This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction In the rapidly evolving landscape of data science, vector databases play a pivotal role in enabling efficient storage, retrieval, and manipulation of high-dimensional data.
Analytics databases play a crucial role in driving insights and decision-making in today’s data-driven world. By providing a structured way to analyze historical data, these databases empower organizations to uncover trends and patterns that inform strategies and optimize operations. What are analytics databases?
Database technology forms the backbone of many systems that store and manage vast amounts of data. From online retail to social networks, databases play a crucial role in the way organizations operate and make decisions. What is a database? MySQL: An open-source relational database popular for web applications.
Turso Login Open main menu Product Docs Customers Pricing Blog Schedule a call Follow us on X Join us on Discord Login Sign Up Jun 16, 2025 Working on databases from prison: How I got here, part 2. I'd never worked on relational databases, but some experience with a cache had recently sparked an interest in storage engines.
Tree structures in databases serve as a powerful means to organize and manage data, allowing for efficient retrieval and manipulation. By utilizing a hierarchical layout that resembles a tree, databases can effectively minimize search times and optimize data arrangements. What is tree structure in databases?
Database replication is a crucial process that ensures data is consistently available across various systems and locations. What is database replication? Database replication involves creating copies of data across different servers or databases, which ensures that all users and applications have access to the same data at all times.
Introduction SQL (Structured Query Language) is an important topic to understand while working with databases. It allows us to interact with databases efficiently. Data Definition Language (DDL) commands stand out among its many functions.
Introduction ALTER command is one of the most important SQL functions to know for database manipulation and management. This Data Definition Language (DDL) command can alter existing tables by adding, removing, or updating columns, constraints, and indexes.
Databricks, the Data and AI company, today announced it has entered into a definitive agreement to acquire MosaicML, a leading generative AI platform. Together, Databricks and MosaicML will make generative AI accessible for every organization, enabling them to build, own and secure generative AI models with their own data.
Database Management Systems (DBMS) are indispensable in today’s data-driven world. Beyond data storage, DBMS performs crucial functions such as data definition, manipulation, administration, and security.
While Python and R are popular for analysis and machine learning, SQL and database management are often overlooked. However, data is typically stored in databases and requires SQL or business intelligence tools for access. In this guide, we provide a comprehensive overview of various types of databases and their differences.
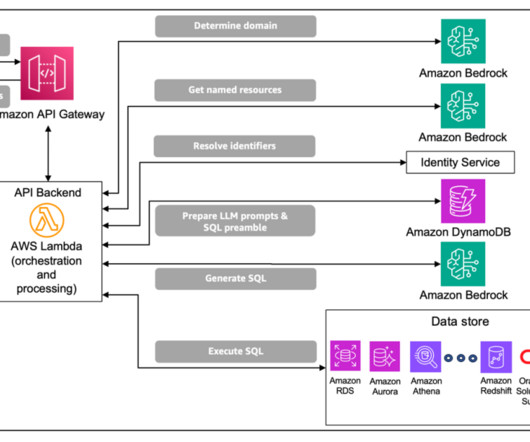
These tables house complex domain-specific schemas, with instances of nested tables and multi-dimensional data that require complex database queries and domain-specific knowledge for data retrieval. The solution uses the data domain to construct prompt inputs for the generative LLM.
When you’ve been involved in data management for as long as I have, things are definitely bound to change. Back when I started in IT, IMS was the primary database system used at most big enterprises and most of the computing was done on mainframe systems. […]. And things have changed, quite a lot, in fact.
What is an online transaction processing database (OLTP)? But the true power of OLTP databases lies beyond the mere execution of transactions, and delving into their inner workings is to unravel a complex tapestry of data management, high-performance computing, and real-time responsiveness.
Definition of an entity At its core, an entity signifies a distinct unit with independent existence. Entity types in different contexts Entities can be classified in several contexts, notably: Technology: Represents components within data models, databases, and communication frameworks.
This type of data maintains a clear structure, usually in rows and columns, which makes it easy to store and retrieve using database systems. Definition and characteristics of structured data Structured data is typically characterized by its organization within fixed fields in databases.
For instance, a sales department may maintain its own database that is incompatible with the accounting department’s system. This can involve creating a unified database accessible to all relevant stakeholders. The post Understanding Data Silos: Definition, Challenges, and Solutions appeared first on Pickl.AI.
Yet there is still no definitivedatabase of the number of crashes or fatalities caused by it. Distracted driving is a worsening problem, safety experts say.
Topics range from basic definitions to complex query optimization. MySQL is a key tool in data management and analytics. This guide presents over 30 MySQL interview questions, covering both theory and practical skills.
It is a programming language used to manipulate data stored in relational databases. Here are some essential SQL concepts that every data scientist should know: First, understanding the syntax of SQL statements is essential in order to retrieve, modify or delete information from databases.
For corporations, creating a reliable and easy-to-use corporate database is a vital part of developing and maintaining a smoothly-running operation. From keeping customer information private to ensuring that financial data is safe and secure, corporate databases can play an essential role in a corporation’s ability to succeed.
The SQL language, or Structured Query Language, is essential for managing and manipulating relational databases. It was designed to retrieve and manage data stored in relational databases. This versatile programming language is widely used by database administrators, developers, and data analysts.
A data dictionary, also known as a data definition matrix, contains comprehensive data about the company’s data, such as the definition of data elements, their meanings, and allowable values. Let’s start by answering the first thing that comes to mind: What is a data dictionary? The dictionary, in essence, is.
This article will explore the definition and offer essential tips to businesses looking to leverage custom software application development services to drive their operations forward. This includes user interface design, database design, and data flow diagrams, among others. What is custom software application development?
ACID properties stand as cornerstone principles in the realm of transaction processing, ensuring data integrity and reliability in modern databases. ACID properties refer to a set of guidelines that transactions must adhere to within databases, especially in the context of RDBMS.
Definition of RAG RAG stands for Retrieval-Augmented Generation, which emphasizes blending real-time data retrieval with the language model’s ability to generate contextually relevant responses. Its functionality allows LLMs to interact dynamically with multiple databases for optimal responses.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. The user query is used to retrieve relevant additional context from the vector database. The retrieved context and the user query are used to augment a prompt template.
Foreign keys are a cornerstone of relational databases, playing a crucial role in organizing and linking related data across tables. Understanding foreign keys is essential for anyone working with relational database management systems. Foreign keys are fields in a database table that establish a link between two tables.
As the amount of data being generated and stored by companies and organizations continue to grow, the ability to effectively manage and manipulate this data using databases has become increasingly important for developers. For the unversed, the programming language SQL is primarily used to manage and manipulate data in relational databases.
Solution overview Typically, a three-tier software application has a UI interface tier, a middle tier (the backend) for business APIs, and a database tier. Generate, run, and validate the SQL from natural language understanding using LLMs, few-shot examples, and a database schema as a knowledge base.
Definition Continuous Validation is the ongoing assessment of code changes using automated testing methods to ensure that new additions do not introduce errors or degrade existing functionality. Protects the main database from issues arising from new integrations. Key benefits Automated validation uncovers bugs quickly.
Definition and functionality of TCAM At its core, TCAM operates by enabling searches based on data content instead of relying on static addresses. Database applications: TCAM can optimize data retrieval processes, making it useful for large-scale databases.
Code Indexer Loop is a Python library for indexing and retrieving source code files through an integrated vector database that's continuously and efficiently updated.
How are Knowledge Graphs Different from Vector Databases? Source: Neo4j Knowledge graphs and vector databases represent and retrieve information in fundamentally different ways. Key Components of GraphRAG: Knowledge Graph (KG): A structured database that stores entities (nodes) and relationships (edges) in a graph format.
Summary: SQL commands list in DBMS help manage databases efficiently. In simple words, SQL ( Structured Query Language ) is used to manage and organise data in databases. In this blog, well break down the SQL commands list in DBMS so you can understand how databases work effortlessly.
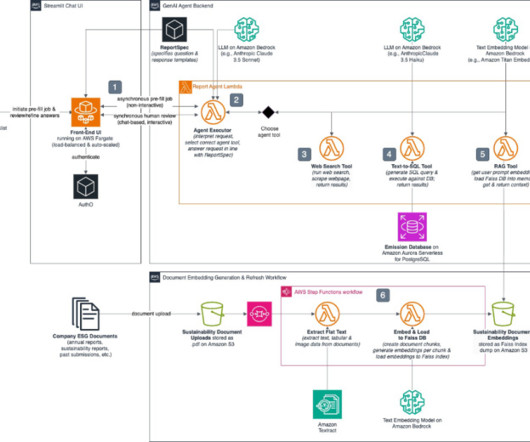
Data for a single report includes thousands of data points from a multitude of sources including official documentation, databases, unstructured document stores, utility bills, and emails. Report GenAI pre-fills reports by drawing on existing databases, document stores and web searches. on Amazon Bedrock.
Your application forwards the query to Amazon Bedrock through the Converse API: # Initialize the Bedrock runtime client with your AWS credentials bedrock = boto3.client(service_name='bedrock-runtime', million, representing a 12% growth compared to the previous quarter.
We also offer hosted and on-premise versions with OCR, extra metadata, all embedding providers, and managed vector databases for teams that want a fully managed pipeline. 200k+ tokens) with many SQL snippets, query results and database metadata (e.g. Your private database for all ai interactions. table and column info).
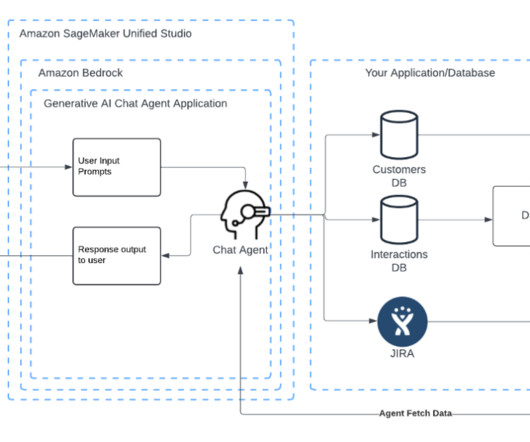
Generative AI-powered agents for automated workflows Amazon Bedrock in SageMaker Unified Studio allows you to create and deploy generative AI agents that integrate with organizational applications, databases, and third-party systems, enabling natural language interactions across the entire technology stack. For Key name , enter x-api-key.
In RAG, you store these chunks in a vector database and encode them with a text embedding model. Set Up the Vector Database You can sign up for a free-tier KDB.AI Well generate late chunks and store them in the vector database. Splitting text naively can inadvertently break longer contextual relationships. Initialize KDB.AI
As organizations increasingly rely on diverse databases and applications, maintaining a consistent model for data interchange becomes essential. Definition and importance In essence, a Canonical schema helps maintain data integrity and consistency by ensuring that all applications adhere to the same data representation.
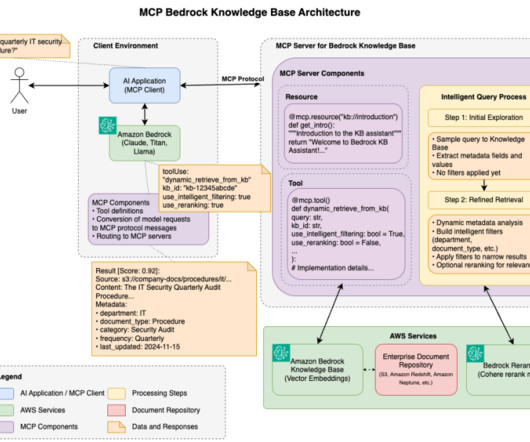
Agent function calling represents a critical capability for modern AI applications, allowing models to interact with external tools, databases, and APIs by accurately determining when and how to invoke specific functions. For implementation examples, check out our code samples in the amazon-bedrock-samples GitHub repository.
The Retrieval-Augmented Generation (RAG) framework augments prompts with external data from multiple sources, such as document repositories, databases, or APIs, to make foundation models effective for domain-specific tasks. Its vector data store seamlessly integrates with operational data storage, eliminating the need for a separate database.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content