This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Supportvectormachines (SVM) are at the forefront of machine learning techniques used for both classification and regression tasks. What are supportvectormachines (SVMs)? Advantages of supportvectormachines SVMs offer several advantages, particularly in terms of accuracy and efficiency.
SupportVectorMachines (SVM) are a cornerstone of machine learning, providing powerful techniques for classifying and predicting outcomes in complex datasets. What are SupportVectorMachines (SVM)? They work by identifying a hyperplane that best separates distinct classes within the data.
These techniques leverage mathematical models and computational tools to interpret data, detect patterns, and facilitate informed decision-making. Among the most significant models are non-linear models, supportvectormachines, and linear regression.
They are also used in machine learning, such as supportvectormachines and k-means clustering. Robust inference: Robust inference is a technique that is used to make inferences that are not sensitive to outliers or extreme observations.
Matplotlib is a great tool for data visualization and is widely used in data analysis, scientific computing, and machine learning. Seaborn Seaborn is a library for creating attractive and informative statistical graphics in Python. Scikit-learn Scikit-learn is a powerful library for machine learning in Python.
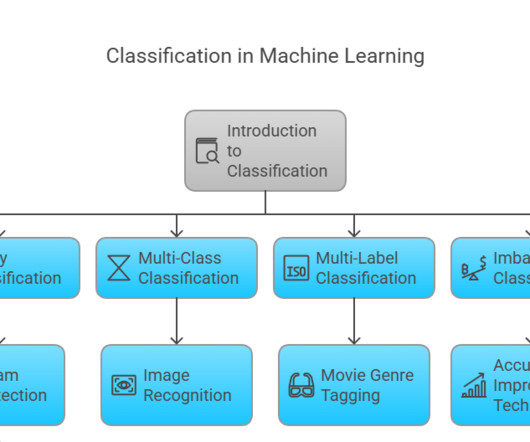
Overview of classification in machine learning Classification serves as a foundational method in machine learning, where algorithms are trained on labeled datasets to make predictions. Classification methods are vital for organizing information and making data-driven decisions.
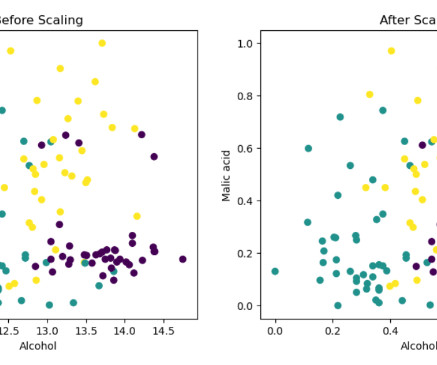
In the world of data science and machine learning, feature transformation plays a crucial role in achieving accurate and reliable results. By manipulating the input features of a dataset, we can enhance their quality, extract meaningful information, and improve the performance of predictive models.
Applications of hyperplanes in machine learning Hyperplanes play a critical role in various machine learning algorithms, ranging from classification to clustering and regression. This theorem is crucial in classification algorithms, as it informs decisions about the applicability of linear classifiers to specific datasets.
SupportVectorMachines were disrupted by deep learning, and convolutional neural networks were displaced by transformers. Estimating a token count for this additional information is difficult, however. tokens per second, are they benefiting from all the extra sensory information?
Whether in finance, healthcare, or environmental science, these algorithms establish relationships between variables, enabling organizations to forecast outcomes and make informed decisions. Regression algorithms are powerful tools that help us make sense of complex data by predicting continuous numeric values based on various inputs.
By understanding machine learning algorithms, you can appreciate the power of this technology and how it’s changing the world around you! It’s like having a super-powered tool to sort through information and make better sense of the world. Learn in detail about machine learning algorithms 2.
Its discriminative AI capabilities allow it to analyze audio inputs, extract relevant information, and generate appropriate responses, showcasing the power of AI-driven conversational systems in enhancing user experiences and streamlining business operations.
Matplotlib is a great tool for data visualization and is widely used in data analysis, scientific computing, and machine learning. Seaborn Seaborn is a library for creating attractive and informative statistical graphics in Python. Scikit-learn Scikit-learn is a powerful library for machine learning in Python.
Example: Determining whether an email is spam or not based on features like word frequency and sender information. SupportVectorMachines (SVM) SVMs are powerful classification algorithms that work by finding the hyperplane that best separates different classes in high-dimensional space.
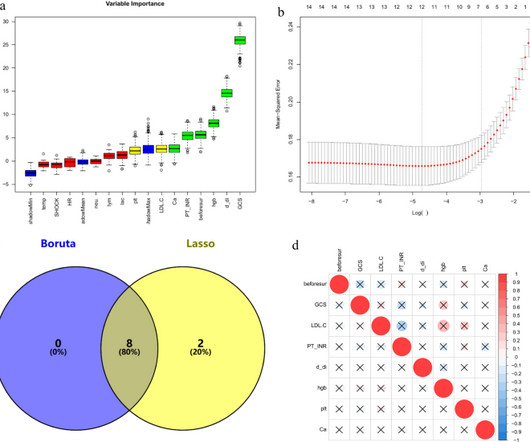
Feature selection via the Boruta and LASSO algorithms preceded the construction of predictive models using Random Forest, Decision Tree, K-Nearest Neighbors, SupportVectorMachine, LightGBM, and XGBoost.
Throughout the course of history, the significance of creating and disseminating information has been immensely crucial. Moreover, statistical inference empowers them to make informed decisions and draw meaningful conclusions based on sample data. Supportvectormachines are used to classify data and to predict continuous outcomes.
Learn how to apply state-of-the-art clustering algorithms efficiently and boost your machine-learning skills.Image source: unsplash.com. Each book is a unique piece of information, and your goal is to organize them based on their characteristics. You find yourself in a vast library with countless books scattered on the shelves.
Machine learning, computer vision, and signal processing techniques have been extensively explored to address this problem by leveraging information from various multimedia data sources. Fundamental frequency is related to voice pitch and can provide information about emotional state.
Examples include: Spam vs. Not Spam Disease Positive vs. Negative Fraudulent Transaction vs. Legitimate Transaction Popular algorithms for binary classification include Logistic Regression, SupportVectorMachines (SVM), and Decision Trees. These models can detect subtle patterns that might be missed by human radiologists.
Their application spans a wide array of tasks, from categorizing information to predicting future trends, making them an essential component of modern artificial intelligence. What are machine learning algorithms? Nave Bayes: A straightforward classifier leveraging the independence of features.
It includes both traditional machine learning algorithms like linear regression and k-means clustering, as well as more advanced techniques like neural networks and gradient boosting. Many of the algorithms included in SmartCore provide detailed information about the models they build, including feature importance, decision paths, and more.
Using the model’s results, three typical machine learning surrogate models—Long Short-Term Memory (LSTM), Random Forest (RF), and SupportVectorMachine (SVM)—are developed to predict the water level at the key control section of Changsha Station.
ID3 (Iterative Dichotomiser 3): A basic model that uses information gain but is prone to overfitting. Intuitive visualization: Create clear visual aids to convey information readily. Gradient boosting machines (GBM): Sequentially builds decision models to enhance predictive power.
Definition of supervised learning At its core, supervised learning utilizes labeled data to inform a machine learning model. SupportVectorMachines: A method that finds the hyperplane separating different classes with the largest margin.
With the growing use of machine learning (ML) models to handle, store, and manage data, the efficiency and impact of enterprises have also increased. Categorical data is one such form of information that is handled by ML models using different methods. This conversion allows models to process the data and extract valuable information.
Summary: SupportVectorMachine (SVM) is a supervised Machine Learning algorithm used for classification and regression tasks. Introduction Machine Learning has revolutionised various industries by enabling systems to learn from data and make informed decisions. What is the SVM Algorithm in Machine Learning?
Data mining can help governments identify areas of concern, allocate resources, and make informed policy decisions. In data mining, popular algorithms include decision trees, supportvectormachines, and k-means clustering. It can be used in healthcare to improve patient outcomes and identify potential health risks.
Develop Hybrid Models Combine traditional analytical methods with modern algorithms such as decision trees, neural networks, and supportvectormachines. Step 1: Assess Current Data Capabilities Data analytics can help improve data quality, accuracy, and availability and find incomplete data sets or isolated information.
CDS Professor Andrew Gordon Wilson and CDS PhD student Yilun Kuang have a Spotlighted paper on using Bayesian optimization informed by generative models of evolving antibody sequences to more efficiently design effective therapeutic antibodies.
The classification model learns from the training data, identifying the distinguishing characteristics between each class, enabling it to make informed predictions. Classification in machine learning can be a versatile tool with numerous applications across various industries. Next, you need to select a model.
One relies on structured, labeled information to make predictions, while the other uncovers hidden patterns in raw data. Understanding their differences is essential for businesses looking to implement machine learning effectively. The model uses this information to learn the relationship between input and output.
Feature Extraction Feature Extraction is basically extracting relevant information from the pre-processed image that can be used for classification. Artificial Neural Networks (ANNs) are machine learning models that can be used for HDR. ANNs consist of layers of interconnected nodes, which process and transmit information.
These branches include supervised and unsupervised learning, as well as reinforcement learning, and within each, there are various algorithmic techniques that are used to achieve specific goals, such as linear regression, neural networks, and supportvectormachines.
Common Machine Learning Algorithms Machine learning algorithms are not limited to those mentioned below, but these are a few which are very common. Linear Regression Decision Trees SupportVectorMachines Neural Networks Clustering Algorithms (e.g., Models […]
On the other hand, artificial intelligence is the simulation of human intelligence in machines that are programmed to think and learn like humans. By leveraging advanced algorithms and machine learning techniques, IoT devices can analyze and interpret data in real-time, enabling them to make informed decisions and take autonomous actions.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? For more information, click here.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? For more information, click here.
Adding such extra information should improve the classification compared to the previous method (Principle Label Space Transformation). Correctly predicting the tags of the questions is a very challenging problem as it involves the prediction of a large number of labels among several hundred thousand possible labels.
It guarantees reliable information, essential for applications like disaster management and environmental monitoring while optimizing processing time and resource use. Tailoring the algorithm to the specific data type and application enhances performance and interpretability, facilitating clear communication and informed decision-making.
Text mining is primarily a technique in the field of Data Science that encompasses the extraction of meaningful insights and information from unstructured textual data. This helps businesses gain insights into market trends, consumer preferences, and competitive landscapes, allowing them to make informed strategic decisions.
This includes one paper from 2020 that conducted feature extraction using a denoising autoencoder alongside a deep neural network, and a flattened vector and supportvectormachines to evaluate study relevance. This study by Bui et al. This study by Bui et al.
image from lexica.art Machine learning algorithms can be used to capture gender detection from sound by learning patterns and features in the audio data that are indicative of gender differences. Data Collection: A dataset of audio samples with labeled gender information is collected. Here’s an overview of the typical process: 1.
Data-Driven Decision Making: Attribution models empower marketers to make informed, data-driven decisions, leading to more effective campaign strategies and better alignment between marketing and sales efforts. For more information on how to calculate the marginal distribution, see Zhao et al.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content