This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
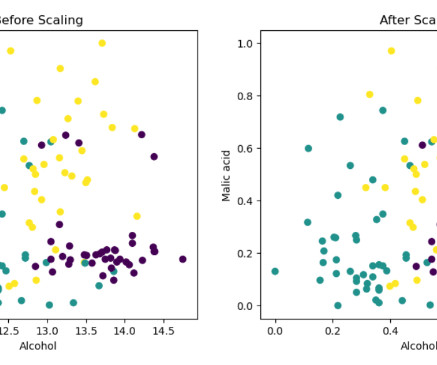
Python, with its extensive libraries and tools, offers a streamlined and efficient process for simplifying feature scaling. In the world of data science and machine learning, feature transformation plays a crucial role in achieving accurate and reliable results. What is feature scaling?
We shall look at various types of machine learning algorithms such as decisiontrees, random forest, Knearestneighbor, and naïve Bayes and how you can call their libraries in R studios, including executing the code. DecisionTree and R. Advantages of Using R for Machine Learning 1.
Created by the author with DALL E-3 Statistics, regression model, algorithm validation, Random Forest, KNearestNeighbors and Naïve Bayes— what in God’s name do all these complicated concepts have to do with you as a simple GIS analyst? Author(s): Stephen Chege-Tierra Insights Originally published on Towards AI.
We shall look at various machine learning algorithms such as decisiontrees, random forest, Knearestneighbor, and naïve Bayes and how you can install and call their libraries in R studios, including executing the code. In addition, it’s also adapted to many other programming languages, such as Python or SQL.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression DecisionTrees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? Often, these trees adhere to an elementary if/then structure.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression DecisionTrees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? Often, these trees adhere to an elementary if/then structure.
This article will explain the concept of hyperparameter tuning and the different methods that are used to perform this tuning, and their implementation using python Photo by Denisse Leon on Unsplash Table of Content Model Parameters Vs Model Hyperparameters What is hyperparameter tuning?
Python is still one of the most popular programming languages that developers flock to. In this blog, we’re going to take a look at some of the top Python libraries of 2023 and see what exactly makes them tick. In this blog, we’re going to take a look at some of the top Python libraries of 2023 and see what exactly makes them tick.
Common machine learning algorithms for supervised learning include: K-nearestneighbor (KNN) algorithm : This algorithm is a density-based classifier or regression modeling tool used for anomaly detection. Isolation forest models can be found on the free machine learning library for Python, scikit-learn.
Further, it will provide a step-by-step guide on anomaly detection Machine Learning python. An ensemble of decisiontrees is trained on both normal and anomalous data. k-NearestNeighbors (k-NN): In the supervised approach, k-NN assigns labels to instances based on their k-nearest neighbours.
For example, linear regression is typically used to predict continuous variables, while decisiontrees are great for classification and regression tasks. Decisiontrees are easy to interpret but prone to overfitting. predicting house prices), Linear Regression, DecisionTrees, or Random Forests could be good choices.
DecisionTrees: A supervised learning algorithm that creates a tree-like model of decisions and their possible consequences, used for both classification and regression tasks. Joblib: A Python library used for lightweight pipelining in Python, handy for saving and loading large data structures.
Decisiontrees are more prone to overfitting. Some algorithms that have low bias are DecisionTrees, SVM, etc. The K-NearestNeighbor Algorithm is a good example of an algorithm with low bias and high variance. So, this is how we draw a typical decisiontree. Let us see some examples.
They are: Based on shallow, simple, and interpretable machine learning models like support vector machines (SVMs), decisiontrees, or k-nearestneighbors (kNN). Relies on explicit decision boundaries or feature representations for sample selection. Libact : It is a Python package for active learning.
K-NearestNeighbors (KNN) : For small datasets, this can be a simple but effective way to identify file formats based on the similarity of their nearestneighbors. To implement our automated download system, we used Selenium in Python to control the browser using a Firefox driver.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content