

Data mining
Dataconomy
MARCH 4, 2025
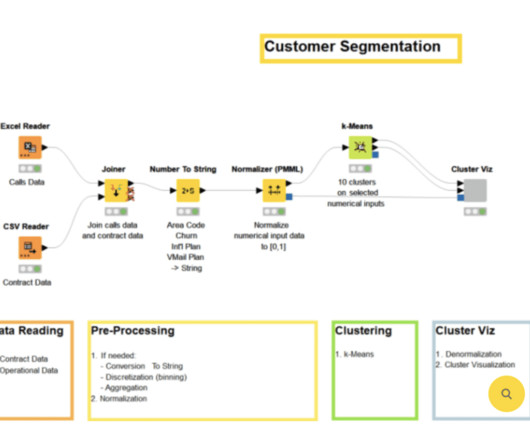
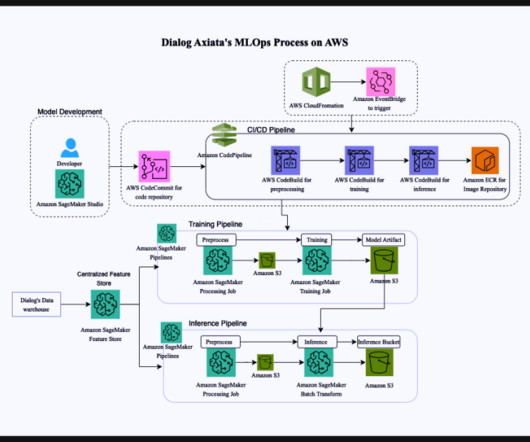
The data mining process The data mining process is structured into four primary stages: data gathering, data preparation, data mining, and data analysis and interpretation. Each stage is crucial for deriving meaningful insights from data.











Let's personalize your content