This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Lets build an ETL pipeline that takes messy data and turns it into something actually useful. 🔗 Link to the code on GitHub What Is an Extract, Transform, Load (ETL) Pipeline? Every ETL pipeline follows the same pattern. Running the ETL Pipeline This orchestrates the entire extract, transform, load workflow.
Building the Data Pipeline Before we build our data pipeline, let’s understand the concept of ETL, which stands for Extract, Transform, and Load. ETL is a process where the data pipeline performs the following actions: Extract data from various sources. file for the ETL process. Transform data into a valid format.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
SharePoint Excel doesn’t support direct refresh from SQL Server or Synapse. You can’t natively connect an Excel file on SharePoint to a SQL-based backend and have it auto-refresh. To understand the data layer better, check out this guide on SQL pools in Azure Synapse.
Powered by Data Intelligence, Genie learns from organizational usage patterns and metadata to generate SQL, charts, and summaries grounded in trusted data. Lakebridge accelerates the migration of legacy data warehouse workloads to Azure Databricks SQL.
Recommended actions: Apply transformations such as filtering, aggregating, standardizing, and joining datasets Implement business logic and ensure schema consistency across tables Use tools like dbt, Spark, or SQL to manage and document these steps 4. Streaming: Use tools like Kafka or event-driven APIs to ingest data continuously.
For newcomers, Lakeflow Jobs is the built-in orchestrator for Lakeflow , a unified and intelligent solution for data engineering with streamlined ETL development and operations built on the Data Intelligence Platform. Lakeflow Connect in Jobs is now generally available for customers.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
For most organizations, this gap remains stubbornly wide, with business teams trapped in endless cycles—decoding metric definitions and hunting for the correct data sources to manually craft each SQL query. In Part 1, we focus on building a Text-to-SQL solution with Amazon Bedrock , a managed service for building generative AI applications.
Through natural language processing, Amazon Bedrock Knowledge Bases transforms natural language queries into SQL queries, so users can retrieve data directly from supported sources without understanding database structure or SQL syntax. We use a bastion host to connect securely to the database from the public subnet.
AI Functions in SQL: Now Faster and Multi-Modal AI Functions enable users to easily access the power of generative AI directly from within SQL. Figure 3: Document intelligence arrives at Databricks with the introduction of ai_parse in SQL.
You can also run scalable batch inference by sending a SQL query to your table. Additionally, the newly released MLflow 3 allows you to evaluate the model more comprehensively across your specific datasets.
Classic compute (workflows, Declarative Pipelines, SQL Warehouse, etc.) In general, you can add tags to two kinds of resources: Compute Resources: Includes SQL Warehouse, jobs, instance pools, etc. SQL Warehouse Compute: You can set the tags for a SQL Warehouse in the Advanced Options section.
Replace procedural logic and UDFs by expressing loops with standard SQL syntax. Replace procedural logic and UDFs by expressing loops with standard SQL syntax. This brings a native way to express loops and traversals in SQL, useful for working with hierarchical and graph-structured data. and Databricks Runtime 17.0
Key Skills Proficiency in SQL is essential, along with experience in data visualization tools such as Tableau or Power BI. Strong analytical skills and the ability to work with large datasets are critical, as is familiarity with data modeling and ETL processes. Familiarity with machine learning, algorithms, and statistical modeling.
Seamless Integration with Data Engineering and Analytics Automation Vibe coding is especially powerful for data engineering tasks—think ETL pipelines, data validation, and analytics automation—where describing workflows in natural language can save hours of manual coding. Explore IBM watsonx Code Assistant at IBM.
So, if you have jobs as the center of your ETL process, this seamless integration provides a more intuitive and unified experience for managing ingestion. We have also continued innovating for customers who want more customization options and use our existing ingestion solution, Auto Loader.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Run the Full DeepSeek-R1-0528 Model Locally Running the quantized version DeepSeek-R1-0528 Model locally (..)
Skip to main content Login Why Databricks Discover For Executives For Startups Lakehouse Architecture Mosaic Research Customers Customer Stories Partners Cloud Providers Databricks on AWS, Azure, GCP, and SAP Consulting & System Integrators Experts to build, deploy and migrate to Databricks Technology Partners Connect your existing tools to your (..)
It makes ETL accessible to more users - without compromising on production readiness or governance - by generating real Lakeflow pipelines under the hood. These changes build on our ongoing commitment to make Lakeflow Declarative Pipelines the most efficient option for production ETL at scale. Preview coming soon.
Structured query language (SQL) is one of the most popular programming languages, with nearly 52% of programmers using it in their work. SQL has outlasted many other programming languages due to its stability and reliability.
In Part 1 of this series, we explored how Amazon’s Worldwide Returns & ReCommerce (WWRR) organization built the Returns & ReCommerce Data Assist (RRDA)—a generative AI solution that transforms natural language questions into validated SQL queries using Amazon Bedrock Agents.
Evolution of data warehouses Data warehouses emerged in the 1980s, designed as structured data repositories conducive to high-performance SQL queries and ACID transactions. SQL performance tuning: On-the-fly optimization of data formats for diverse queries.
It eliminates fragile ETL pipelines and complex infrastructure, enabling teams to move faster and deliver intelligent applications on a unified data platform In this blog, we propose a new architecture for OLTP databases called a lakebase. Deeply integrated with the lakehouse, Lakebase simplifies operational data workflows.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 5 Ways to Transition Into AI from a Non-Tech Background You have a non-tech background?
She has experience across analytics, big data, ETL, cloud operations, and cloud infrastructure management. He has experience across analytics, big data, and ETL. In the Configure VPC and security group section, choose the VPC and subnets where your Aurora MySQL database is located, and choose the default VPC security group.
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. Thus, we use an Extract-Transform-Load (ETL) process to ingest the data.
ETL (Extract, Transform, Load): A traditional methodology primarily focused on batch processing. ELT (Extract, Load, Transform): A modern approach that reverses ETL steps for improved efficiency. SQL and scripting languages: Essential for automating data management tasks and ensuring operations are executed efficiently.
Database query language Structured Query Language (SQL) is the primary method for managing structured data. Data management SQL databases and tools like Excel frequently utilize structured data for efficient business intelligence and data tracking. The organization facilitates smooth integration into analytical platforms.
Extract, Transform, Load (ETL) The ETL process involves extracting data from various sources, transforming it into a suitable format, and loading it into data warehouses, typically utilizing batch processing. Types of data integration methods There are several methods used for data integration, each suited for different scenarios.
Familiarise yourself with ETL processes and their significance. ETL Process: Extract, Transform, Load processes that prepare data for analysis. Can You Explain the ETL Process? The ETL process involves three main steps: Extract: Data is collected from various sources. How Do You Ensure Data Quality in a Data Warehouse?
Skip to main content Login Why Databricks Discover For Executives For Startups Lakehouse Architecture Mosaic Research Customers Customer Stories Partners Cloud Providers Databricks on AWS, Azure, GCP, and SAP Consulting & System Integrators Experts to build, deploy and migrate to Databricks Technology Partners Connect your existing tools to your (..)
We also rely on Databricks for batch ETL, metadata storage and downstream analysis. All extracted referral data must be integrated into Epic, which requires seamless data formatting, validation and secure delivery. Databricks plays a critical role in pre-processing and normalizing this information before handoff to our EHR system.
Skip to main content Login Why Databricks Discover For Executives For Startups Lakehouse Architecture Mosaic Research Customers Customer Stories Partners Cloud Providers Databricks on AWS, Azure, GCP, and SAP Consulting & System Integrators Experts to build, deploy and migrate to Databricks Technology Partners Connect your existing tools to your (..)
Expanding Data Impact with Natural Language Business Intelligence To democratize analytics consumption, AI/BI also provides natural language capabilities that can empower domain experts to obtain insights without relying on technical teams equipped with traditional analysis skills, such as SQL.
Skip to main content Login Why Databricks Discover For Executives For Startups Lakehouse Architecture Mosaic Research Customers Customer Stories Partners Cloud Providers Databricks on AWS, Azure, GCP, and SAP Consulting & System Integrators Experts to build, deploy and migrate to Databricks Technology Partners Connect your existing tools to your (..)
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 5 Error Handling Patterns in Python (Beyond Try-Except) Stop letting errors crash your app.
The processes of SQL, Python scripts, and web scraping libraries such as BeautifulSoup or Scrapy are used for carrying out the data collection. Tools like Python (with pandas and NumPy), R, and ETL platforms like Apache NiFi or Talend are used for data preparation before analysis. How to Choose the Right Data Science Career Path?
Data engineers can create and manage extract, transform, and load (ETL) pipelines directly within Unified Studio using Visual ETL. It also supports unified access across different compute runtimes such as Amazon Redshift and Athena for SQL, Amazon EMR Serverless , Amazon EMR on EC2, and AWS Glue for Spark.
Technical skills Proficiency in programming languages: Familiarity with languages like C#, Java, Python, R, Ruby, Scala, and SQL is essential for building data solutions. Familiarity with ETL tools and data warehousing concepts: Knowledge of tools designed to extract, transform, and load data is crucial.
This following diagram illustrates the enhanced data extract, transform, and load (ETL) pipeline interaction with Amazon Bedrock. Instead, by using Amazon Bedrock Agents, the agent translates natural language user prompts into SQL queries.
Lakebase is a fully managed Postgres database, integrated into your Lakehouse, that will automatically sync your Delta tables without you having to write custom ETL, config IAM or Networking. Lakebase enables game developers to easily serve Lakehouse derived insight to their applications. Learn more here (updated once available).
200k+ tokens) with many SQL snippets, query results and database metadata (e.g. Hubspot), run a bunch of SQL, show them results, etc. reply snyy 5 hours ago | parent | next [–] As mentioned in the other reply, we have a cloud/on-prem offering that comes with a managed ETL pipeline built on top of our OSS offering.
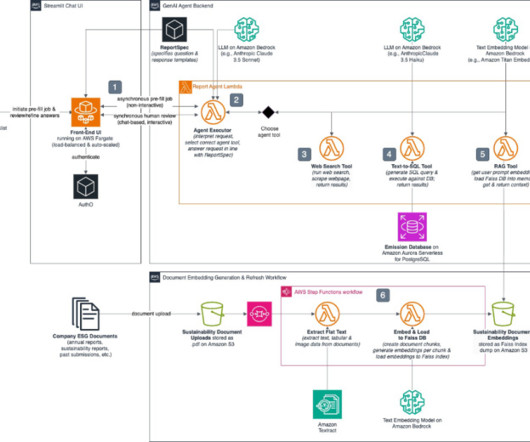
This post dives deep into the technology behind an agentic search solution using tooling with Retrieval Augmented Generation (RAG) and text-to-SQL capabilities to help customers reduce ESG reporting time by up to 75%. Text-to-SQL tool: Generates and executes SQL queries to the company’s emissions database hosted by Gardenia Technologies.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content