

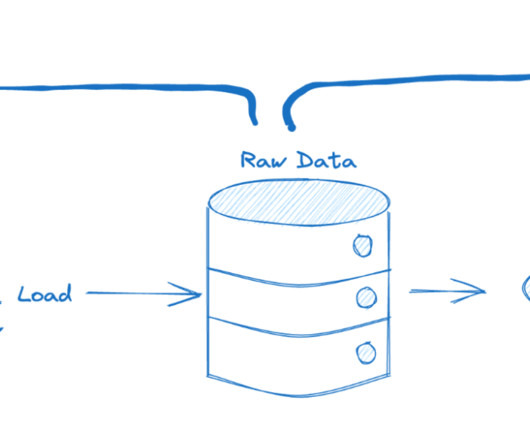
Difference between ETL and ELT Pipeline
Analytics Vidhya
MARCH 16, 2023
Apache Oozie is a workflow scheduler system for managing Hadoop jobs. It enables users to plan and carry out complex data processing workflows while handling several tasks and operations throughout the Hadoop ecosystem.



























Let's personalize your content