

Data Integrity for AI: What’s Old is New Again
Precisely
JANUARY 9, 2025
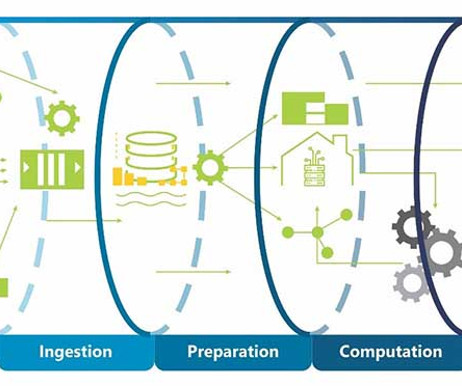
The ETL (extract, transform, and load) technology market also boomed as the means of accessing and moving that data, with the necessary translations and mappings required to get the data out of source schemas and into the new DW target schema. Then came Big Data and Hadoop! The big data boom was born, and Hadoop was its poster child.

































Let's personalize your content