This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Spotify Million Playlist Released for RecSys 2018, this dataset helps analyze short-term and sequential listening behavior. By, Avi Chawla - highly passionate about approaching and explaining datascience problems with intuition. Yelp Open Dataset Contains 8.6M reviews, but coverage is sparse and city-specific.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering DataScienceLanguage Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter AI Agents in Analytics Workflows: Too Early or Already Behind?
Transformer models are a type of deep learning model that are used for naturallanguageprocessing (NLP) tasks. Learn more about NLP in this blog —-> Applications of NaturalLanguageProcessing The transformer has been so successful because it is able to learn long-range dependencies between words in a sentence.
Transformer models are a type of deep learning model that are used for naturallanguageprocessing (NLP) tasks. Learn more about NLP in this blog —-> Applications of NaturalLanguageProcessing The transformer has been so successful because it is able to learn long-range dependencies between words in a sentence.
By harnessing machine learning, naturallanguageprocessing, and deep learning, Google AI enhances various products and services, making them smarter and more user-friendly. Formerly known as Google Research, it was rebranded during the 2018 Google I/O conference.
I worked on an early conversational AI called Marcel in 2018 when I was at Microsoft. In 2018 when BERT was introduced by Google, I cannot emphasize how much it changed the game within the NLP community. Submission Suggestions A Quick Recap of NaturalLanguageProcessing was originally published in MLearning.ai
GenAI I serve as the Principal Data Scientist at a prominent healthcare firm, where I lead a small team dedicated to addressing patient needs. Over the past 11 years in the field of datascience, I’ve witnessed significant transformations. Expand your skillset by… courses.analyticsvidhya.com 2.
AI encompasses the creation of intelligent machines capable of autonomous decision-making, while Predictive Analytics relies on data, statistics, and machine learning to forecast future events accurately. Read more –> DataScience vs AI – What is 2023 demand for?
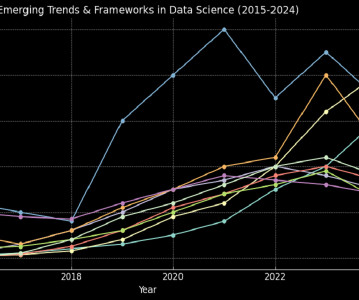
Over the past decade, datascience has undergone a remarkable evolution, driven by rapid advancements in machine learning, artificial intelligence, and big data technologies. This blog dives deep into these changes of trends in datascience, spotlighting how conference topics mirror the broader evolution of datascience.
Once a set of word vectors has been learned, they can be used in various naturallanguageprocessing (NLP) tasks such as text classification, language translation, and question answering. GPT-1 (2018) This was the first GPT model and was trained on a large corpus of text data from the internet.
Deep learning And NLP Deep Learning and NaturalLanguageProcessing (NLP) are like best friends in the world of computers and language. Building Chatbots involves creating AI systems that employ deep learning techniques and naturallanguageprocessing to simulate natural conversational behavior.
The data set only helps it if it’s well-trained and supervised. A Mongolian pharmaceutical company engaged in a pilot study in 2018 to detect fake drugs, an initiative with the potential to save hundreds of thousands of lives. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
NaturalLanguageProcessing Getting desirable data out of published reports and clinical trials and into systematic literature reviews (SLRs) — a process known as data extraction — is just one of a series of incredibly time-consuming, repetitive, and potentially error-prone steps involved in creating SLRs and meta-analyses.
EVENT — ODSC East 2024 In-Person and Virtual Conference April 23rd to 25th, 2024 Join us for a deep dive into the latest datascience and AI trends, tools, and techniques, from LLMs to data analytics and from machine learning to responsible AI. She is currently part of the Artificial Intelligence Practice at Avanade.
John on Patmos | Correggio NATURALLANGUAGEPROCESSING (NLP) WEEKLY NEWSLETTER The NLP Cypher | 02.14.21 mlpen/Nystromformer Transformers have emerged as a powerful workhorse for a broad range of naturallanguageprocessing tasks. The Vision of St. Heartbreaker Hey Welcome back! Connected Papers ?
His research interests are in the area of naturallanguageprocessing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. Dr. Huan works on AI and DataScience. He focuses on developing scalable machine learning algorithms. He founded StylingAI Inc.,
Text analytics: Text analytics, also known as text mining, deals with unstructured text data, such as customer reviews, social media comments, or documents. It uses naturallanguageprocessing (NLP) techniques to extract valuable insights from textual data. Poor data integration can lead to inaccurate insights.
Transformers, BERT, and GPT The transformer architecture is a neural network architecture that is used for naturallanguageprocessing (NLP) tasks. BERT can be fine-tuned for a variety of NLP tasks, including question answering, naturallanguage inference, and sentiment analysis.
While this requires technology – AI, machine learning, log parsing, naturallanguageprocessing,metadata management, this technology must be surfaced in a form accessible to business users – the data catalog. The Forrester Wave : Machine Learning Data Catalogs, Q2 2018.
Deeper Insights has six years of experience in building AI solutions for large enterprise and scale-up clients, a suite of AI models, and data visualization dashboards that enable them to quickly analyze and share insights. Generative AI integration service : proposes to train Generative AI on clients data and add new features to products.
By using our mathematical notation, the entire training process of the autoencoder can be written as follows: Figure 2 demonstrates the basic architecture of an autoencoder: Figure 2: Architecture of Autoencoder (inspired by Hubens, “Deep Inside: Autoencoders,” Towards DataScience , 2018 ).
We also note that our models primarily work well for search, recommendation, and naturallanguageprocessing tasks that typically feature large, high-dimensional output spaces and a requirement of extremely low inference latency. In 2018, Science news named him one of the Top-10 scientists under 40 to watch.
But what if there was a technique to quickly and accurately solve this language puzzle? Enter NaturalLanguageProcessing (NLP) and its transformational power. But what if there was a way to unravel this language puzzle swiftly and accurately?
A foundation model is built on a neural network model architecture to process information much like the human brain does. A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks. An open-source model, Google created BERT in 2018.
AWS received about 100 samples of labeled data from the customer, which is a lot less than the 1,000 samples recommended for fine-tuning an LLM in the datascience community. Han Man is a Senior DataScience & Machine Learning Manager with AWS Professional Services based in San Diego, CA.
John on Patmos | Correggio NATURALLANGUAGEPROCESSING (NLP) WEEKLY NEWSLETTER The NLP Cypher | 02.14.21 mlpen/Nystromformer Transformers have emerged as a powerful workhorse for a broad range of naturallanguageprocessing tasks. The Vision of St. Heartbreaker Hey Welcome back! Connected Papers ?
There are a few limitations of using off-the-shelf pre-trained LLMs: They’re usually trained offline, making the model agnostic to the latest information (for example, a chatbot trained from 2011–2018 has no information about COVID-19). He got his masters from Courant Institute of Mathematical Sciences and B.Tech from IIT Delhi.
Imagine an AI system that becomes proficient in many tasks through extensive training on each specific problem and a higher-order learning process that distills valuable insights from previous learning endeavors. NaturalLanguageProcessing: With Meta-Learning, language models can be generalized across various languages and dialects.
Here are some examples of what multimodal AI can do: Speech recognition: Multimodal AI can understand and transcribe spoken language, allowing it to interact with users through voice commands and naturallanguageprocessing.
Quantitative evaluation We utilize 2018–2020 season data for model training and validation, and 2021 season data for model evaluation. He is broadly interested in Deep Learning and NaturalLanguageProcessing. Label smoothing steers the annotated coverage class slightly towards the remaining classes.
In this post, we show you how to train the 7-billion-parameter BloomZ model using just a single graphics processing unit (GPU) on Amazon SageMaker , Amazon’s machine learning (ML) platform for preparing, building, training, and deploying high-quality ML models. BloomZ is a general-purpose naturallanguageprocessing (NLP) model.
A lot of people are building truly new things with Large Language Models (LLMs), like wild interactive fiction experiences that weren’t possible before. But if you’re working on the same sort of NaturalLanguageProcessing (NLP) problems that businesses have been trying to solve for a long time, what’s the best way to use them?
Mar 25: Towards the end of the month, Ines had the honor to be a guest at WiDS (Women in DataScience) Poznań , where she talked practical transfer learning for NLP. We had already decided at the end of 2018 that we wanted to do this and after seven months of planning and hard work, we couldn’t have been happier with the result.
But now, a computer can be taught to comprehend and process human language through NaturalLanguageProcessing (NLP), which was implemented, to make computers capable of understanding spoken and written language. We’re committed to supporting and inspiring developers and engineers from all walks of life.
For example, supporting equitable student persistence in computing research through our Computer Science Research Mentorship Program , where Googlers have mentored over one thousand students since 2018 — 86% of whom identify as part of a historically marginalized group.
Introduction In today’s digital age, the volume of data generated is staggering. According to a report by Statista, the global data sphere is expected to reach 180 zettabytes by 2025 , a significant increase from 33 zettabytes in 2018.
A brief history of large language models Large language models grew out of research and experiments with neural networks to allow computers to processnaturallanguage. From 2018 to the modern day, NLP researchers have engaged in a steady march toward ever-larger models.
A brief history of large language models Large language models grew out of research and experiments with neural networks to allow computers to processnaturallanguage. From 2018 to the modern day, NLP researchers have engaged in a steady march toward ever-larger models.
Read More: Top 7 Generative AI Use Cases and Application Hugging Face Hugging Face is a New York-based AI research company that is best known for its work on open-source naturallanguageprocessing (NLP) models.
Most solvers were datascience professionals, professors, and students, but there were also many data analysts, project managers, and people working in public health and healthcare. I love participating in various competitions involving deep learning, especially tasks involving naturallanguageprocessing or LLMs.
In the rapidly developing fields of AI and datascience, innovation is constant, and constantly advances by leaps and bounds. a company dedicated to democratizing AI technology, which was recognized as a World Economic Forum Technology Pioneer in 2018. The long wait is over! Beyond academia, Prof. Xing co-founded Petuum Inc.,
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content