
Counting shots, making strides: Zero, one and few-shot learning unleashed
Data Science Dojo
DECEMBER 8, 2023
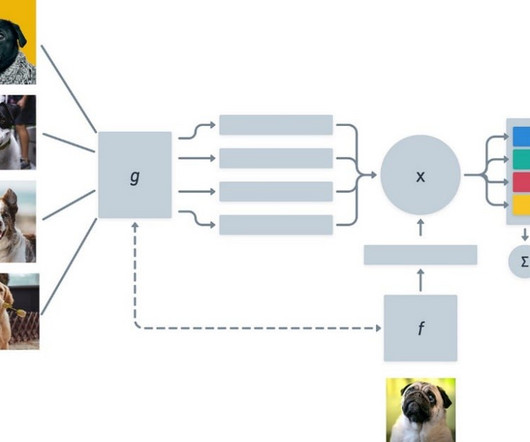
Zero-shot, one-shot, and few-shot learning are redefining how machines adapt and learn, promising a future where adaptability and generalization reach unprecedented levels. Source: Photo by Hal Gatewood on Unsplash In this exploration, we navigate from the basics of supervised learning to the forefront of adaptive models.










Let's personalize your content