
How I Redesigned over 100 ETL into ELT Data Pipelines
KDnuggets
NOVEMBER 15, 2021
Learn how to level up your Data Pipelines!

KDnuggets
NOVEMBER 15, 2021
Learn how to level up your Data Pipelines!

KDnuggets
NOVEMBER 15, 2021
Learn how to level up your Data Pipelines!
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Data Science Dojo
JULY 6, 2023
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Airflow: Apache Airflow is an open-source platform for orchestrating and scheduling data pipelines.
phData
JULY 12, 2023
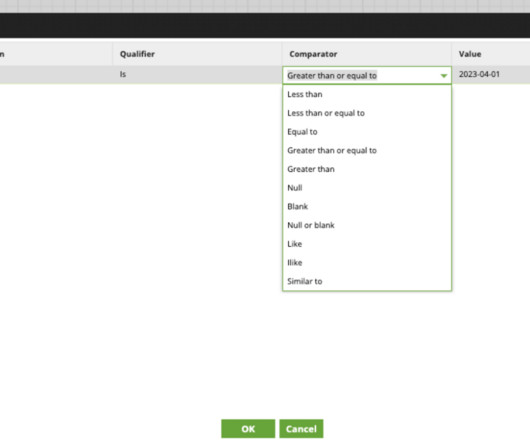
Unlike traditional methods that rely on complex SQL queries for orchestration, Matillion Jobs provides a more streamlined approach. By converting SQL scripts into Matillion Jobs , users can take advantage of the platform’s advanced features for job orchestration, scheduling, and sharing. What is Matillion ETL?
phData
JUNE 14, 2023
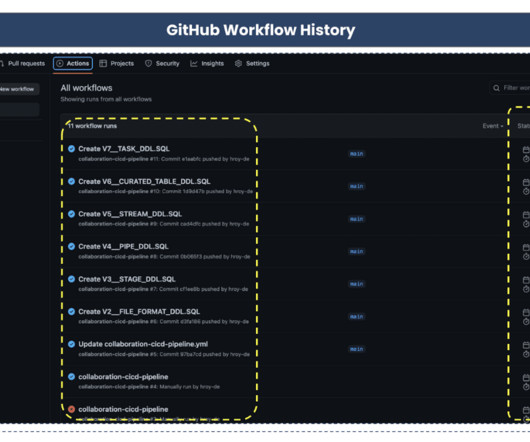
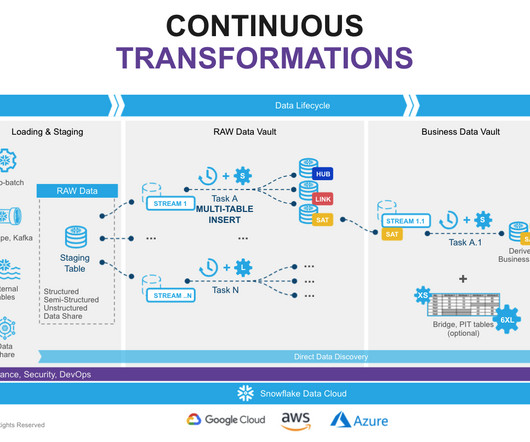
In recent years, data engineering teams working with the Snowflake Data Cloud platform have embraced the continuous integration/continuous delivery (CI/CD) software development process to develop data products and manage ETL/ELT workloads more efficiently.
phData
APRIL 21, 2023
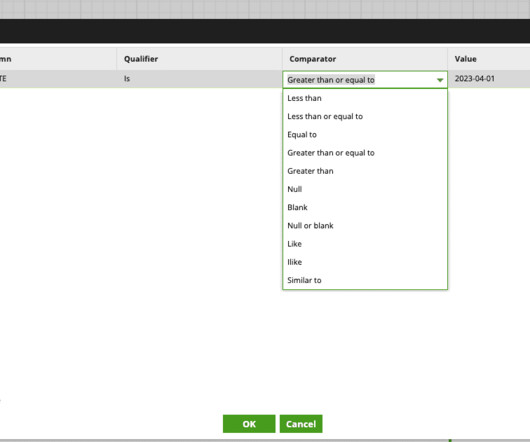
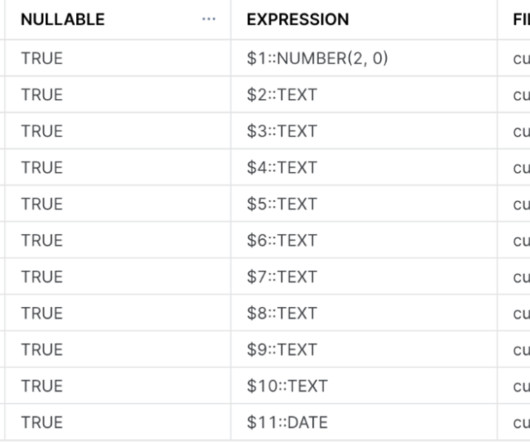
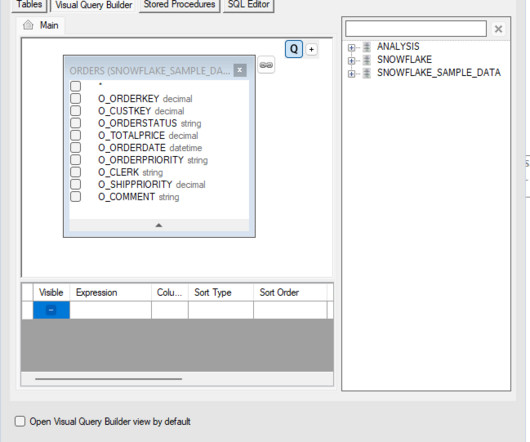
Unlike traditional methods that rely on complex SQL queries for orchestration, Matillion Jobs provide a more streamlined approach. By converting SQL scripts into Matillion Jobs , users can take advantage of the platform’s advanced features for job orchestration, scheduling, and sharing. In our case, this table is “orders.”

Analytics Vidhya
FEBRUARY 20, 2023
Introduction Azure data factory (ADF) is a cloud-based data ingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation.

Expert insights. Personalized for you.




























Let's personalize your content