This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
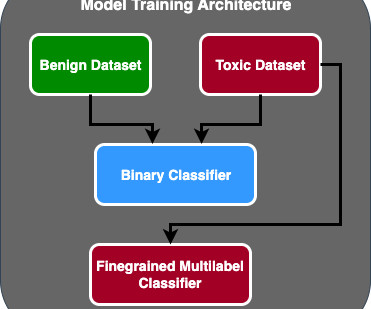
Source: Canva Introduction In 2018, Google AI researchers came up with BERT, which revolutionized the NLP domain. Later in 2019, the researchers proposed the ALBERT (“A Lite BERT”) model for self-supervisedlearning of language representations, which shares the same architectural backbone as BERT.
It is an annual tradition for Xavier Amatriain to write a year-end retrospective of advances in AI/ML, and this year is no different. Gain an understanding of the important developments of the past year, as well as insights into what expect in 2020.
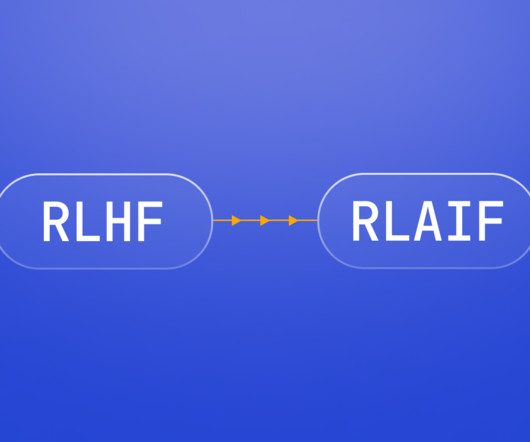
In the interim, it was actually image models like DALL-E 2 and Stable Diffusion that instead took the limelight and gave the world a first look at the power of modern AI models. More recently, a new method called Reinforcement Learning from AI Feedback (RLAIF) sets a new precedent, both from performance and ethical perspectives.
If you want to ride the next big wave in AI, grab a transformer. A transformer model is a neural network that learns context and thus meaning by tracking relationships in sequential data like the words in this sentence. They’re driving a wave of advances in machine learning some have dubbed transformer AI.
Last Updated on July 25, 2023 by Editorial Team Author(s): Abhijit Roy Originally published on Towards AI. Semi-Supervised Sequence Learning As we all know, supervisedlearning has a drawback, as it requires a huge labeled dataset to train. But, the question is, how did all these concepts come together?
Improvements using foundation models Despite yielding promising results, PORPOISE and HEEC algorithms use backbone architectures trained using supervisedlearning (for example, ImageNet pre-trained ResNet50). He works hands-on with customers to design and build solutions for data analytics and AI applications in healthcare.
Generative artificial intelligence ( generative AI ) models have demonstrated impressive capabilities in generating high-quality text, images, and other content. While this data holds valuable insights, its unstructured nature makes it difficult for AI algorithms to interpret and learn from it. read HTML).
How ChatGPT really works and will it change the field of IT and AI? — a As we can read in the article, the only difference between InstructGPT and ChatGPT is the fact that the annotators played both the user and AI assistant. The hypothesis as to why such training was particularly effective is explained in the next section.
Foundation models are large AI models trained on enormous quantities of unlabeled data—usually through self-supervisedlearning. Foundation models underpin generative AI capabilities, from text-generation to music creation to image generation. What is self-supervisedlearning? Find out in the guide below.
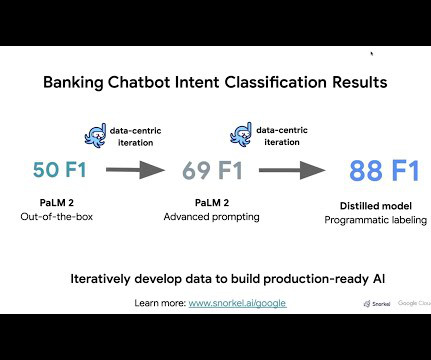
AWS ProServe solved this use case through a joint effort between the Generative AI Innovation Center (GAIIC) and the ProServe ML Delivery Team (MLDT). The AWS GAIIC is a group within AWS ProServe that pairs customers with experts to develop generative AI solutions for a wide range of business use cases using proof of concept (PoC) builds.
Over the next several weeks, we will discuss novel developments in research topics ranging from responsible AI to algorithms and computer systems to science, health and robotics. Top Responsible AIAI must be pursued responsibly. More than words on paper, we apply our AI Principles in practice. Let’s get started!
2019) Data Science with Python. 2019) Applied SupervisedLearning with Python. Skicit-Learn (2023): Cross-validation: evaluating estimator performance, available at: [link] [5 September 2023] WRITER at MLearning.ai / AI Agents LLM / Good-Bad AI Art / Sensory Mlearning.ai Reference: Chopra, R.,
2019) Data Science with Python. 2019) Applied SupervisedLearning with Python. 2019) Python Machine Learning. 2019) Python Machine Learning. WRITER at MLearning.ai / 800+ AI plugins / AI Searching 2024 Mlearning.ai References: Chopra, R., England, A. and Alaudeen, M. Johnston, B.
LLMs’ flexibility dazzles, but most AI problems don’t require flexibility. Data scientists can use distillation to jumpstart classification models or to align small-format generative AI (GenAI) models to produce better responses. Users can ask ChatGPT , Bard , or Grok any number of questions and often get useful answers.
LLMs’ flexibility dazzles, but most AI problems don’t require flexibility. Data scientists can use distillation to jumpstart classification models or to align small-format generative AI (GenAI) models to produce better responses. Users can ask ChatGPT , Bard , or Grok any number of questions and often get useful answers.
Data scientists and researchers train LLMs on enormous amounts of unstructured data through self-supervisedlearning. The model then predicts the missing words (see “what is self-supervisedlearning?” OpenAI’s GPT-2, finalized in 2019 at 1.5 billion parameters, raised eyebrows by producing convincing prose.
Data scientists and researchers train LLMs on enormous amounts of unstructured data through self-supervisedlearning. The model then predicts the missing words (see “what is self-supervisedlearning?” OpenAI’s GPT-2, finalized in 2019 at 1.5 billion parameters, raised eyebrows by producing convincing prose.
” So let’s say we’ve got the text “ The best thing about AI is its ability to ” Imagine scanning billions of pages of human-written text (say on the web and in digitized books) and finding all instances of this text—then seeing what word comes next what fraction of the time. Here’s a random example.
Xindi Liu ¶ Place: 3rd Prize: $9,000 Hometown: Huaibei City, Anhui Province, China Username: dylanliu Background: Im a freelance programmer (AI related) with 7 years of experience. I love participating in various competitions involving deep learning, especially tasks involving natural language processing or LLMs.
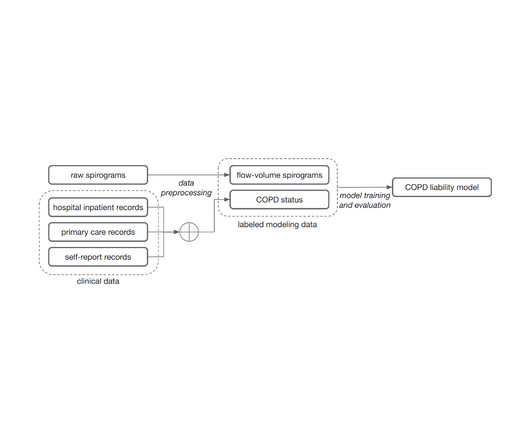
ML for deeper understanding of exhalation For this demonstration, we focused on COPD, the third leading cause of worldwide death in 2019 , in which airway inflammation and impeded airflow can progressively reduce lung function. The profile of individuals w/o COPD is different.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content