This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Hadoop systems and data lakes are frequently mentioned together. Data is loaded into the Hadoop Distributed File System (HDFS) and stored on the many computer nodes of a Hadoop cluster in deployments based on the distributed processing architecture. This implies that data that may never be needed is not wasting storage space.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
Data warehouses contain historical information that has been cleared to suit a relational plan. On the other hand, data lakes store from an extensive array of sources like real-time social media streams, Internet of Things devices, web app transactions, and user data. Engineers make use of data lakes in storing incoming data.
This data, often referred to as Big Data , encompasses information from various sources, including social media interactions, online transactions, sensor data, and more. Hadoop Distributed File System (HDFS) : HDFS is a distributed file system designed to store vast amounts of data across multiple nodes in a Hadoop cluster.
Explosion of Internet of Things (IoT) Data The proliferation of IoT devices is generating unprecedented volumes of real-time data. Staying informed about these emerging data science trends will empower professionals and organizations to harness the full potential of data in 2025 and beyond.
Simply put, it involves a diverse array of tech innovations, from artificial intelligence and machine learning to the internet of things (IoT) and wireless communication networks. But having access to weather-related information isn’t enough. Hadoop has also helped considerably with weather forecasting.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Processing frameworks like Hadoop enable efficient data analysis across clusters. Data lakes and cloud storage provide scalable solutions for large datasets.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Processing frameworks like Hadoop enable efficient data analysis across clusters. Data lakes and cloud storage provide scalable solutions for large datasets.
This flexibility allows organizations to store vast amounts of raw data without the need for extensive preprocessing, providing a comprehensive view of information. This centralization streamlines data access, facilitating more efficient analysis and reducing the challenges associated with siloed information.
Overview In the era of Big Data , organizations inundated with vast amounts of information generated from various sources. IoT Data Processing With the rise of the Internet of Things (IoT), NiFi is increasingly used to process data generated by IoT devices.
IoT (Internet of Things) Analytics Projects: IoT analytics involves processing and analyzing data from IoT devices to gain insights into device performance, usage patterns, and predictive maintenance. Pricing Management: To improve product price plans, analyze pricing information, rival pricing, and consumer behavior.
Utilizing Big Data, the Internet of Things, machine learning, artificial intelligence consulting , etc., Considering the human body generates two terabytes of data on a daily basis, from brain activity to muscle performance, scientists have a lot of information to collect and process.
Photo by Jim WATSON / AFP) (Photo by JIM WATSON/AFP via Getty Images) AFP via Getty Images Information, without order, is chaotic. Without a way to structure, govern and trust that information, enterprises risk missing the full value of their data.” Sales rose 13 percent to 74.3 billion kroner ($10.8 billion kroner.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





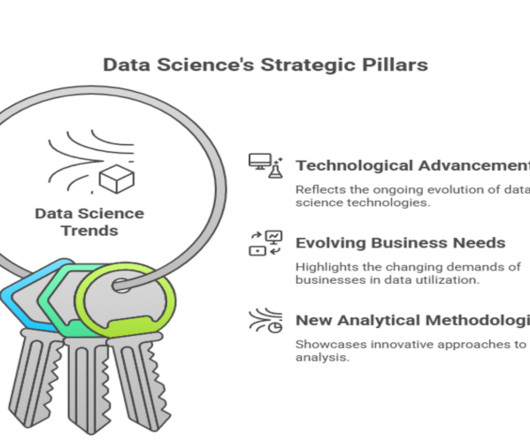






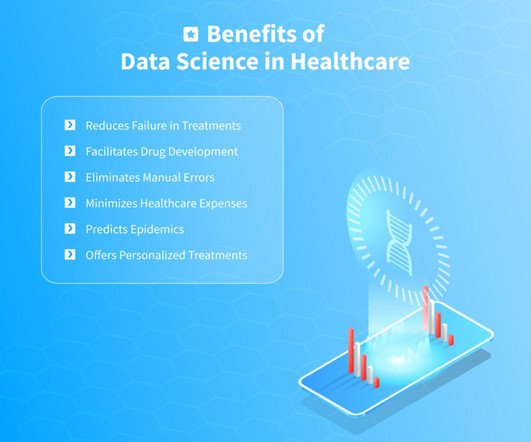







Let's personalize your content