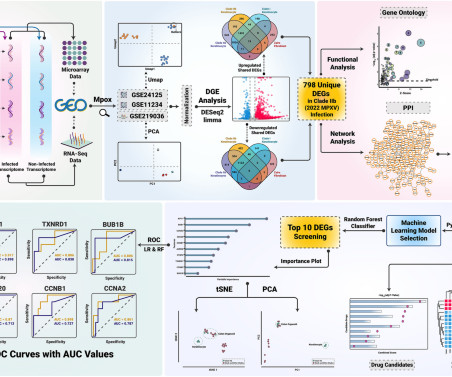
Monkeypox virus (MPXV), a zoonotic pathogen, re-emerged in 2022 with the Clade IIb variant, raising global health concerns due to its unprecedented spread in non-endemic regions. Comparative differential gene expression (DGE) analysis revealed 798 DEGs exclusive to the 2022 MPXV invasion in the skin cell types& (keratinocytes).
simple Finance Did meta have any mergers or acquisitions in 2022? Vector database FloTorch selected Amazon OpenSearch Service as a vector database for its high-performance metrics. The implementation included a provisioned three-node sharded OpenSearch Service cluster. Each provisioned node was r7g.4xlarge,
In 2022, security wasn’t in the news as often as it was in 2020 and 2021. Database Proliferation Years ago, I wrote that NoSQL wasn’t a database technology; it was a movement. It was a movement that affirmed the development and use of database architectures other than the relational database.
This post shows you how to set up RAG using DeepSeek-R1 on Amazon SageMaker with an OpenSearch Service vector database as the knowledge base. Complete the following steps: On the OpenSearch Service console, choose Dashboard under Managed clusters in the navigation pane. In 2022, it was 18,867,000, and in 2023, it's 18,937,000.
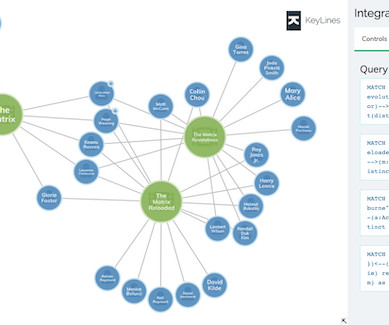
That’s why our data visualization SDKs are database agnostic: so you’re free to choose the right stack for your application. There have been a lot of new entrants and innovations in the graph database category, with some vendors slowly dipping below the radar, or always staying on the periphery. can handle many graph-type problems.
In 2022, we expanded our research interactions and programs to faculty and students across Latin America , which included grants to women in computer science in Ecuador. See some of the datasets and tools we released in 2022 listed below. sequence protein database with annotations. MGnify proteins A 2.4B-sequence
One of the foundational services is Amazon Elastic Compute Cloud (EC2), which allows users to have at their disposal a virtual cluster of computers, with extremely high availability, which can be interacted with over the internet via REST APIs, a CLI or the AWS console. Statement: 'AWS revenue in 2022 was $80 billion.' Assistant: 0.05
The most common unsupervised learning method is cluster analysis, which uses clustering algorithms to categorize data points according to value similarity (as in customer segmentation or anomaly detection ). K-means clustering is commonly used for market segmentation, document clustering, image segmentation and image compression.
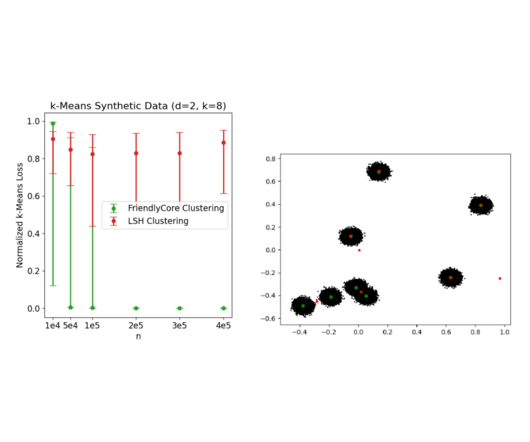
In “ FriendlyCore: Practical Differentially Private Aggregation ”, presented at ICML 2022 , we introduce a general framework for computing differentially private aggregations. Clustering and other applications Other applications of our aggregation method are clustering and learning the covariance matrix of a Gaussian distribution.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB.
This is done by creating a store of relevant knowledge, usually in the form of embeddings in a vector database, to supplement additional context for the LLM to consider when formulating a response. As an example, let’s take a look at a response from GPT-4, which only has data available up to January 2022. What is the Impact of RAG?
The Snowflake Data Cloud has been a market leader for database systems that are built for the cloud and support an unlimited number of warehouses. ” This is where you might think about data clustering to increase throughput and decrease latency for your queries. In this blog, we will explore the option of data clustering.
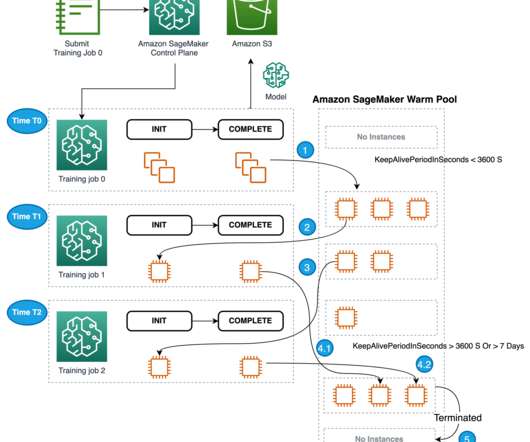
Deep Dive into Model Tuning and Benefits of Warm Pools SageMaker Automated Model Tuning leverages Warm Pools by default for any tuning job as of August 2022 (announcement). After the first training job is complete, the instances used for training are retained in the warm pool cluster.
The Curse of the LLMs 30th November, 2022 will be remembered as the watershed moment in artificial intelligence. Vectors are typically stored in Vector Databases which are best suited for searching. APIs File Directories Databases And many more The first step is to extract the information present in these source locations.
In 2022, the term data mesh has started to become increasingly popular among Snowflake and the broader industry. As an example, an IT team could easily take the knowledge of database deployment from on-premises and deploy the same solution in the cloud on an always-running virtual machine.
Big Ideas What to look out for in 2022 1. They bring deep expertise in machine learning , clustering , natural language processing , time series modelling , optimisation , hypothesis testing and deep learning to the team. Automation Automating data pipelines and models ➡️ 6. Deployment How to build sustainable, scalable live systems ?
in 2022, according to the PYPL Index. Scikit-learn covers various classification , regression , clustering , and dimensionality reduction algorithms. Start with supervised learning techniques like regression and classification, then move on to unsupervised learning methods like clustering.
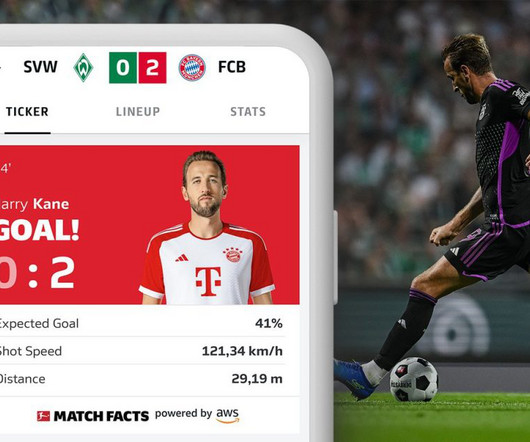
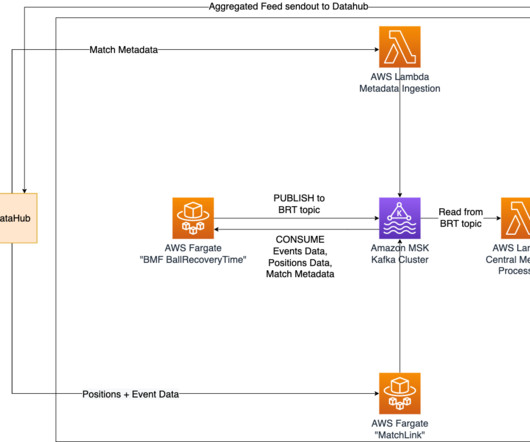
We analyzed around 215 matches from the Bundesliga 2022–2023 season. Simultaneously, the shot speed data finds its way to a designated topic within our MSK cluster. Once the Lambda function is triggered, it stores the data in an Amazon Aurora Serverless database. This is the key number that represents the shot’s speed and power.
The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. In November 2022, ChatGPT was released, a large language model (LLM) that used the transformer architecture, and is widely credited with starting the current generative AI boom.
This style of play is also evident when you look at the ball recovery times for the first 24 match days in the 2022/23 season. Let’s look at certain games played by Cologne in the 2022/23 season. A Lambda function retrieves all recovery times from the relevant Kafka topic and stores them in an Amazon Aurora Serverless database.
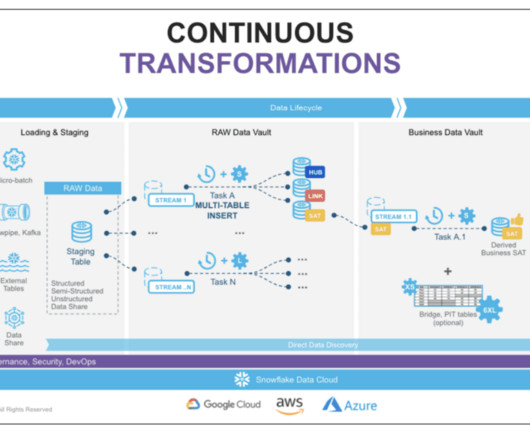
To set up this approach, a multi-cluster warehouse is recommended for stage loads, and separate multi-cluster warehouses can be used to run all loads in parallel. The multi-cluster virtual warehouse option automatically scales out and load balances all tasks as hubs, links, and satellites are introduced.
This dataset comprises a multi-center critical care database collected from over 200 hospitals, which makes it ideal to test our FL experiments. We used the eICU Collaborative Research Database , a multi-center intensive care unit (ICU) database, comprising 200,859 patient unit encounters for 139,367 unique patients.
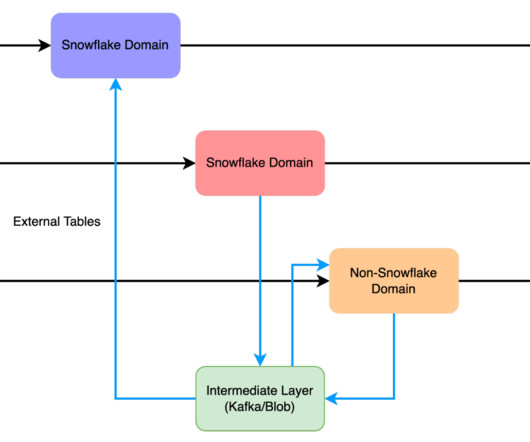
Database Per Domain A popular approach is to utilize a single Snowflake account. In this setup, various domains operate within distinct databases and autonomous compute clusters, each serving as its independent environment. Luckily, Snowflake has topology options to support distributed domains.
Like traditional database index, vector index organizes the vectors into a data structure and makes it possible to navigate through the vectors and find the ones that are closest in terms of semantic similarity. Clustering — we can cluster our sentences, useful for topic modeling. Reduced price. lower price.
or GPT-4 arXiv, OpenAlex, CrossRef, NTRS lgarma Topic clustering and visualization, paper recommendation, saved research collections, keyword extraction GPT-3.5 I had some expirience working with vector databases and topic modeling, and recognized the oportunity. bge-small-en-v1.5 I live in Pentagon City with my wife and 2 cats.
Extract Data We will use Google Trends as a database to extract data, it is a public web-based tool that allows users to explore the popularity of search queries on Google. We have to create a database for the project: Figure 8: Creating a Dabase in pgAdmin4 Next, we have to write database’s name and save?. Windows NT 10.0;
By having all their data in a single, globally available, governed platform, AMCs can build a strategic security master database and also support their workflows efficiently. Snowflake’s zero-management infrastructure and multi-cluster shared architecture simplify data management, freeing up additional capacity for analytics.
The introduction of ChatGPT in November 2022 upended the AI landscape. For example, if a data team wants to use an LLM to examine financial documents—something the model may perform poorly on out of the box—the team can fine-tune it on something like the Financial Documents Clustering data set. A search engine such as Google or Bing.
million in 2022, is projected to grow at a CAGR of 18.15% , reaching USD 140,808.0 They are responsible for building and maintaining data architectures, which include databases, data warehouses, and data lakes. Data Modelling Data modelling is creating a visual representation of a system or database. million by 2028.
The introduction of ChatGPT in November 2022 upended the AI landscape. For example, if a data team wants to use an LLM to examine financial documents—something the model may perform poorly on out of the box—the team can fine-tune it on something like the Financial Documents Clustering data set. A search engine such as Google or Bing.
Traditional AI can recognize, classify, and cluster, but not generate the data it is trained on. Major milestones in the last few years comprised BERT (Google, 2018), GPT-3 (OpenAI, 2020), Dall-E (OpenAI, 2021), Stable Diffusion (Stability AI, LMU Munich, 2022), ChatGPT (OpenAI, 2022). And it will change everything.
billion in 2022 and is expected to grow significantly, reaching USD 505.42 Clustering and dimensionality reduction are common tasks in unSupervised Learning. For example, clustering algorithms can group customers by purchasing behaviour, even if the group labels are not predefined. billion by 2031 at a CAGR of 34.20%.
billion in 2022 and is projected to reach USD 505.42 The publicly available repository offers datasets for various tasks, including classification, regression, clustering, and more. Clustering : Datasets that involve grouping data into clusters without predefined labels. It was valued at USD 35.80 billion by 2031.
For instance, you could extract a few noisy metrics, such as a general “positivity” sentiment score that you track in a dashboard, while you also produce more nuanced clustering of the posts which are reviewed periodically in more detail. So you do have to work around things, and use things like vector databases or other tricks.
billion in 2022 and is expected to grow to USD 505.42 Key techniques in unsupervised learning include: Clustering (K-means) K-means is a clustering algorithm that groups data points into clusters based on their similarities. databases, CSV files). The global Machine Learning market was valued at USD 35.80
Ever since the release of ChatGPT in November 2022, organizations have been trying to find new and innovative ways to leverage gen AI to drive organizational growth. They can provide information, summaries and insights across many fields without the need for external databases in real-time applications.
” — Isaac Vidas , Shopify’s ML Platform Lead, at Ray Summit 2022 Monitoring Monitoring is an essential DevOps practice, and MLOps should be no different. Isaac Vidas , Shopify’s ML Platform Lead, at Ray Summit 2022 Once you understand the problem your data scientists face, your focus can now be on how to solve it.
If we asked whether their companies were using databases or web servers, no doubt 100% of the respondents would have said “yes.” ChatGPT was opened to the public on November 30, 2022, roughly a year ago; the art generators, such as Stable Diffusion and DALL-E, are somewhat older. We expect others to follow.
We select Amazon’s SEC filing reports for years 2021–2022 as the training data to fine-tune the GPT-J 6B model. We serve developers and enterprises of all sizes through AWS, which offers a broad set of global compute, storage, database, and other service offerings. We also manufacture and sell electronic devices.
The startup cost is now lower to deploy everything from a GPU-enabled virtual machine for a one-off experiment to a scalable cluster for real-time model execution. Deep learning - It is hard to overstate how deep learning has transformed data science.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody. PA : Got it.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















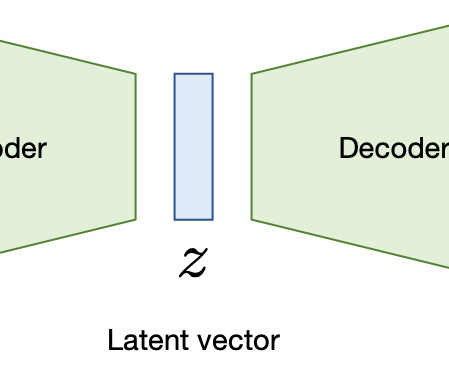



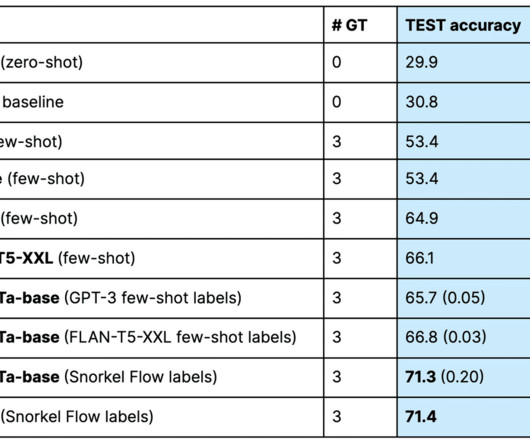

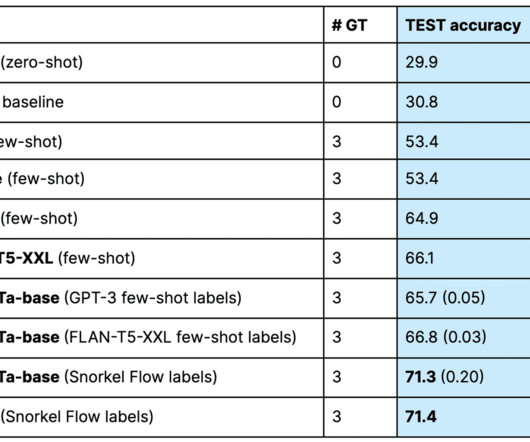





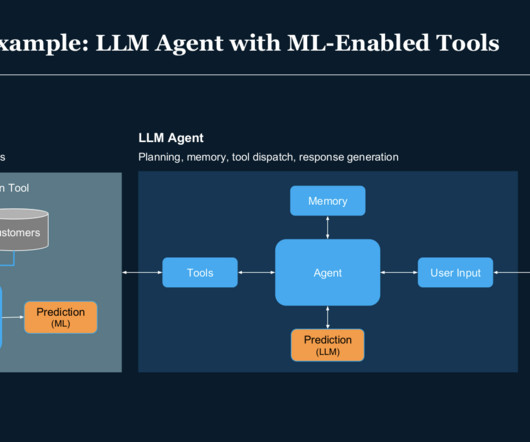









Let's personalize your content