This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Boosting is a key topic in machinelearning. As a result, in this article, we are going to define and explain MachineLearning boosting. With the help of “boosting,” machinelearning models are […]. Numerous analysts are perplexed by the meaning of this phrase.
In machinelearning, few ideas have managed to unify complexity the way the periodic table once did for chemistry. Now, researchers from MIT, Microsoft, and Google are attempting to do just that with I-Con, or Information Contrastive Learning. This ballroom analogy extends to all of machinelearning.
Introduction Are you following the trend or genuinely interested in MachineLearning? Either way, you will need the right resources to TRUST, LEARN and SUCCEED. If you are unable to find the right MachineLearning resource in 2024? We are here to help.
Introduction Data annotation plays a crucial role in the field of machinelearning, enabling the development of accurate and reliable models. Definition, Tools, Types and More appeared first on Analytics Vidhya.
Epoch in machinelearning represents a fundamental concept crucial for training models effectively. By understanding how many full cycles through the training dataset the model undergoes, practitioners can refine the models learning process and enhance performance. What is epoch in machinelearning?
TLDR: In this article we will explore machinelearningdefinitions from leading experts and books, so sit back, relax, and enjoy seeing how the field’s brightest minds explain this revolutionary technology! Yet it captures the essence of what makes machinelearning revolutionary: computers figuring things out on their own.
The prototype model in machinelearning is an essential approach that empowers data scientists to develop and refine machinelearning models efficiently. What is the prototype model in machinelearning? What is model prototyping? Emphasizing continuous improvement is vital.
Model fairness in AI and machinelearning is a critical consideration in todays data-driven world. What is model fairness in AI and machinelearning? Definition of model fairness Model fairness is concerned with preventing AI predictions from reinforcing existing biases.
Precision in MachineLearning is a pivotal concept that significantly impacts how predictive models are evaluated. What is precision in machinelearning? It helps to assess the performance of machinelearning models, particularly in situations where the consequences of false positives can be severe.
Bagging in machinelearning is an innovative approach that significantly boosts the accuracy and stability of predictive models. What is bagging in machinelearning? What is bagging in machinelearning? Improved accuracy: By combining predictions, it leads to lower overall error rates.
Feature Platforms — A New Paradigm in MachineLearning Operations (MLOps) Operationalizing MachineLearning is Still Hard OpenAI introduced ChatGPT. The growth of the AI and MachineLearning (ML) industry has continued to grow at a rapid rate over recent years.
Automated machinelearning (AutoML) is revolutionizing the way organizations approach the development of machinelearning models. By streamlining and automating key processes, it enables both seasoned data scientists and newcomers to harness the power of machinelearning with greater ease and efficiency.
Transformer Architecture Definition : The transformer is the foundation of large language models. Self-Attention Definition : If there is a type of component within the transformer architecture that is mainly responsible for the success of LLMs, that is the self-attention mechanism.
Part 2: Linear Algebra Every machinelearning algorithm youll use relies on linear algebra. Part 3: Calculus When you train a machinelearning model, it learns the optimal values for parameters by optimization. You dont need to master calculus before starting machinelearning – learn it as you need it.
Phrasee, a leading innovator in brand language optimization, just released a new white paper "The Definitive Guide to Large Language Models and High-Performance Marketing Content," on how enterprise marketers can build an in-house LLM solution and use it at its full potential.
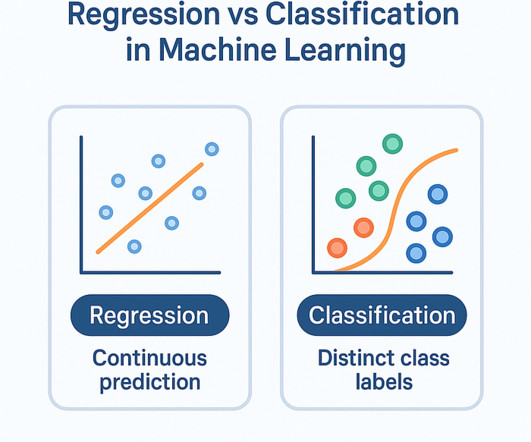
Regression vs Classification in MachineLearning Why Most Beginners Get This Wrong | M004 If youre learningMachineLearning and think supervised learning is straightforward, think again. Not just the textbook definitions, but the thinking process behind choosing the right type of model.
The true story behind the chaos at OpenAI In the summer of 2023, Ilya Sutskever, a co-founder and the chief scientist of OpenAI, was meeting with a group of new researchers at the company. By all traditional metrics, Sutskever should have felt invincible: He was the brain behind the large language
This post showcases how the TSBC built a machinelearning operations (MLOps) solution using Amazon Web Services (AWS) to streamline production model training and management to process public safety inquiries more efficiently. The pipeline definition is saved and modified for production. in British Columbia.
Regularization in machinelearning plays a crucial role in ensuring that models generalize well to new, unseen data. What is regularization in machinelearning? Understanding overfitting Overfitting happens when a model learns not just the underlying trends in the training data but also the noise.
For instance, there are many different definitions of fairness in AI. Determining which definition applies requires consultation with the affected community, clients, and end users. We created a playbook providing the right tools for testing issues like bias and privacy. But understanding how to use these tools properly is crucial.
Model drift is a vital concept in machinelearning that can significantly hamper the performance of predictive models. Model drift refers to the degradation in the accuracy and reliability of machinelearning models due to shifts in the data over time.
The answer inherently relates to the definition of memorization for LLMs and the extent to which they memorize their training data. However, even defining memorization for LLMs is challenging, and many existing definitions leave much to be desired. We argue that such a definition provides an intuitive notion of memorization.
It employs various statistical techniques to summarize and understand datasets, including: Definition and techniques: EDA encompasses methods like correlation analysis, regression modeling, and significance testing, enhancing the analyst’s understanding of data relationships.
Unfortunately, when asked to define RAG, the definitions are all over the place. In this contributed article, Magnus Revang, Chief Product Officer of Openstream.ai, points out that In the Large Language Model space, one acronym is frequently put forward as the solution to all the weaknesses. Hallucinations? Confidentiality?
Gain a beginner's perspective on artificial neural networks and deep learning with this set of 14 straight-to-the-point related key concept definitions.
Open-source machinelearning monitoring (OSMLM) plays a crucial role in the smooth and effective operation of machinelearning models across various industries. What is open-source machinelearning monitoring (OSMLM)? These tools help manage, oversee, and optimize machinelearning models.
Welcome to this comprehensive guide on Azure MachineLearning , Microsoft’s powerful cloud-based platform that’s revolutionizing how organizations build, deploy, and manage machinelearning models. This is where Azure MachineLearning shines by democratizing access to advanced AI capabilities.
Apple uses custom Trainium and Graviton artificial intelligence chips from Amazon Web Services for search services, Apple machinelearning and AI director Benoit Dupin said today at the AWS re:Invent conference (via CNBC). Dupin said that Amazon's AI chips are "reliable, definite, and able to serve …
Definition of an entity At its core, an entity signifies a distinct unit with independent existence. Entities in databases Within databases, entities are characterized by their definition as objects, such as people or locations. Definition of named entities Named entities are generally unique identifiers for single items in datasets.
Reducing the prompt context to the in-focus data domain enables greater scope for few-shot learning examples, declaration of specific business rules, and more. Augmenting data with data definitions for prompt construction Several of the optimizations noted earlier require making some of the specifics of the data domain explicit.
Probabilistic classification is a fascinating approach in machinelearning that allows models to predict the likelihood of outcomes. Probabilistic classification is a machinelearning paradigm where models generate probabilities instead of definitive class labels. What is probabilistic classification?
Initially, we have the definition of Software […]. Components of Data Engineering Object Storage Object Storage MinIO Install Object Storage MinIO Data Lake with Buckets Demo Data Lake Management Conclusion References What is Data Engineering? The post How to Implement Data Engineering in Practice? appeared first on Analytics Vidhya.
Definition Continuous Validation is the ongoing assessment of code changes using automated testing methods to ensure that new additions do not introduce errors or degrade existing functionality. Definition Continuous Delivery allows teams to ensure code is deployable at any time by automating the release process.
Keep in mind that CREATE PROCEDURE must be invoked using EXEC in order to be executed, exactly like the function definition. Tom Hamilton Stubber The emergence of Quantum ML With the use of quantum computing, more advanced artificial intelligence and machinelearning models might be created.
This method aids in finding the optimal solution of a problem, making it essential for applications ranging from machinelearning to finance. Definition and importance Convex optimization revolves around functions and constraints that exhibit specific properties.
As technology continues to evolve, particularly in machinelearning and natural language processing, the mechanisms of in-context learning are becoming increasingly sophisticated, offering personalized solutions that resonate with learners on multiple levels.
Hyperparameter tuning plays a pivotal role in the success of machinelearning models, enhancing their predictive accuracy and overall performance. As machinelearning practitioners work to develop robust models, adjusting hyperparameters becomes essential. What is hyperparameter tuning?
Independent and identically distributed data (IID) is a concept that lies at the heart of statistics and machinelearning. This means that the outcome of one variable does not affect the outcomes of others, making IID a vital condition in many statistical analyses and machinelearning models.
Feature engineering is a vital aspect of machinelearning that involves the creative and technical process of transforming data into a format that enhances model performance. The importance of feature engineering Feature engineering is crucial for improving the accuracy and reliability of machinelearning models.
The concept of a target function is an essential building block in the realm of machinelearning, influencing how algorithms interpret data and make predictions. A target function describes the relationship between input data and the desired output in machinelearning models.
Training-serving skew is a significant concern in the machinelearning domain, affecting the reliability of models in practical applications. Training-serving skew refers to the differences between the datasets used to train machinelearning models and the ones they encounter when deployed in real-world scenarios.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content