Essential A/B Testing Course for Data Science
KDnuggets
FEBRUARY 22, 2023
The course explains the core foundations and experiment design process for A/B testing, along with the case studies.

KDnuggets
FEBRUARY 22, 2023
The course explains the core foundations and experiment design process for A/B testing, along with the case studies.

insideBIGDATA
FEBRUARY 22, 2023
Google Cloud worked with IDC on multiple studies involving global organizations across industries in order to explore how data leaders are successfully addressing key data and AI challenges. The company compiled the results in its 2023 Data and AI Trends report. In it, you'll find the metrics-rich research behind the top five data and AI trends, along with tips and customer examples for incorporating them into your plans.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
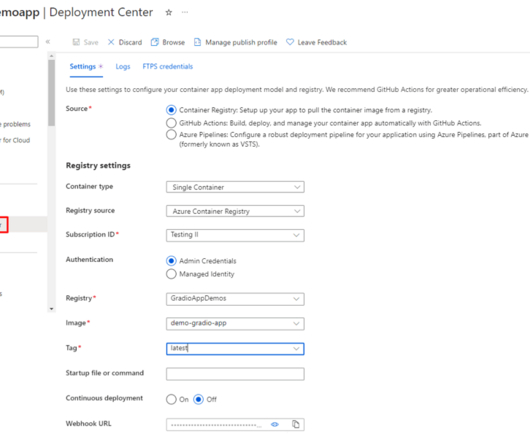
Data Science Dojo
FEBRUARY 22, 2023
In this step-by-step guide, learn how to deploy a web app for Gradio on Azure with Docker. This blog covers everything from Azure Container Registry to Azure Web Apps, with a step-by-step tutorial for beginners. ‘ I was searching for ways to deploy a Gradio application on Azure, but there wasn’t much information to be found online. After some digging, I realized that I could use Docker to deploy custom Python web applications, which was perfect since I had neither the time nor the ex

Machine Learning Mastery
FEBRUARY 23, 2023
When you build and train a PyTorch deep learning model, you can provide the training data in several different ways. Ultimately, a PyTorch model works like a function that takes a PyTorch tensor and returns you another tensor. You have a lot of freedom in how to get the input tensors. Probably the easiest is […] The post Training a PyTorch Model with DataLoader and Dataset appeared first on MachineLearningMastery.com.

Speaker: Tamara Fingerlin, Developer Advocate
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
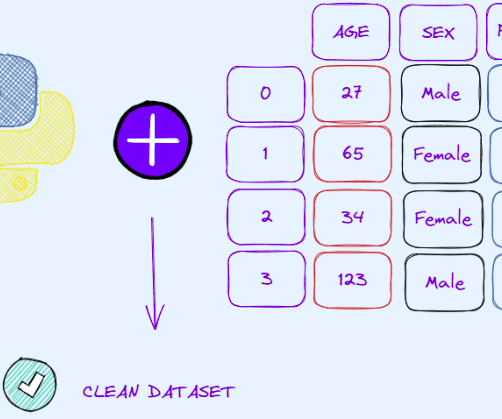
KDnuggets
FEBRUARY 21, 2023
An intuitive guide that will help you to prepare and preprocess your dataset before applying the machine learning model.

insideBIGDATA
FEBRUARY 23, 2023
Here’s a new title that is a “must have” for any data scientist who uses the R language. It’s a wonderful learning resource for tree-based techniques in statistical learning, one that’s become my go-to text when I find the need to do a deep dive into various ML topic areas for my work.
Data Science Current brings together the best content for data science professionals from the widest variety of thought leaders.

Machine Learning Mastery
FEBRUARY 21, 2023
Training a neural network or large deep learning model is a difficult optimization task. The classical algorithm to train neural networks is called stochastic gradient descent. It has been well established that you can achieve increased performance and faster training on some problems by using a learning rate that changes during training. In this post, […] The post Using Learning Rate Schedule in PyTorch Training appeared first on MachineLearningMastery.com.

KDnuggets
FEBRUARY 23, 2023
A short review of developments in the AI world.

insideBIGDATA
FEBRUARY 21, 2023
Welcome to insideBIGDATA’s “Heard on the Street” round-up column! In this regular feature, we highlight thought-leadership commentaries from members of the big data ecosystem. Each edition covers the trends of the day with compelling perspectives that can provide important insights to give you a competitive advantage in the marketplace.

Analytics Vidhya
FEBRUARY 24, 2023
Introduction Fake banknotes can easily become a problem for both small and large business enterprises. Being able to identify these banknotes when they are not genuine is very vital. This process could be time-consuming for everyday business professionals and individuals dealing with cash. This calls for a need to achieve this goal via automation. Thanks […] The post Deep Learning in Banking: Colombian Peso Banknote Detection appeared first on Analytics Vidhya.

Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.

Machine Learning Mastery
FEBRUARY 19, 2023
Dropout is a simple and powerful regularization technique for neural networks and deep learning models. In this post, you will discover the Dropout regularization technique and how to apply it to your models in PyTorch models. After reading this post, you will know: How the Dropout regularization technique works How to use Dropout on your […] The post Using Dropout Regularization in PyTorch Models appeared first on MachineLearningMastery.com.

KDnuggets
FEBRUARY 23, 2023
Knowing these 5 statistical paradoxes is essential for data scientists to improve their analyses and machine learning models.

insideBIGDATA
FEBRUARY 24, 2023
The Pretrained Foundation Models (PFMs) are regarded as the foundation for various downstream tasks with different data modalities. A pretrained foundation model, such as BERT, GPT-3, MAE, DALLE-E, and ChatGPT, is trained on large-scale data which provides a reasonable parameter initialization for a wide range of downstream applications.
Analytics Vidhya
FEBRUARY 22, 2023
Introduction Data replication is also known as database replication, which is copying data to ensure that all information remains consistent across all data resources in real-time. data replication is like a safety net that keeps your information safe from disappearing or falling through the cracks. In most cases, data alters. It is constantly changing.

Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Data Science Blog
FEBRUARY 23, 2023
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machine learning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves. The increasing number of papers on deep learning demonstrate that researches on AI have developed rapidly recently.

KDnuggets
FEBRUARY 20, 2023
Learn how pre-processing improves the performance of machine learning models.

insideBIGDATA
FEBRUARY 23, 2023
In this special guest feature, Robert Lowe, CEO of Wellspring Worldwide, looks into how data strength needs to be the key focal area as the government begins to act on the CHIPS Act and future innovation efforts.

Analytics Vidhya
FEBRUARY 23, 2023
Introduction Data analysts with the technological know-how to tackle challenging problems are data scientists. They collect, analyze, interpret data, and handle statistics, mathematics, and computer science. They are accountable for providing insights that go beyond statistical analyses. A data scientist’s function is highly transferable, and data scientist employment is available in private and public sectors, […] The post Step-by-step Guide to Become a Data Scientist in Retail Indu

Speaker: Frank Taliano
Documents are the backbone of enterprise operations, but they are also a common source of inefficiency. From buried insights to manual handoffs, document-based workflows can quietly stall decision-making and drain resources. For large, complex organizations, legacy systems and siloed processes create friction that AI is uniquely positioned to resolve.

databricks
FEBRUARY 23, 2023
In the previous article Prescriptive Guidance for Implementing a Data Vault Model on the Databricks Lakehouse Platform, we explained core concepts of data.
KDnuggets
FEBRUARY 24, 2023
This article will discuss SQL visualization, its role in augmenting the modern-day data engineer, and five categories of SQL visualization tools.
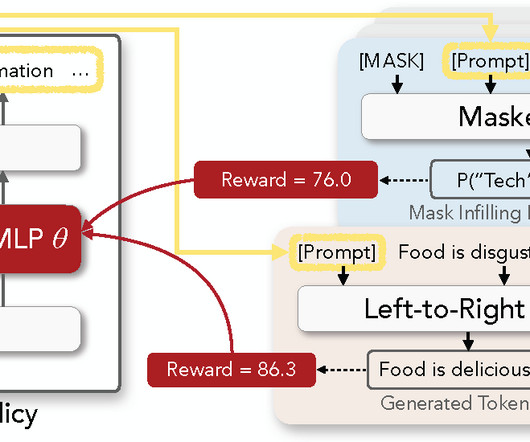
ML @ CMU
FEBRUARY 24, 2023
Figure 1 : Overview of RL Prompt for discrete prompt optimization. All language models (LMs) are frozen. We build our policy network by training a task-specific multi-layer perceptron (MLP) network inserted into a frozen pre-trained LM. The figure above illustrates 1) generation of a prompt ( left ), 2) example usages in a masked LM for classification ( top right ) and a left-to-right LM for generation ( bottom right ), and 3) update of the MLP using RL reward signals ( red arrows ).

Analytics Vidhya
FEBRUARY 22, 2023
Introduction From the 2000s onward, Many convolutional neural networks have been emerging, trying to push the limits of their antecedents by applying state-of-the-art techniques. The ultimate goal of these deep learning algorithms is to mimic the human eye’s capacity to perceive the surrounding environment. Image classification, object detection, optical character recognition, and image segmentation tasks […] The post Mask R-CNN for Instance Segmentation Using Pytorch appeared first

Speaker: Chris Townsend, VP of Product Marketing, Wellspring
Over the past decade, companies have embraced innovation with enthusiasm—Chief Innovation Officers have been hired, and in-house incubators, accelerators, and co-creation labs have been launched. CEOs have spoken with passion about “making everyone an innovator” and the need “to disrupt our own business.” But after years of experimentation, senior leaders are asking: Is this still just an experiment, or are we in it for the long haul?

databricks
FEBRUARY 21, 2023
Many large enterprises have used Teradata data warehouses for years, but the storage and processing costs of on-premises infrastructure severely restricted who could.

KDnuggets
FEBRUARY 21, 2023
SQL is a must-known programming language for data people, and many modern jobs have SQL as a prerequisite. Here are material collections to prepare for your SQL interview.

Data Science Dojo
FEBRUARY 18, 2023
This blog outlines a collection of 12 AI tools that can assist with day-to-day activities and make tasks more efficient and streamlined. The development of Artificial Intelligence has gone through several phases over the years. It all started in the 1950s and 1960s with rule-based systems and symbolic reasoning. In the 1970s and 1980s, AI research shifted to knowledge-based systems and expert systems.

Analytics Vidhya
FEBRUARY 24, 2023
Introduction Are you interested in learning about Apache Spark and how it has transformed big data processing? Or maybe you’re curious about how to implement a neural network using PyTorch. Or perhaps you want to explore the exciting world of AI and its career opportunities? Whatever your interests, Analytics Vidhya’s DataHour sessions have got you […] The post DataHour: Your Free Gateway to the World of Data Science and Technology appeared first on Analytics Vidhya.

Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m

databricks
FEBRUARY 20, 2023
Among all the rapid changes brought about by the pandemic, perhaps the most significant has been the emergence of data as a critical.
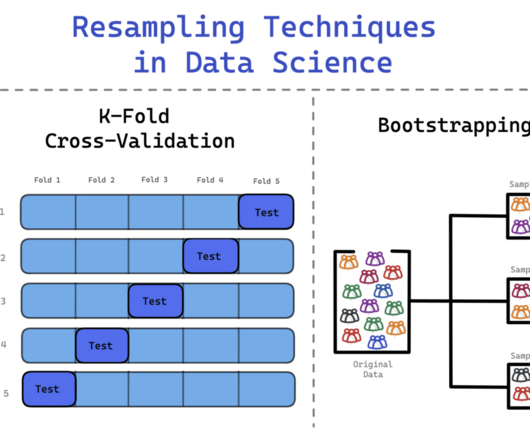
KDnuggets
FEBRUARY 20, 2023
Resampling and how you can use it to improve the overall performance of your models.

Adrian Bridgwater for Forbes
FEBRUARY 22, 2023
Clouds need to get cleaner. In what is something of a virtual-to-physical paradox, we are now thinking more clearly about the cost of real cloud computing to the planet, despite it being an essentially abstracted virtual service delivery methodology of ephemeral IT assets and functions.

Analytics Vidhya
FEBRUARY 23, 2023
Introduction Big Data is a large and complex dataset generated by various sources and grows exponentially. It is so extensive and diverse that traditional data processing methods cannot handle it. The volume, velocity, and variety of Big Data can make it difficult to process and analyze. Still, it provides valuable insights and information that can […] The post Top 20 Big Data Tools Used By Professionals in 2023 appeared first on Analytics Vidhya.

Speaker: Tamara Fingerlin, Developer Advocate
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!

Expert insights. Personalized for you.






Let's personalize your content