This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
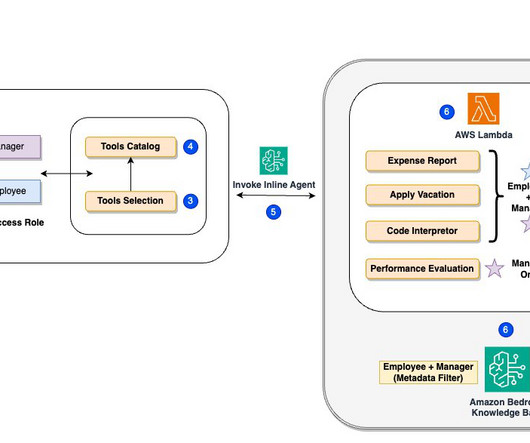
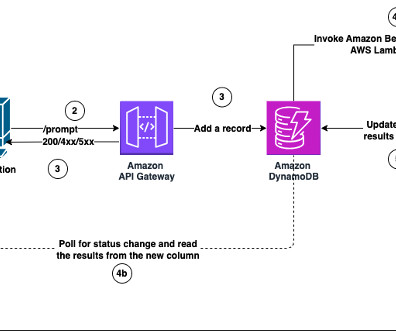
To understand how this dynamic role-based functionality works under the hood, lets examine the following systemarchitecture diagram. As shown in preceding architecture diagram, the system works as follows: The end-user logs in and is identified as either a manager or an employee. Nitin Eusebius is a Sr.
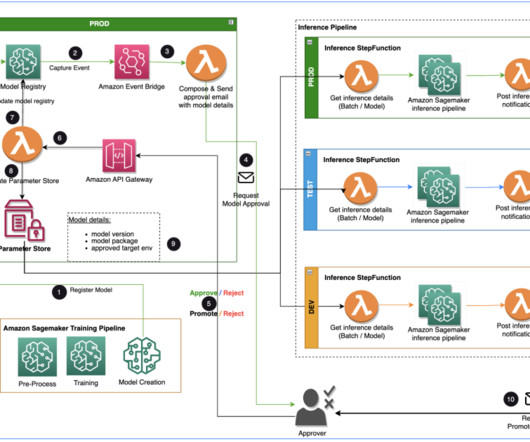
Specialist Data Engineering at Merck, and Prabakaran Mathaiyan, Sr. ML Engineer at Tiger Analytics. The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of software development. The input to the training pipeline is the features dataset.
It requires checking many systems and teams, many of which might be failing, because theyre interdependent. Developers need to reason about the systemarchitecture, form hypotheses, and follow the chain of components until they have located the one that is the culprit. Otto focuses on application development and security.
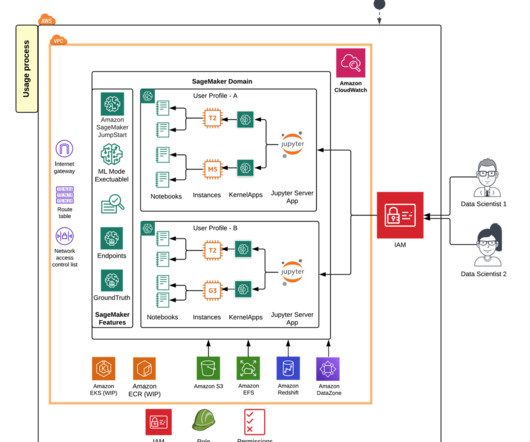
With organizations increasingly investing in machine learning (ML), ML adoption has become an integral part of business transformation strategies. However, implementing ML into production comes with various considerations, notably being able to navigate the world of AI safely, strategically, and responsibly.
Jerry Liu Jerry Liu is the co-founder and CEO of LlamaIndex, a leading open-source framework that simplifies data integration and querying for large language model (LLM) applications. With a background as a founding ML engineer, datascientist, and curriculum designer, Chris brings deep technical knowledge and a passion for teaching.
Ray promotes the same coding patterns for both a simple machine learning (ML) experiment and a scalable, resilient production application. Overview of Ray This section provides a high-level overview of the Ray tools and frameworks for AI/ML workloads. We primarily focus on ML training use cases.
Organizations building or adopting generative AI use GPUs to run simulations, run inference (both for internal or external usage), build agentic workloads, and run datascientists’ experiments. The workloads range from ephemeral single-GPU experiments run by scientists to long multi-node continuous pre-training runs.
Understanding the intrinsic value of data network effects, Vidmob constructed a product and operational systemarchitecture designed to be the industry’s most comprehensive RLHF solution for marketing creatives. Dataset The dataset includes a set of ad-related data corresponding to a specific client.
Whether youre building with large language models (LLMs), deploying real-time decision systems, or leading AI integration at the enterprise level, understanding how agents are designed, evaluated, and scaled is becoming essential.
Solution overview The following figure illustrates our systemarchitecture for CreditAI on AWS, with two key paths: the document ingestion and content extraction workflow, and the Q&A workflow for live user query response. He specializes in generative AI, machine learning, and system design.
As an MLOps engineer on your team, you are often tasked with improving the workflow of your datascientists by adding capabilities to your ML platform or by building standalone tools for them to use. And since you are reading this article, the datascientists you support have probably reached out for help.
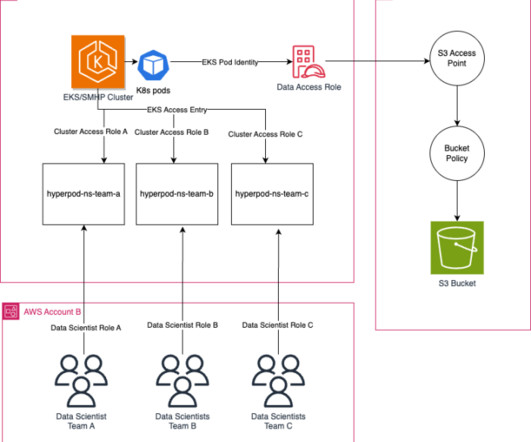
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud. Because you use p4de.24xlarge You can then take the easy-ssh.sh
" The LLMOps Steps LLMs, sophisticated artificial intelligence (AI) systems trained on enormous text and code datasets, have changed the game in various fields, from natural language processing to content generation. Deployment : The adapted LLM is integrated into this stage's planned application or systemarchitecture.
I originally wanted to program numerical libraries for such systems, but I ended up doing AI/ML instead. I want to go deeper into this niche, do more CUDA programming, explore tiling DSLs such as Triton, get to know Jax and XLA and study, use and build ML compilers. Some: React, IoT, bit o elm, ML, LLM ops and auotmation.
Good at Go, Kubernetes (Understanding how to manage stateful services in a multi-cloud environment) We have a Python service in our Recommendation pipeline, so some ML/Data Science knowledge would be good. You must be independent and self-organized.
Systemarchitecture for GNN-based network traffic prediction In this section, we propose a systemarchitecture for enhancing operational safety within a complex network, such as the ones we discussed earlier. To learn how to use GraphStorm to solve a broader class of ML problems on graphs, see the GitHub repo.
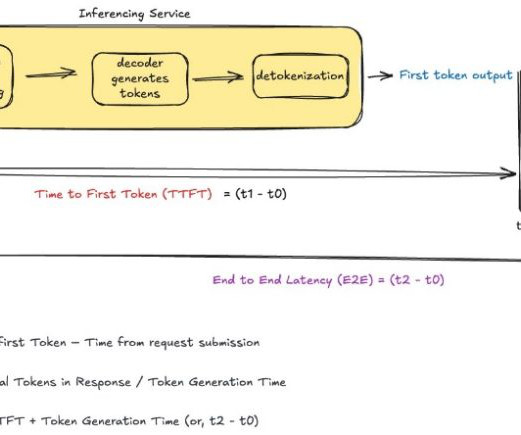
In this section, we explore how different system components and architectural decisions impact overall application responsiveness. Systemarchitecture and end-to-end latency considerations In production environments, overall system latency extends far beyond model inference time.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content