This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Whether it's an ML side project or adding a new feature to a enterprise production deployment, technical documentation throughout the MLOps lifecycle is vital in every project by increasing quality, transparency, and saves time in future development.
Introduction Intelligent document processing (IDP) is a technology that uses artificial intelligence (AI) and machine learning (ML) to automatically extract information from unstructured documents such as invoices, receipts, and forms.
While it is true that Machine Learning today isn’t ready for prime time in many business cases that revolve around Document Analysis, there are indeed scenarios where a pure ML approach can be considered.
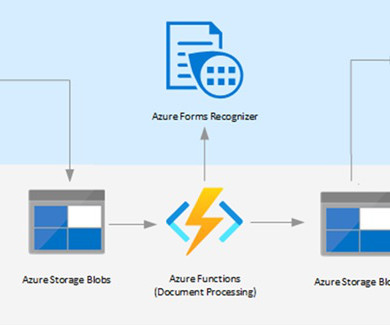
This article will provide you with a hands-on implementation on how to deploy an ML model in the Azure cloud. If you are new to Azure machine learning, I would recommend you to go through the Microsoft documentation that has been provided in the […].
We recently announced our AI-generated documentation feature, which uses large language models (LLMs) to automatically generate documentation for tables and columns in Unity.
Google’s researchers have unveiled a groundbreaking achievement – Large Language Models (LLMs) can now harness Machine Learning (ML) models and APIs with the mere aid of tool documentation.
Enterprises in industries like manufacturing, finance, and healthcare are inundated with a constant flow of documents—from financial reports and contracts to patient records and supply chain documents. An AWS Lambda function reads the Amazon Textract response and calls an Amazon Bedrock prompt flow to classify the document.
This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. Visit the session catalog to learn about all our generative AI and ML sessions.
In the mortgage servicing industry, efficient document processing can mean the difference between business growth and missed opportunities. Onity processes millions of pages across hundreds of document types annually, including legal documents such as deeds of trust where critical information is often contained within dense text.
Traditional keyword-based search mechanisms are often insufficient for locating relevant documents efficiently, requiring extensive manual review to extract meaningful insights. This solution improves the findability and accessibility of archival records by automating metadata enrichment, document classification, and summarization.
The banking industry has long struggled with the inefficiencies associated with repetitive processes such as information extraction, document review, and auditing. To further enhance the capabilities of specialized information extraction solutions, advanced ML infrastructure is essential.
Intelligent document processing (IDP) is transforming the way businesses manage their documentation and data management processes. By harnessing the power of emerging technologies, organizations can automate the extraction and handling of data from various document types, significantly enhancing operational workflows.
The new SDK is designed with a tiered user experience in mind, where the new lower-level SDK ( SageMaker Core ) provides access to full breadth of SageMaker features and configurations, allowing for greater flexibility and control for ML engineers. For the detailed list of pre-set values, refer to the SDK documentation.
In this post, we focus on one such complex workflow: document processing. Rule-based systems or specialized machine learning (ML) models often struggle with the variability of real-world documents, especially when dealing with semi-structured and unstructured data.
Our work further motivates novel directions for developing and evaluating tools to support human-ML interactions. Model explanations have been touted as crucial information to facilitate human-ML interactions in many real-world applications where end users make decisions informed by ML predictions.
AI/ML model validation plays a crucial role in the development and deployment of machine learning and artificial intelligence systems. What is AI/ML model validation? AI/ML model validation is a systematic process that ensures the reliability and accuracy of machine learning and artificial intelligence models.
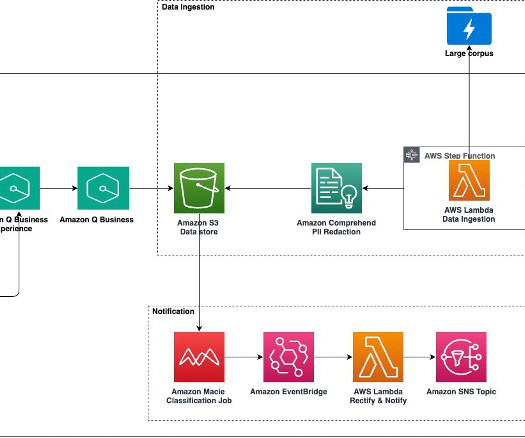
Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive. This solution uses the powerful capabilities of Amazon Q Business.
The machine learning (ML) practitioners need to iterate over these settings before finally deploying the endpoint to SageMaker for inference. Over the past 5 years, she has worked with multiple enterprise customers to set up a secure, scalable AI/ML platform built on SageMaker.
Machine learning (ML) has emerged as a powerful tool to help nonprofits expedite manual processes, quickly unlock insights from data, and accelerate mission outcomesfrom personalizing marketing materials for donors to predicting member churn and donation patterns. For a full list of custom model types, check out this documentation.
RAG workflow: Converting data to actionable knowledge RAG consists of two major steps: Ingestion Preprocessing unstructured data, which includes converting the data into text documents and splitting the documents into chunks. Document chunks are then encoded with an embedding model to convert them to document embeddings.
The platform helped the agency digitize and process forms, pictures, and other documents. The federal government agency Precise worked with needed to automate manual processes for document intake and image processing. The demand for modernization is growing, and Precise can help government agencies adopt AI/ML technologies.
You can now register machine learning (ML) models in Amazon SageMaker Model Registry with Amazon SageMaker Model Cards , making it straightforward to manage governance information for specific model versions directly in SageMaker Model Registry in just a few clicks.
The market size for multilingual content extraction and the gathering of relevant insights from unstructured documents (such as images, forms, and receipts) for information processing is rapidly increasing. These languages might not be supported out of the box by existing document extraction software.
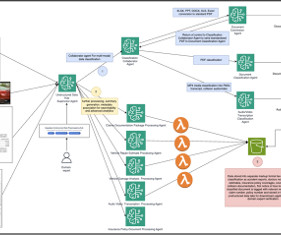
These might include claims document packages, crash event videos, chat transcripts, or policy documents. For teams processing a small volume of uniform documents, a single-agent setup might be more straightforward to implement and sufficient for basic automation.
Organizations possess extensive repositories of digital documents and data that may remain underutilized due to their unstructured and dispersed nature. Information repository – This repository holds essential documents and data that support customer service processes.
A common adoption pattern is to introduce document search tools to internal teams, especially advanced document searches based on semantic search. In a real-world scenario, organizations want to make sure their users access only documents they are entitled to access. The following diagram depicts the solution architecture.
For this example, we enter the following: You are an expert financial analyst with years of experience in summarizing complex financial documents. For this post, we use the following prompt: Summarize the following financial document for {{company_name}} with ticker symbol {{ticker_symbol}}: Please provide a brief summary that includes 1.
The following use cases are well-suited for prompt caching: Chat with document By caching the document as input context on the first request, each user query becomes more efficient, enabling simpler architectures that avoid heavier solutions like vector databases. Please follow these detailed instructions:" "nn1.
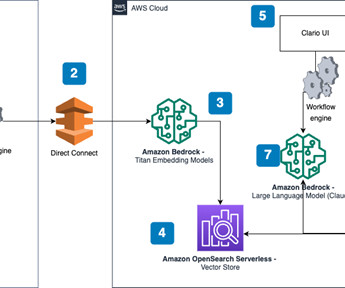
One of the critical challenges Clario faces when supporting its clients is the time-consuming process of generating documentation for clinical trials, which can take weeks. The content of these documents is largely derived from the Charter, with significant reformatting and rephrasing required.
Reproducible AI refers to the capability to duplicate machine learning (ML) processes accurately, ensuring consistent outcomes as initially intended. Consistency across ML pipelines Maintaining consistency in data across ML workflows is essential. Strategies to control or document random seeds can mitigate these effects.
The service also provides multiple query languages, including SQL and Piped Processing Language (PPL) , along with customizable relevance tuning and machine learning (ML) integration for improved result ranking. Lexical search relies on exact keyword matching between the query and documents.
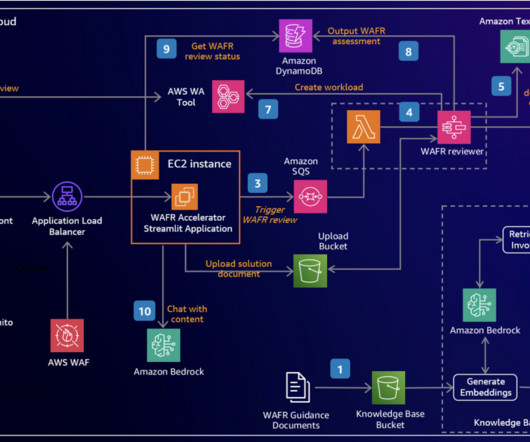
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. An interactive chat interface allows deeper exploration of both the original document and generated content.
You can try out the models with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. To learn more, refer to the API documentation. Both models support a context window of 32,000 tokens, which is roughly 50 pages of text.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
It is recommended to evaluate each framework’s documentation, performance benchmarks, and community support to determine the best fit for your distributed learning needs. The choice of framework depends on specific project requirements, existing infrastructure, and familiarity with the framework’s APIs and community resources.
As a global leader in agriculture, Syngenta has led the charge in using data science and machine learning (ML) to elevate customer experiences with an unwavering commitment to innovation. Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB.
Formalizing and documenting this invaluable resource can help organizations maintain institutional memory, drive innovation, enhance decision-making processes, and accelerate onboarding for new employees. However, effectively capturing and documenting this knowledge presents significant challenges.
This long-awaited capability is a game changer for our customers using the power of AI and machine learning (ML) inference in the cloud. The scale down to zero feature presents new opportunities for how businesses can approach their cloud-based ML operations. However, it’s possible to forget to delete these endpoints when you’re done.
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data.
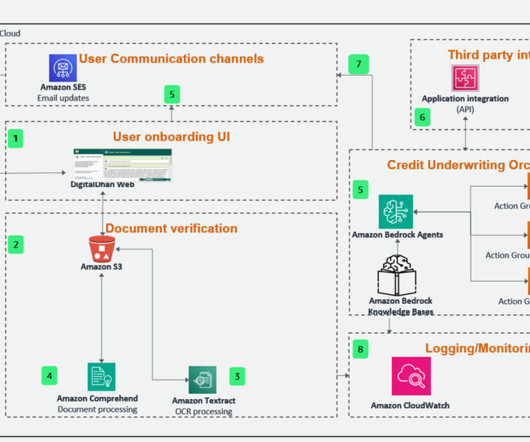
In India, the KYC verification usually involves identity verification through identification documents for Indian citizens, such as a PAN card or Aadhar card, address verification, and income verification. Amazon Textract is used to extract text information from the uploaded documents. I need a loan for 150000.
Heres how embeddings power these advanced systems: Semantic Understanding LLMs use embeddings to represent words, sentences, and entire documents in a way that captures their semantic meaning. The process enables the models to find the most relevant sections of a document or dataset, improving the accuracy and relevance of their outputs.
Similarly, when an incident occurs in IT, the responding team must provide a precise, documented history for future reference and troubleshooting. As businesses expand, they encounter a vast array of transactions that require meticulous documentation, categorization, and reconciliation.
Customers want to search through all of the data and applications across their organization, and they want to see the provenance information for all of the documents retrieved. For more details about RDF data format, refer to the W3C documentation. The following is an example of RDF triples in N-triples file format: "sales_qty_sold".
Overview of vector search and the OpenSearch Vector Engine Vector search is a technique that improves search quality by enabling similarity matching on content that has been encoded by machine learning (ML) models into vectors (numerical encodings). These benchmarks arent designed for evaluating ML models.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content