This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For datascientists, this shift has opened up a global market of remote data science jobs, with top employers now prioritizing skills that allow remote professionals to thrive. Here’s everything you need to know to land a remote data science job, from advanced role insights to tips on making yourself an unbeatable candidate.
Abid Ali Awan ( @1abidaliawan ) is a certified datascientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies.
This article was published as a part of the Data Science Blogathon. Introduction Datascientists, engineers, and BI analysts often need to analyze, process, or query different data sources.
Top 10 Professions in Data Science: Below, we provide a list of the top data science careers along with their corresponding salary ranges: 1. DataScientistDatascientists are responsible for designing and implementing data models, analyzing and interpreting data, and communicating insights to stakeholders.
Historical context To appreciate the innovation of the data lakehouse, it’s useful to understand the evolution of its predecessors: data warehouses and data lakes. User segments The versatility of the data lakehouse architecture makes it valuable to a wide range of professionals within an organization.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 5 Error Handling Patterns in Python (Beyond Try-Except) Stop letting errors crash your app.
For budding datascientists and data analysts, there are mountains of information about why you should learn R over Python and the other way around. Though both are great to learn, what gets left out of the conversation is a simple yet powerful programming language that everyone in the data science world can agree on, SQL.
Big data support: Pipelines handle diverse data types and volumes, enabling organizations to execute significant initiatives with confidence. Users of data pipelines Different roles within organizations benefit from data pipelines, enhancing their capacity to leverage data for informed decision-making.
Data engineers are the unsung heroes of the data-driven world, laying the essential groundwork that allows organizations to leverage their data for enhanced decision-making and strategic insights. Their role has grown increasingly critical as businesses rely on large volumes of data to inform their operations and strategies.
Data integration plays a key role in achieving this by incorporating data cleansing techniques, ensuring that the information used is accurate and consistent. Reduction of data silos Breaking down data silos is essential for enhancing collaboration across different departments within an organization.
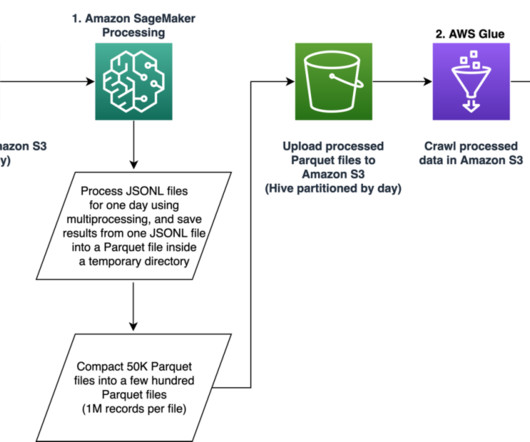
Our pipeline belongs to the general ETL (extract, transform, and load) process family that combines data from multiple sources into a large, central repository. This post shows how we used SageMaker to build a large-scale data processing pipeline for preparing features for the job recommendation engine at Talent.com.
So why using IaC for Cloud Data Infrastructures? For Data Warehouse Systems that often require powerful (and expensive) computing resources, this level of control can translate into significant cost savings. This brings reliability to dataETL (Extract, Transform, Load) processes, query performances, and other critical data operations.
Amazon SageMaker Studio provides a fully managed solution for datascientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, datascientists typically start their workflow by discovering relevant data sources and connecting to them.
He highlights innovations in data, infrastructure, and artificial intelligence and machine learning that are helping AWS customers achieve their goals faster, mine untapped potential, and create a better future. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
The field of data science is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for data science hires peak.
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. This also led to a backlog of data that needed to be ingested.
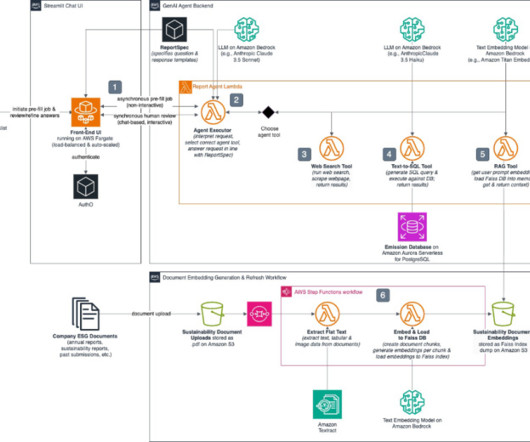
Gardenia Technologies, a data analytics company, partnered with the AWS Prototyping and Cloud Engineering (PACE) team to develop Report GenAI , a fully automated ESG reporting solution powered by the latest generative AI models on Amazon Bedrock. The Lambda-hosted text-to-SQL tool provides the agent with the required analytical capabilities.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, data lakes, and analytics tools to load, transform, clean, and aggregate data. option("multiLine", "true").option("header",
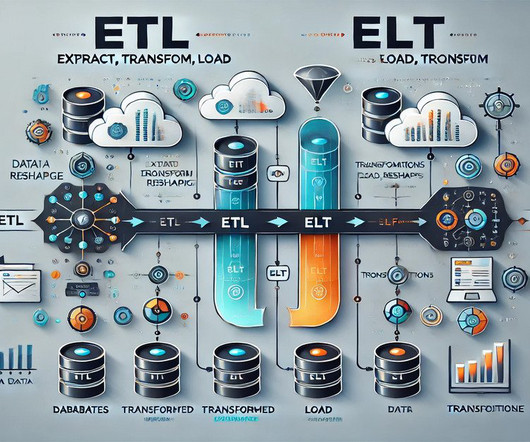
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. What is ETL? ETL stands for Extract, Transform, and Load.
Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python. Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB.
Team Building the right data science team is complex. With a range of role types available, how do you find the perfect balance of DataScientists , Data Engineers and Data Analysts to include in your team? The Data Engineer Not everyone working on a data science project is a datascientist.
Unfolding the difference between data engineer, datascientist, and data analyst. Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Role of DataScientistsDataScientists are the architects of data analysis.
Summary: Data engineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines.
To obtain such insights, the incoming raw data goes through an extract, transform, and load (ETL) process to identify activities or engagements from the continuous stream of device location pings. Datascientists can accomplish this process by connecting through Amazon SageMaker notebooks.
An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
These regulations have a monumental impact on data processing and handling , consumer profiling and data security. Datascientists and analysts who understand the ramifications can help organizations navigate the guidelines, and are skilled in both data privacy and security are in high demand.
DataScientists and ML Engineers typically write lots and lots of code. From writing code for doing exploratory analysis, experimentation code for modeling, ETLs for creating training datasets, Airflow (or similar) code to generate DAGs, REST APIs, streaming jobs, monitoring jobs, etc.
Db2 Warehouse fully supports open formats such as Parquet, Avro, ORC and Iceberg table format to share data and extract new insights across teams without duplication or additional extract, transform, load (ETL). This allows you to scale all analytics and AI workloads across the enterprise with trusted data.
Data engineering is a rapidly growing field, and there is a high demand for skilled data engineers. If you are a datascientist, you may be wondering if you can transition into data engineering. The good news is that there are many skills that datascientists already have that are transferable to data engineering.
Every day, millions of riders use the Uber app, unwittingly contributing to a complex web of data-driven decisions. This blog takes you on a journey into the world of Uber’s analytics and the critical role that Presto, the open source SQL query engine, plays in driving their success. What is Presto?
Hive is a data warehousing infrastructure built on top of Hadoop. It has the following features: It facilitates querying, summarizing, and analyzing large datasets Hadoop also provides a SQL-like language called HiveQL Hive allows users to write queries to extract valuable insights from structured and semi-structured data stored in Hadoop.
Prime examples of this in the data catalog include: Trust Flags — Allow the data community to endorse, warn, and deprecate data to signal whether data can or can’t be used. Data Profiling — Statistics such as min, max, mean, and null can be applied to certain columns to understand its shape.
In contrast, data warehouses and relational databases adhere to the ‘Schema-on-Write’ model, where data must be structured and conform to predefined schemas before being loaded into the database. Schema Enforcement: Data warehouses use a “schema-on-write” approach. This ensures data consistency and integrity.
Jupyter notebooks have been one of the most controversial tools in the data science community. Nevertheless, many datascientists will agree that they can be really valuable – if used well. Data on its own is not sufficient for a cohesive story. in a pandas DataFrame) but in the company’s data warehouse (e.g.,
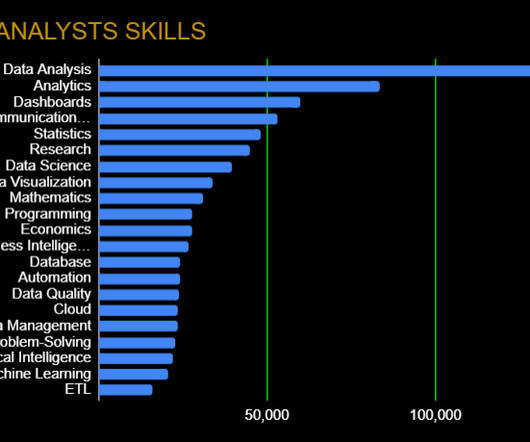
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A data warehouse. Data ingestion/integration services. Reverse ETL tools. Data orchestration tools. A Note on the Shift from ETL to ELT. Datascientists.
We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction. To demonstrate fine-grained data access permissions, we consider the following two users: David, a datascientist on the marketing team.
There’s no need for developers or analysts to manually adjust table schemas or modify ETL (Extract, Transform, Load) processes whenever the source data structure changes. Time Efficiency – The automated schema detection and evolution features contribute to faster data availability.
Data Engineering is one of the most productive job roles today because it imbibes both the skills required for software engineering and programming and advanced analytics needed by DataScientists. How to Become an Azure Data Engineer? Having experience using at least one end-to-end Azure data lake project.
Unlike traditional databases, Data Lakes enable storage without the need for a predefined schema, making them highly flexible. Importance of Data Lakes Data Lakes play a pivotal role in modern data analytics, providing a platform for DataScientists and analysts to extract valuable insights from diverse data sources.
Data preprocessing ensures the removal of incorrect, incomplete, and inaccurate data from datasets, leading to the creation of accurate and useful datasets for analysis ( Image Credit ) Data completeness One of the primary requirements for data preprocessing is ensuring that the dataset is complete, with minimal missing values.
They are responsible for building and maintaining data architectures, which include databases, data warehouses, and data lakes. Their work ensures that data flows seamlessly through the organisation, making it easier for DataScientists and Analysts to access and analyse information.
Integrating helpful metadata into user workflows gives all people, from datascientists to analysts , the context they need to use data more effectively. The Benefits and Challenges of the Modern Data Stack Why are such integrations needed? This empowers users to judge data’s quality and fitness for purpose quickly.
Snowpark is the set of libraries and runtimes in Snowflake that securely deploy and process non-SQL code, including Python, Java, and Scala. A DataFrame is like a query that must be evaluated to retrieve data. An action causes the DataFrame to be evaluated and sends the corresponding SQL statement to the server for execution.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content