This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
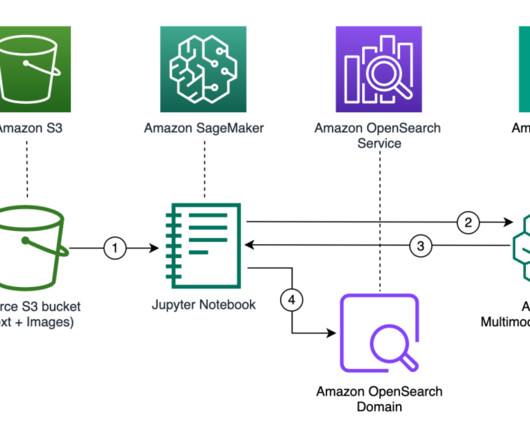
OpenSearch Service is the AWS recommended vector database for Amazon Bedrock. OpenSearch is a distributed open-source search and analytics engine composed of a search engine and vector database. To learn more, see Improve search results for AI using Amazon OpenSearch Service as a vector database with Amazon Bedrock.
AWS (Amazon Web Services) is a comprehensive cloudcomputing platform offering a wide range of services like computing power, database storage, content delivery, and more.n2. Make sure that we have Powertools for AWS Lambda (Python) available in our runtime, for example, by attaching a Lambda layer to our function.
It was built using a combination of in-house and external cloud services on Microsoft Azure for large language models (LLMs), Pinecone for vectorized databases, and Amazon Elastic ComputeCloud (Amazon EC2) for embeddings. Opportunities for innovation CreditAI by Octus version 1.x
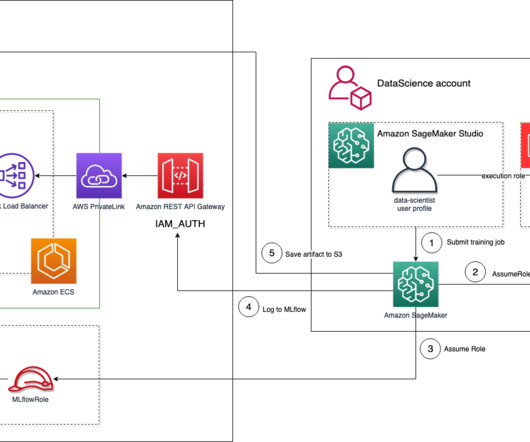
With cloudcomputing, as compute power and data became more available, machine learning (ML) is now making an impact across every industry and is a core part of every business and industry. The SourceIdentity attribute is used to tie the identity of the original SageMaker Studio user to the Amazon Redshift database user.
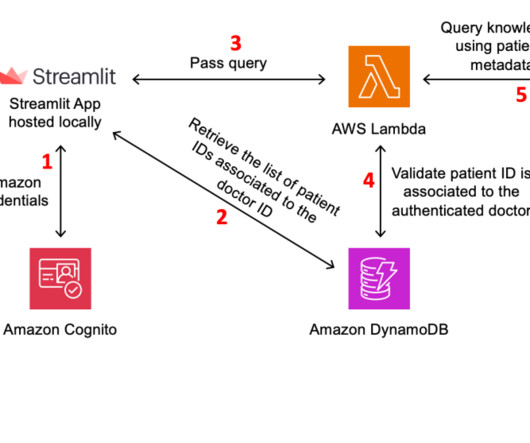
After the doctor has successfully signed in, the application retrieves the list of patients associated with the doctor’s ID from the Amazon DynamoDB database. Before querying the knowledge base, the Lambda function retrieves data from the DynamoDB database, which stores doctor-patient associations.
Deploys an Amazon Aurora Serverless database for the data store and Amazon Simple Storage Service (Amazon S3) for the artifact store. Irshad works with large AWS Global ISV and SI partners and helps them build their cloud strategy and broad adoption of Amazon’s cloudcomputing platform.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








Let's personalize your content