

Build conversational interfaces for structured data using Amazon Bedrock Knowledge Bases
JUNE 17, 2025
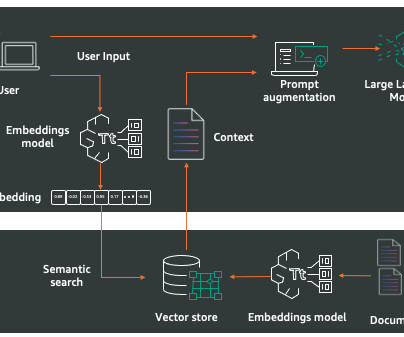
Organizations manage extensive structured data in databases and data warehouses. The system interprets database schemas and context, converting natural language questions into accurate queries while maintaining data reliability standards. Data analysts must translate business questions into SQL queries, creating workflow bottlenecks.































Let's personalize your content