This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Rapid Automatic Keyword Extraction(RAKE) is a Domain-Independent keyword extraction algorithm in NaturalLanguageProcessing. It is an Individual document-oriented dynamic Information retrieval method. The post Rapid Keyword Extraction (RAKE) Algorithm in NaturalLanguageProcessing appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon Overview Sentence classification is one of the simplest NLP tasks that have a wide range of applications including document classification, spam filtering, and sentiment analysis. A sentence is classified into a class in sentence classification.
The post Latent Semantic Analysis and its Uses in NaturalLanguageProcessing appeared first on Analytics Vidhya. Textual data, even though very important, vary considerably in lexical and morphological standpoints. Different people express themselves quite differently when it comes to […].
NaturalLanguageProcessing (NLP) is revolutionizing the way we interact with technology. By enabling computers to understand and respond to human language, NLP opens up a world of possibilitiesfrom enhancing user experiences in chatbots to improving the accuracy of search engines.
Introduction DocVQA (Document Visual Question Answering) is a research field in computer vision and naturallanguageprocessing that focuses on developing algorithms to answer questions related to the content of a document, like a scanned document or an image of a text document.
This is where the term frequency-inverse document frequency (TF-IDF) technique in NaturalLanguageProcessing (NLP) comes into play. Introduction Understanding the significance of a word in a text is crucial for analyzing and interpreting large volumes of data. appeared first on Analytics Vidhya.
Introduction In the ever-evolving field of naturallanguageprocessing and artificial intelligence, the ability to extract valuable insights from unstructured data sources, like scientific PDFs, has become increasingly critical.
Naturallanguageprocessing (NLP) is a fascinating field at the intersection of computer science and linguistics, enabling machines to interpret and engage with human language. What is naturallanguageprocessing (NLP)? Identifying spam and filtering digital communication.
Introduction In the field of NaturalLanguageProcessing i.e., NLP, Lemmatization and Stemming are Text Normalization techniques. These techniques are used to prepare words, text, and documents for further processing. Languages such as English, Hindi consists of several words which are often derived […].
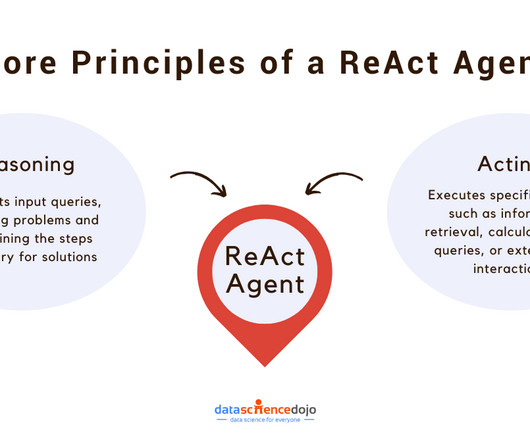
You can find more details about necessary headers in your API documentation. While other approaches like OpenAPI toolkit , Gorilla , RestGPT , and API chains exist, the Requests Toolkit leveraging a LangGraph-based ReAct agent seems to be the most effective, and reliable way to integrate naturallanguageprocessing with API interactions.
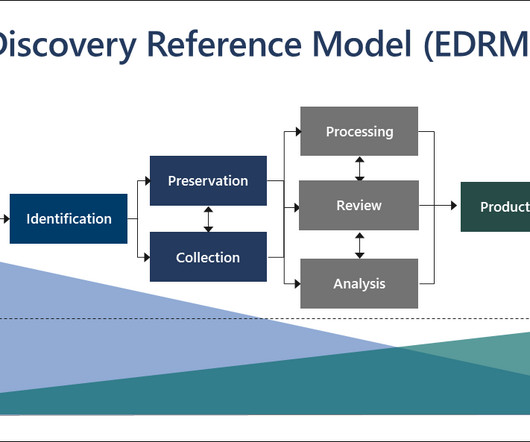
It is the process of identifying, collecting, and producing electronically stored information (ESI) in response to a request for production in a lawsuit or investigation. Anyhow, with the exponential growth of digital data, manual document review can be a challenging task.
Introduction NLP (NaturalLanguageProcessing) can help us to understand huge amounts of text data. Instead of going through a huge amount of documents by hand and reading them manually, we can make use of these techniques to speed up our understanding and get to the main messages quickly.
Transformer based language models such as BERT are really good at understanding the semantic context because they were designed specifically for that purpose. How can we use BERT to classify long text documents? BERT outperforms all NLP baselines, but as we say in the scientific community, “no free lunch”.
Traditional keyword-based search mechanisms are often insufficient for locating relevant documents efficiently, requiring extensive manual review to extract meaningful insights. This solution improves the findability and accessibility of archival records by automating metadata enrichment, document classification, and summarization.
Introduction Transformers are revolutionizing naturallanguageprocessing, providing accurate text representations by capturing word relationships. The adaptability of transformers makes these models invaluable for handling various document formats. Applications span industries like law, finance, and academia.
Intelligent documentprocessing (IDP) is transforming the way businesses manage their documentation and data management processes. By harnessing the power of emerging technologies, organizations can automate the extraction and handling of data from various document types, significantly enhancing operational workflows.
Introduction A highly effective method in machine learning and naturallanguageprocessing is topic modeling. A corpus of text is an example of a collection of documents. This technique involves finding abstract subjects that appear there.
LlamaIndex is an orchestration framework for large language model (LLM) applications. LLMs like GPT-4 are pre-trained on massive public datasets, allowing for incredible naturallanguageprocessing capabilities out of the box. The data is converted into a simple document format that is easy for LlamaIndex to process.
Introduction Innovative techniques continually reshape how machines understand and generate human language in the rapidly evolving landscape of naturallanguageprocessing.
The banking industry has long struggled with the inefficiencies associated with repetitive processes such as information extraction, document review, and auditing. This post is co-written with Ken Tsui, Edward Tsoi and Mickey Yip from Apoidea Group. SuperAcc has demonstrated significant improvements in the banking sector.
In the field of software development, generative AI is already being used to automate tasks such as code generation, bug detection, and documentation. For example: Prompt: “Recommend a library for naturallanguageprocessing.” Prompt: "Generate documentation for the following function."
Follow this overview of NaturalLanguage Generation covering its applications in theory and practice. The evolution of NLG architecture is also described from simple gap-filling to dynamic document creation along with a summary of the most popular NLG models.
Over the past few years, a shift has shifted from NaturalLanguageProcessing (NLP) to the emergence of Large Language Models (LLMs). Entity recognition: It reduces human error by classifying documents and minimizing manual and repetitive work.
Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB. The knowledge base architecture focuses on processing and storing agronomic data, providing quick and reliable access to critical information. What corn hybrids do you suggest for my field?”.
By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content. This approach narrows down the search space to the most relevant documents or passages, reducing noise and irrelevant information.
The UAE’s commitment to developing cutting-edge technology like NOOR and Falcon demonstrates its determination to be a global leader in the field of AI and naturallanguageprocessing. This initiative addresses the gap in the availability of advanced language models for Arabic speakers.
In today’s data-driven business landscape, the ability to efficiently extract and process information from a wide range of documents is crucial for informed decision-making and maintaining a competitive edge. Confidence scores and human review Maintaining data accuracy and quality is paramount in any documentprocessing solution.
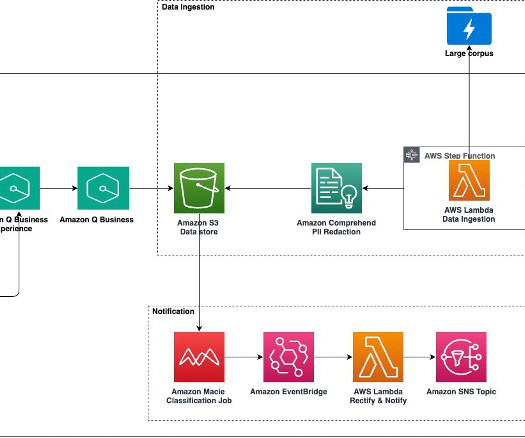
Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive. The Process Data Lambda function redacts sensitive data through Amazon Comprehend.
Tools like LangChain , combined with a large language model (LLM) powered by Amazon Bedrock or Amazon SageMaker JumpStart , simplify the implementation process. Implementation includes the following steps: The first step is to break down the large document, such as a book, into smaller sections, or chunks.
Unlocking efficient legal document classification with NLP fine-tuning Image Created by Author Introduction In today’s fast-paced legal industry, professionals are inundated with an ever-growing volume of complex documents — from intricate contract provisions and merger agreements to regulatory compliance records and court filings.
The learning program is typically designed for working professionals who want to learn about the advancing technological landscape of language models and learn to apply it to their work. It covers a range of topics including generative AI, LLM basics, naturallanguageprocessing, vector databases, prompt engineering, and much more.
Importance of embeddings in naturallanguageprocessing (NLP) Embeddings significantly improve naturallanguageprocessing by handling large vocabularies and establishing meaningful relationships between terms. This encapsulation allows for a deeper understanding of language beyond individual words.
NaturalLanguageProcessing Applications : Develops and refines NLP applications, ensuring they can handle language tasks effectively, such as sentiment analysis and question answering. HELM contributes to the development of AI systems that can assist in decision-making processes.
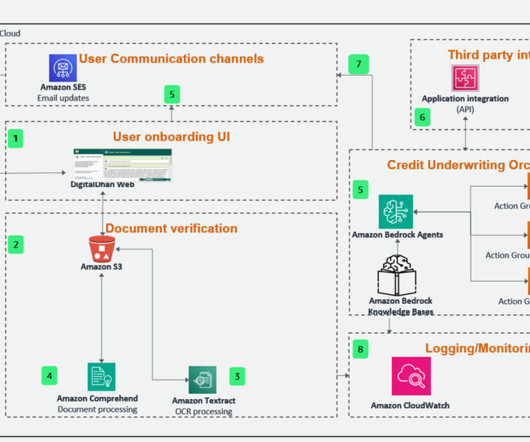
In India, the KYC verification usually involves identity verification through identification documents for Indian citizens, such as a PAN card or Aadhar card, address verification, and income verification. They have developed a solution that fully automates the customer onboarding, KYC verification, and credit underwriting process.
This new capability from Amazon Bedrock offers a unified experience for developers of all skillsets to easily automate the extraction, transformation, and generation of relevant insights from documents, images, audio, and videos to build generative AI powered applications.
Document Loaders and Utils: LangChain’s Document Loaders and Utils modules simplify data access and computation. These embeddings, along with the associated documents, are stored in a vectorstore. This vectorstore enables efficient retrieval of relevant documents based on their embeddings.
For example, if you’re building a chatbot, you can combine modules for naturallanguageprocessing (NLP), data retrieval, and user interaction. RAG Workflows RAG is a technique that helps LLMs fetch relevant information from external databases or documents to ground their responses in reality.
By taking advantage of advanced naturallanguageprocessing (NLP) capabilities and data analysis techniques, you can streamline common tasks like these in the financial industry: Automating data extraction – The manual data extraction process to analyze financial statements can be time-consuming and prone to human errors.
Large language models (LLMs) have revolutionized the field of naturallanguageprocessing, enabling machines to understand and generate human-like text with remarkable accuracy. However, despite their impressive language capabilities, LLMs are inherently limited by the data they were trained on.
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data.
Moreover, interest in small language models (SLMs) that enable resource-constrained devices to perform complex functionssuch as naturallanguageprocessing and predictive automationis growing. These documents are chunked by the application and are sent to the embedding model.
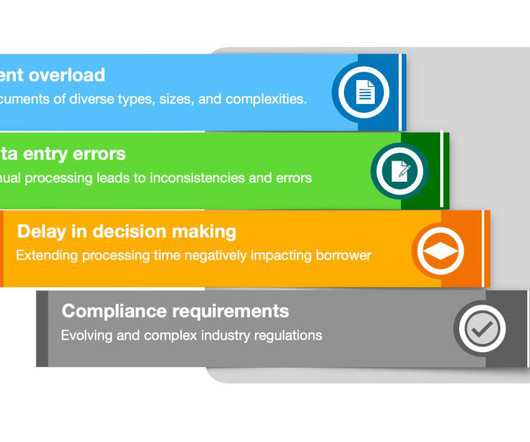
Mortgage processing is a complex, document-heavy workflow that demands accuracy, efficiency, and compliance. Recent industry surveys indicate that only about half of borrowers express satisfaction with the mortgage process, with traditional banks trailing non-bank lenders in borrower satisfaction. Why agentic IDP?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









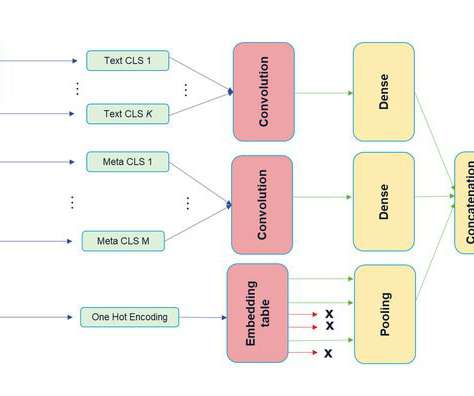





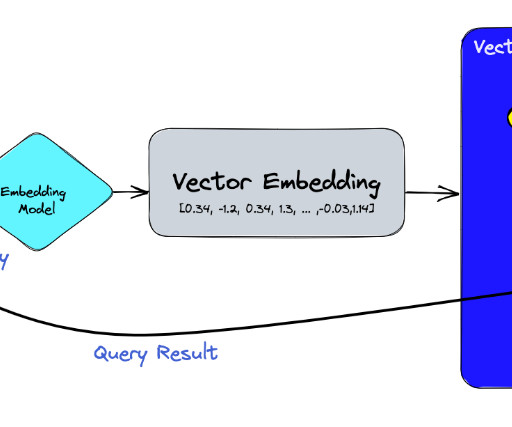
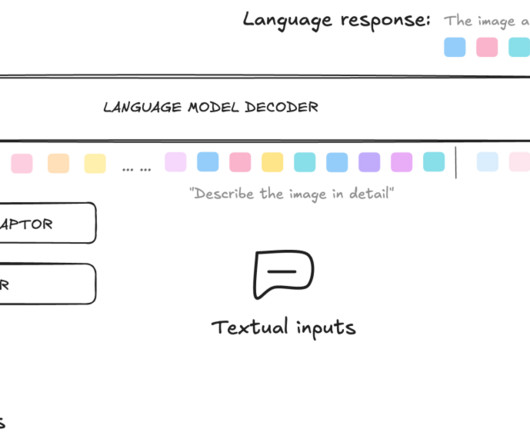




















Let's personalize your content