This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
SupportVectorMachines (SVM) are a cornerstone of machine learning, providing powerful techniques for classifying and predicting outcomes in complex datasets. By focusing on finding the optimal decision boundary between different classes of data, SVMs have stood out in both academic research and practical applications.
Decisiontrees are a fundamental tool in machine learning, frequently used for both classification and regression tasks. Their intuitive, tree-like structure allows users to navigate complex datasets with ease, making them a popular choice for various applications in different sectors. What is a decisiontree?
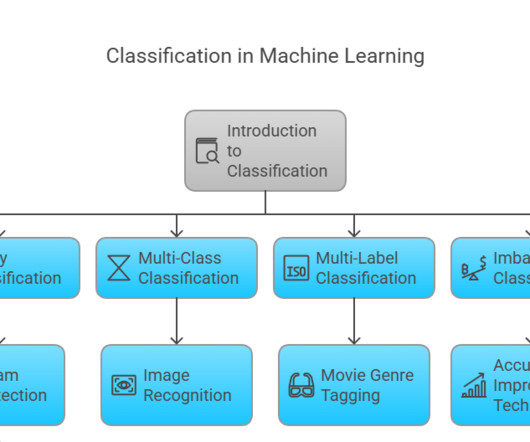
Overview of classification in machine learning Classification serves as a foundational method in machine learning, where algorithms are trained on labeled datasets to make predictions. Classification methods are vital for organizing information and making data-driven decisions.
Summary: Machine Learning algorithms enable systems to learn from data and improve over time. Key examples include Linear Regression for predicting prices, Logistic Regression for classification tasks, and DecisionTrees for decision-making. DecisionTrees visualize decision-making processes for better understanding.
Summary: Classifier in Machine Learning involves categorizing data into predefined classes using algorithms like Logistic Regression and DecisionTrees. Introduction Machine Learning has revolutionized how we process and analyse data, enabling systems to learn patterns and make predictions.
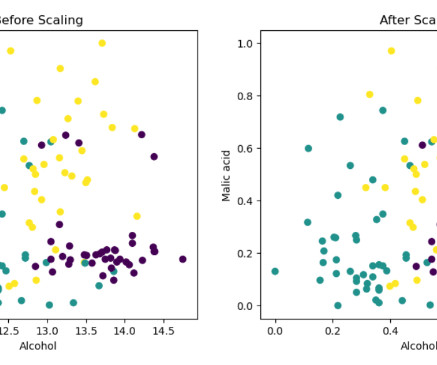
In the world of data science and machine learning, feature transformation plays a crucial role in achieving accurate and reliable results. By manipulating the input features of a dataset, we can enhance their quality, extract meaningful information, and improve the performance of predictive models.
By understanding machine learning algorithms, you can appreciate the power of this technology and how it’s changing the world around you! It’s like having a super-powered tool to sort through information and make better sense of the world. Learn in detail about machine learning algorithms 2.
Its discriminative AI capabilities allow it to analyze audio inputs, extract relevant information, and generate appropriate responses, showcasing the power of AI-driven conversational systems in enhancing user experiences and streamlining business operations.
Definition of supervised learning At its core, supervised learning utilizes labeled data to inform a machine learning model. Common algorithms used in classification tasks include: DecisionTrees: A tree-like model that makes decisions based on feature values.
Throughout the course of history, the significance of creating and disseminating information has been immensely crucial. Moreover, statistical inference empowers them to make informeddecisions and draw meaningful conclusions based on sample data. Decisiontrees are used to classify data into different categories.
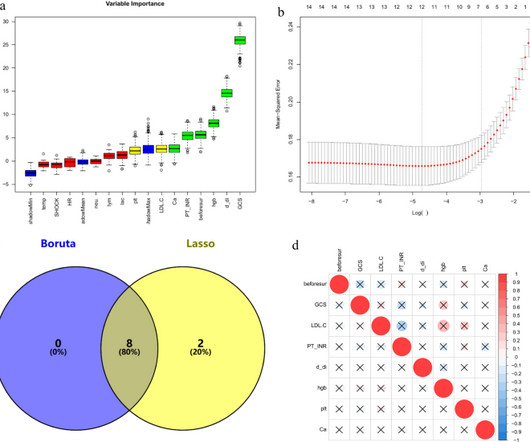
Feature selection via the Boruta and LASSO algorithms preceded the construction of predictive models using Random Forest, DecisionTree, K-Nearest Neighbors, SupportVectorMachine, LightGBM, and XGBoost.
Their application spans a wide array of tasks, from categorizing information to predicting future trends, making them an essential component of modern artificial intelligence. What are machine learning algorithms? Decisiontrees: They segment data into branches based on sequential questioning.
With the growing use of machine learning (ML) models to handle, store, and manage data, the efficiency and impact of enterprises have also increased. Categorical data is one such form of information that is handled by ML models using different methods. This conversion allows models to process the data and extract valuable information.
Data mining can help governments identify areas of concern, allocate resources, and make informed policy decisions. In data mining, popular algorithms include decisiontrees, supportvectormachines, and k-means clustering.
Develop Hybrid Models Combine traditional analytical methods with modern algorithms such as decisiontrees, neural networks, and supportvectormachines. Such an organisation that employs these practices would learn to make improved and well-informeddecisions to stay competitive.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression DecisionTrees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression DecisionTrees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
We shall look at various machine learning algorithms such as decisiontrees, random forest, K nearest neighbor, and naïve Bayes and how you can install and call their libraries in R studios, including executing the code. Radom Forest install.packages("randomForest")library(randomForest) 4. data = trainData) 5.
Summary: This blog highlights ten crucial Machine Learning algorithms to know in 2024, including linear regression, decisiontrees, and reinforcement learning. Introduction Machine Learning (ML) has rapidly evolved over the past few years, becoming an integral part of various industries, from healthcare to finance.
Feature Extraction Feature Extraction is basically extracting relevant information from the pre-processed image that can be used for classification. ANNs consist of layers of interconnected nodes, which process and transmit information. SupportVectorMachines (SVMs) are another ML models that can be used for HDR.
The classification model learns from the training data, identifying the distinguishing characteristics between each class, enabling it to make informed predictions. Classification in machine learning can be a versatile tool with numerous applications across various industries. Next, you need to select a model.
Common Machine Learning Algorithms Machine learning algorithms are not limited to those mentioned below, but these are a few which are very common. Linear Regression DecisionTreesSupportVectorMachines Neural Networks Clustering Algorithms (e.g., Models […]
One relies on structured, labeled information to make predictions, while the other uncovers hidden patterns in raw data. Understanding their differences is essential for businesses looking to implement machine learning effectively. The model uses this information to learn the relationship between input and output.
Adding such extra information should improve the classification compared to the previous method (Principle Label Space Transformation). Correctly predicting the tags of the questions is a very challenging problem as it involves the prediction of a large number of labels among several hundred thousand possible labels.
Data preprocessing tasks can include data cleaning to remove errors or inconsistencies, normalization to bring data within a consistent range, and feature engineering to extract meaningful information from raw data. AI practitioners choose an appropriate machine learning model or algorithm that aligns with the problem at hand.
Examples of supervised learning models include linear regression, decisiontrees, supportvectormachines, and neural networks. Common examples include: Linear Regression: It is the best Machine Learning model and is used for predicting continuous numerical values based on input features.
Making the right decisions in an aggressive market is crucial for your business growth and that’s where decision intelligence (DI) comes to play. In this era of information overload, utilizing the power of data and technology has become paramount to drive effective decision-making. What is decision intelligence?
On the other hand, artificial intelligence is the simulation of human intelligence in machines that are programmed to think and learn like humans. By leveraging advanced algorithms and machine learning techniques, IoT devices can analyze and interpret data in real-time, enabling them to make informeddecisions and take autonomous actions.
In the context of the MAB algorithm, each arm represents a decision that can be taken, and the reward corresponds to some measure of performance or utility. bag of words or TF-IDF vectors) and splitting the data into training and testing sets.
Demand forecasting , the art of anticipating customer needs, allows companies to optimize inventory levels, streamline production processes, and make informed strategic decisions. Data Transformation Combine existing data points to create features that might be more informative for forecasting.
Simple linear regression Multiple linear regression Polynomial regression DecisionTree regression SupportVector regression Random Forest regression Classification is a technique to predict a category. It’s a fantastic world, trust me!
In contrast, decisiontrees assume data can be split into homogeneous groups through feature thresholds. Inductive bias is crucial in ensuring that Machine Learning models can learn efficiently and make reliable predictions even with limited information by guiding how they make assumptions about the data.
Similar to a “ random forest ,” it creates “decisiontrees,” which map out the data points and randomly select an area to analyze. Isolation forest models can be found on the free machine learning library for Python, scikit-learn.
NLP tasks include machine translation, speech recognition, and sentiment analysis. Computer Vision This is a field of computer science that deals with the extraction of information from images and videos. EDA guides subsequent preprocessing steps and informs the selection of appropriate AI algorithms based on data insights.
SupportVectorMachines (SVM) : SVM is a powerful Eager Learning algorithm used for both classification and regression tasks. DecisionTrees : DecisionTrees are another example of Eager Learning algorithms that recursively split the data based on feature values during training to create a tree-like structure for prediction.
Flow analysis tools like IPFIX, NetFlow, and sFlow collect flow data, which includes information about source and destination IPs, ports, and protocols. The stack allows for customizable data visualization, enabling you to create informative dashboards and reports to understand network behaviors.
One of the goals of ML is to enable computers to process and analyze data in a way that is similar to how humans process information. Human brains are capable of processing vast amounts of information from the environment and making complex decisions based on that information. synonyms).
This creditworthiness is influenced by several key factors: Credit History: The primary source of information is usually the applicant’s credit history, which is a detailed record of all past borrowing and repayment, including late payments and defaults. This is where credit-decisioning models are essential.
It encompasses various models and techniques, applicable across industries like finance and healthcare, to drive informeddecision-making. Introduction Statistical Modeling is crucial for analysing data, identifying patterns, and making informeddecisions. Model selection requires balancing simplicity and performance.
Model-Related Hyperparameters Model-related hyperparameters are specific to the architecture and structure of a Machine Learning model. They vary significantly between model types, such as neural networks , decisiontrees, and supportvectormachines.
By understanding crucial concepts like Machine Learning, Data Mining, and Predictive Modelling, analysts can communicate effectively, collaborate with cross-functional teams, and make informeddecisions that drive business success. Data Science is the art and science of extracting valuable information from data.
Before we discuss the above related to kernels in machine learning, let’s first go over a few basic concepts: SupportVectorMachine , S upport Vectors and Linearly vs. Non-linearly Separable Data. The linear kernel is ideal for linear problems, such as logistic regression or supportvectormachines ( SVMs ).
Customer Feedback: Understanding why customers leave provides valuable information to improve your service. Model stacking involves training multiple machine learning models and using another model to combine their predictions to improve accuracy. Random Forest Classifier (rf): Ensemble method combining multiple decisiontrees.
Machine Learning Algorithms Candidates should demonstrate proficiency in a variety of Machine Learning algorithms, including linear regression, logistic regression, decisiontrees, random forests, supportvectormachines, and neural networks.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content