This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
SQL (Structured Query Language) is an important tool for data scientists. It is a programming language used to manipulate data stored in relational databases. Mastering SQL concepts allows a data scientist to quickly analyze large amounts of data and make decisions based on their findings.
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
When it comes to data, there are two main types: data lakes and datawarehouses. What is a data lake? An enormous amount of raw data is stored in its original format in a data lake until it is required for analytics applications. Which one is right for your business? Let’s take a closer look.
Summary : This guide provides an in-depth look at the top datawarehouse interview questions and answers essential for candidates in 2025. Covering key concepts, techniques, and best practices, it equips you with the knowledge needed to excel in interviews and demonstrates your expertise in data warehousing.
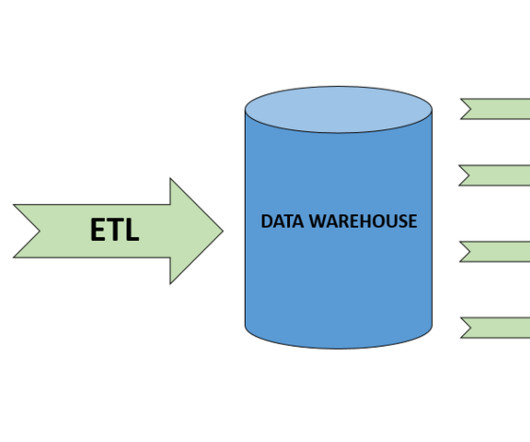
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
Thats where data normalization comes in. Its a structured process that organizes data to reduce redundancy and improve efficiency. Whether you’re working with relational databases, datawarehouses , or machine learning pipelines, normalization helps maintain clean, accurate, and optimized datasets.
In the six years since, solutions to the centralized data problem have emerged, many of them employing cutting-edge web3 technologies like blockchain, zero-knowledge proofs (ZKPs), and self-sovereign identities (SSIs) to put users back in the data driver’s seat. In the past two years alone, 2.6
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports.
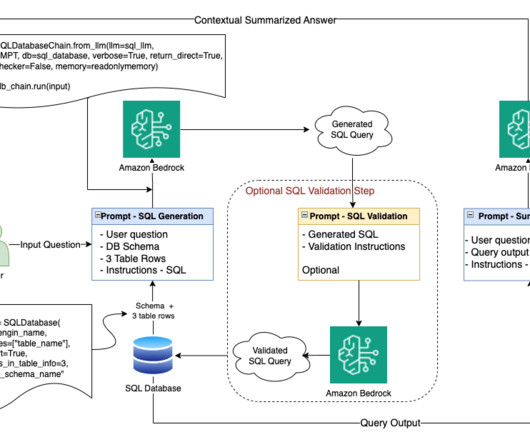
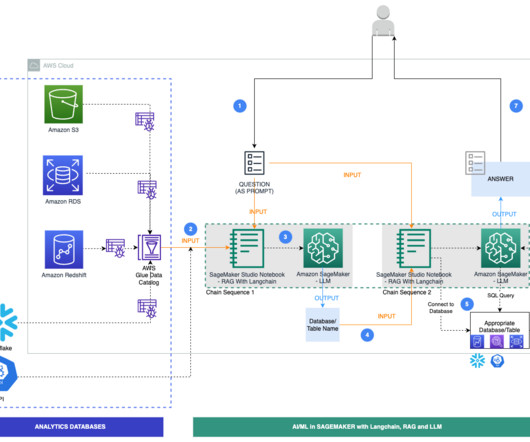
The workflow includes the following steps: Within the SageMaker Canvas interface, the user composes a SQL query to run against the GCP BigQuery datawarehouse. Athena returns the queried data from BigQuery to SageMaker Canvas, where you can use it for ML model training and development purposes within the no-code interface.
In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them. They then use SQL to explore, analyze, visualize, and integrate data from various sources before using it in their ML training and inference.
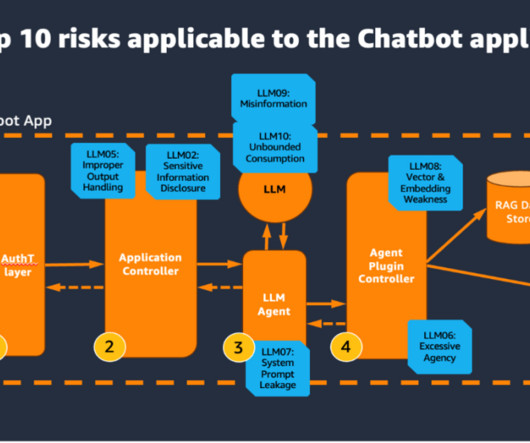
RAG data store The Retrieval Augmented Generation (RAG) data store delivers up-to-date, precise, and access-controlled knowledge from various data sources such as datawarehouses, databases, and other software as a service (SaaS) applications through data connectors.
How companies gather, manage and control data has undeniably become one of the most important aspects of business success today. It’s also possible to employ extra caching or materialized views in the datawarehouse in addition to caching in Looker (depending on the capability of your datawarehouse). Final word.
Furthermore, it has been estimated that by 2025, the cumulative data generated will triple to reach nearly 175 zettabytes. Demands from business decision makers for real-time data access is also seeing an unprecedented rise at present, in order to facilitate well-informed, educated business decisions.
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
Data is one of the most critical assets of many organizations. Theyre constantly seeking ways to use their vast amounts of information to gain competitive advantages. This enables OMRON to extract meaningful patterns and trends from its vast data repositories, supporting more informed decision-making at all levels of the organization.
In this blog post, we will be discussing 7 tips that will help you become a successful data engineer and take your career to the next level. Learn SQL: As a data engineer, you will be working with large amounts of data, and SQL is the most commonly used language for interacting with databases.
Why data warehousing is critical to a company’s success Data warehousing is the secure electronic information storage by a company or organization. Data is reported from one central repository, enabling management to draw more meaningful business insights and make faster, better decisions.
Discover the nuanced dissimilarities between Data Lakes and DataWarehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are Data Lakes and DataWarehouses. It acts as a repository for storing all the data.
Introduction Snowflake is a cloud-based data warehousing platform that enables enterprises to manage vast and complicated information by providing scalable storage and processing capabilities. It is intended to be a fully managed, multi-cloud solution that does not need clients to handle hardware or software.
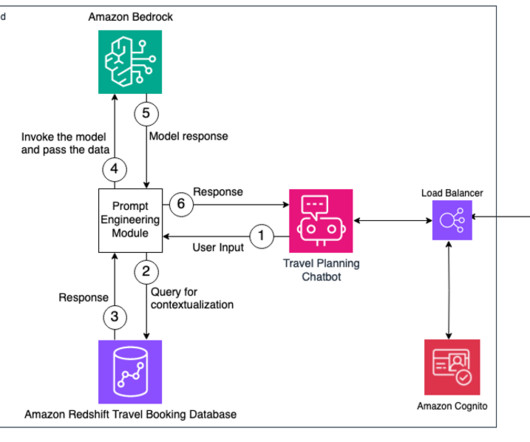
In this post, we discuss a Q&A bot use case that Q4 has implemented, the challenges that numerical and structured datasets presented, and how Q4 concluded that using SQL may be a viable solution. Providing incorrect or outdated information can impact investors’ and shareholders’ trust, in addition to other possible data privacy risks.
In the simplest of terms, the latter refers to a system that examines large bodies of data with the goal of uncovering trends, patterns, correlations and other helpful information. What is big data used for? Customer experience is another key area that can benefit from big data analytics. Big data analytics advantages.
Data activation is a new and exciting way that businesses can think of their data. It’s more than just data that provides the information necessary to make wise, data-driven decisions. It’s more than just allowing access to datawarehouses that were becoming dangerously close to data silos.
we’ve added new connectors to help our customers access more data in Azure than ever before: an Azure SQL Database connector and an Azure Data Lake Storage Gen2 connector. As our customers increasingly adopt the cloud, we continue to make investments that ensure they can access their data anywhere. Azure SQL Database.
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Understanding Data Lakes A data lake is a centralized repository that stores structured, semi-structured, and unstructured data in its raw format.
Summary: Online Analytical Processing (OLAP) systems in DataWarehouse enable complex Data Analysis by organizing information into multidimensional structures. Key characteristics include fast query performance, interactive analysis, hierarchical data organization, and support for multiple users. What is OLAP?
The extraction of raw data, transforming to a suitable format for business needs, and loading into a datawarehouse. Data transformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation.
Sigma Computing , a cloud-based analytics platform, helps data analysts and business professionals maximize their data with collaborative and scalable analytics. One of Sigma’s key features is its support for custom SQL queries and CSV file uploads. These tools allow users to handle more advanced data tasks and analyses.
Natural language is ambiguous and imprecise, whereas data adheres to rigid schemas. For example, SQL queries can be complex and unintuitive for non-technical users. Handling complex queries involving multiple tables, joins, and aggregations makes it difficult to interpret user intent and translate it into correct SQL operations.
Summary: Data engineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. What Does a Data Engineer Do?
Accurate and secure data can help to streamline software engineering processes and lead to the creation of more powerful AI tools, but it has become a challenge to maintain the quality of the expansive volumes of data needed by the most advanced AI models.
Madeleine Corneli Senior Manager, Product Management, Tableau Adiascar Cisneros Manager, Product Management, Tableau Bronwen Boyd April 3, 2023 - 5:27pm April 3, 2023 Google Cloud’s BigQuery is a serverless, highly-scalable cloud-based datawarehouse solution that allows users to store, query, and analyze large datasets quickly.
Unified data storage : Fabric’s centralized data lake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. This transparency helps businesses control costs and make informed decisions about resource allocation.
Data is processed to generate information, which can be later used for creating better business strategies and increasing the company’s competitive edge. It’s obvious that you’ll want to use big data, but it’s not so obvious how you’re going to work with it. Preserve information: Keep your raw data raw.
There are a lot of important queries that you need to run as a data scientist. This tool can be great for handing SQL queries and other data queries. Every data scientist needs to understand the benefits that this technology offers. The data is processed and modified after it has been extracted.
Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping. Data can be in structured (like tables in databases), semi-structured (like XML or JSON), or unstructured (like text, audio, and images) form.
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the data pipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a datawarehouse. Thus, it has only a minimal footprint.
The natural language capabilities allow non-technical users to query data through conversational English rather than complex SQL. The AI and language models must identify the appropriate data sources, generate effective SQL queries, and produce coherent responses with embedded results at scale.
The foundation model then generates more relevant and accurate information. Amazon Redshift has announced a feature called Amazon Redshift ML that makes it straightforward for data analysts and database developers to create, train, and apply machine learning (ML) models using familiar SQL commands in Redshift datawarehouses.
Fivetran, a cloud-based automated data integration platform, has emerged as a leading choice among businesses looking for an easy and cost-effective way to unify their data from various sources. Fivetran is used by businesses to centralize data from various sources into a single, comprehensive datawarehouse.
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. You can use query_string to filter your dataset by SQL and unload it to Amazon S3. If you’re familiar with SageMaker and writing Spark code, option B could be your choice.
Many of the RStudio on SageMaker users are also users of Amazon Redshift , a fully managed, petabyte-scale, massively parallel datawarehouse for data storage and analytical workloads. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools.
Data Quality Now that you’ve learned more about your data and cleaned it up, it’s time to ensure the quality of your data is up to par. With these data exploration tools, you can determine if your data is accurate, consistent, and reliable.
Watsonx.data will allow users to access their data through a single point of entry and run multiple fit-for-purpose query engines across IT environments. Through workload optimization an organization can reduce datawarehouse costs by up to 50 percent by augmenting with this solution. [1]
Run pandas at scale on your datawarehouse Most enterprise data teams store their data in a database or datawarehouse, such as Snowflake, BigQuery, or DuckDB. Ponder solves this problem by translating your pandas code to SQL that can be understood by your datawarehouse.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content