This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The points to cover in this article are as follows: Generating synthetic data to illustrate ML modelling for election outcomes. Providing some insights into how datascientists might approach real-life election predictions. Model Fitting and Training: Various ML models trained on sub-patterns in data.
The world’s leading publication for data science, AI, and ML professionals. I’ve worked as a datascientist in FinTech for six years. The data came as a.parquet file that I downloaded using duckdb. You don’t need a PhD to be a datascientist or win a ML competition.
Instead, organizations are increasingly looking to take advantage of transformative technologies like machine learning (ML) and artificial intelligence (AI) to deliver innovative products, improve outcomes, and gain operational efficiencies at scale. Data is presented to the personas that need access using a unified interface.
In this post, we share how Radial optimized the cost and performance of their fraud detection machine learning (ML) applications by modernizing their ML workflow using Amazon SageMaker. Businesses need for fraud detection models ML has proven to be an effective approach in fraud detection compared to traditional approaches.
The onset of the pandemic has triggered a rapid increase in the demand and adoption of ML technology. Building ML team Following the surge in ML use cases that have the potential to transform business, the leaders are making a significant investment in ML collaboration, building teams that can deliver the promise of machine learning.
The importance of EDA in the machine learning world is well known to its users. Making visualizations is one of the finest ways for datascientists to explain data analysis to people outside the business. Exploratory data analysis can help you comprehend your data better, which can aid in future data preprocessing.
From Predicting the behavior of a customer to automating many tasks, Machine learning has shown its capacity to convert raw data into actionable insights. Even though converting raw data into actionable insights, it is not determined by ML algorithms alone. The success of any ML project depends on a well-structured lifecycle.
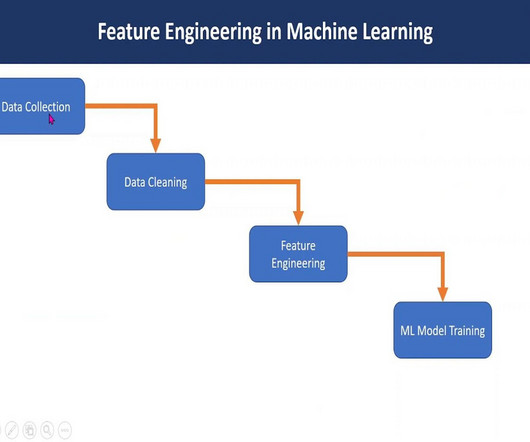
Introduction Data preprocessing is a critical step in the Machine Learning pipeline, transforming raw data into a clean and usable format. With the explosion of data in recent years, it has become essential for datascientists and Machine Learning practitioners to understand and effectively apply preprocessing techniques.
Similar to traditional Machine Learning Ops (MLOps), LLMOps necessitates a collaborative effort involving datascientists, DevOps engineers, and IT professionals. Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from data preparation to pipeline production.
As such, my intention with this blog is not to duplicate those definitions but rather to encourage you to question and evaluate your current ML strategy. While ML algorithms & code play a crucial role in success, it’s just a small piece of the large puzzle. Source: Image by the author.
These tools will help make your initial data exploration process easy. ydata-profiling GitHub | Website The primary goal of ydata-profiling is to provide a one-line Exploratory Data Analysis (EDA) experience in a consistent and fast solution. This tool automatically detects problems in an ML dataset.
The ’31 Questions that Shape Fortune 500 ML Strategy’ highlighted key questions to assess the maturity of an ML system. A robust ML platform offers managed solutions to easily address these aspects. Collaboration] How can multiple datascientists collaborate in real-time on the same dataset?
The machine learning (ML) model classifies new incoming customer requests as soon as they arrive and redirects them to predefined queues, which allows our dedicated client success agents to focus on the contents of the emails according to their skills and provide appropriate responses. A test endpoint is deployed for testing purposes.
And eCommerce companies have a ton of use cases where ML can help. The problem is, with more ML models and systems in production, you need to set up more infrastructure to reliably manage everything. And because of that, many companies decide to centralize this effort in an internal ML platform. But how to build it?
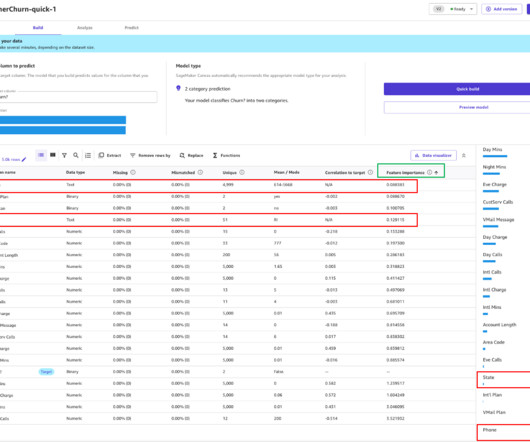
Although machine learning (ML) can provide valuable insights, ML experts were needed to build customer churn prediction models until the introduction of Amazon SageMaker Canvas. It also enables you to evaluate the models using advanced metrics as if you were a datascientist.
Its robust ecosystem of libraries and frameworks tailored for Data Science, such as NumPy, Pandas, and Scikit-learn, contributes significantly to its popularity. Moreover, Python’s straightforward syntax allows DataScientists to focus on problem-solving rather than grappling with complex code.
& AWS Machine Learning Solutions Lab (MLSL) Machine learning (ML) is being used across a wide range of industries to extract actionable insights from data to streamline processes and improve revenue generation. For further assistance in terms of designing and developing ML solutions, please free to get in touch with the MLSL team.
Answering one of the most common questions I get asked as a Senior DataScientist — What skills and educational background are necessary to become a datascientist? Photo by Eunice Lituañas on Unsplash To become a datascientist, a combination of technical skills and educational background is typically required.
Introduction In the rapidly evolving landscape of Machine Learning , Google Cloud’s Vertex AI stands out as a unified platform designed to streamline the entire Machine Learning (ML) workflow. This unified approach enables seamless collaboration among datascientists, data engineers, and ML engineers.
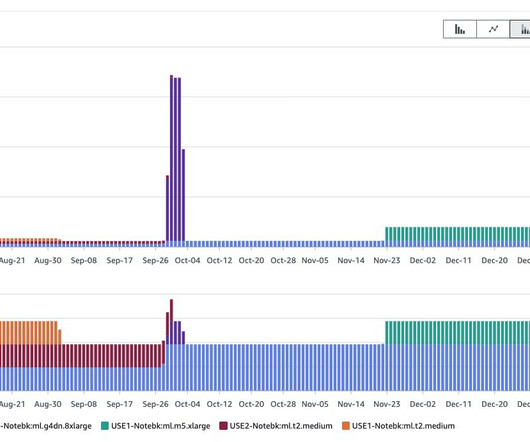
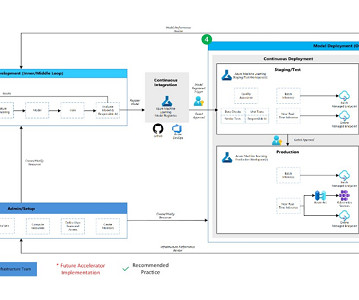
Since its introduction, we have helped hundreds of customers optimize their workloads, set guardrails, and improve the visibility of their machine learning (ML) workloads’ cost and usage. Notebooks contain everything needed to run or recreate an ML workflow. SageMaker manages creating the instance and related resources.
It is designed to make it easy to track and monitor experiments and conduct exploratory data analysis (EDA) using popular Python visualization frameworks. Introducing Kangas A powerful software application for working with large amounts of multimedia data. We pay our contributors, and we don’t sell ads.
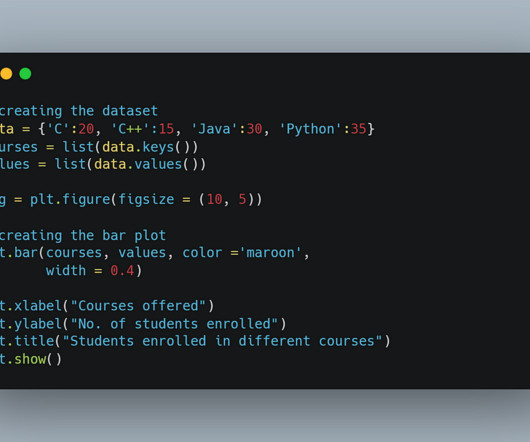
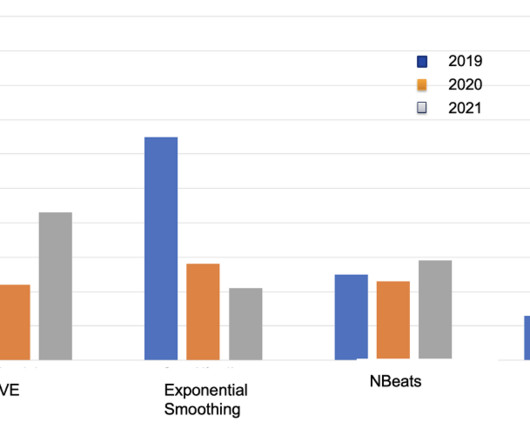
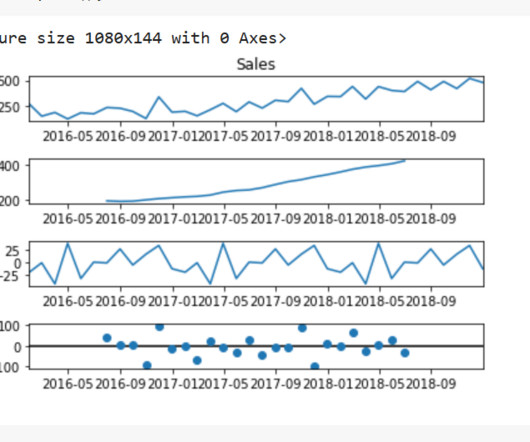
We will carry out some EDA on our dataset, and then we will log the visualizations onto the Comet experimentation website or platform. Time Series Models Time series models are a type of statistical model that are used to analyze and make predictions about data that is collected over time. Without further ado, let’s begin.
To address this challenge, datascientists harness the power of machine learning to predict customer churn and develop strategies for customer retention. Continuous Experiment Tracking with Comet ML Comet ML is a versatile tool that helps datascientists optimize machine learning experiments.
The challenge required a detailed analysis of Google Trends data, integration of additional data sources, and the application of advanced ML methods to predict market behaviors. Datascientists across various expertise levels engaged in this challenge to determine Google Trends’ impact on cryptocurrency valuations.
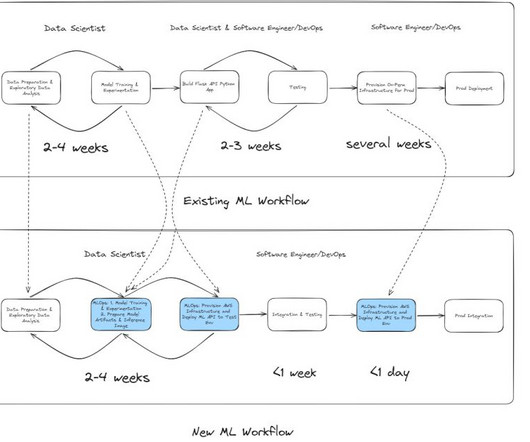
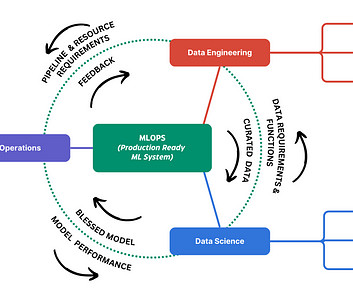
Machine Learning Operations (MLOps) can significantly accelerate how datascientists and ML engineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
Note : Now, Start joining Data Science communities on social media platforms. These communities will help you to be updated in the field, because there are some experienced datascientists posting the stuff, or you can talk with them so they will also guide you in your journey.
How I cleared AWS Machine Learning Specialty with three weeks of preparation (I will burst some myths of the online exam) How I prepared for the test, my emotional journey during preparation, and my actual exam experience Certified AWS ML Specialty Badge source Introduction:- I recently gave and cleared AWS ML certification on 29th Dec 2022.
Drawing from their extensive experience in the field, the authors share their strategies, methodologies, tools and best practices for designing and building a continuous, automated and scalable ML pipeline that delivers business value. The book is poised to address these exact challenges.
Principal Component Analysis(PCA) is an essential algorithm in a datascientist's toolkit. This makes it particularly useful for analyzing large datasets with many variables, where it can be difficult to visualize and interpret the data. . BECOME a WRITER at MLearning.ai
This data challenge took NFL player performance data and fantasy points from the last 6 seasons to calculate forecasted points to be scored in the 2024 NFL season that began Sept. AI / ML offers tools to give a competitive edge in predictive analytics, business intelligence, and performance metrics.
a comprehensive approach to the ML pipeline. Latest trends/methods in Feature Engineering for Time Series Forecasting Dr. Joshua Gordon|Senior DataScientist|DotData This workshop will introduce you to the fundamentals and practical applications of feature engineering as they apply to time series forecasting.
METAR, Miami International Airport (KMIA) on March 9, 2024, at 15:00 UTC In the recently concluded data challenge hosted on Desights.ai , participants used exploratory data analysis (EDA) and advanced artificial intelligence (AI) techniques to enhance aviation weather forecasting accuracy.
But they need a lot of labeled training data, and the dataset could be biased. In order to accomplish this, we will perform some EDA on the Disneyland dataset, and then we will view the visualization on the Comet experimentation website or platform. In this article, we’ll learn how to link Comet with Disneyland Sentiment Analysis.
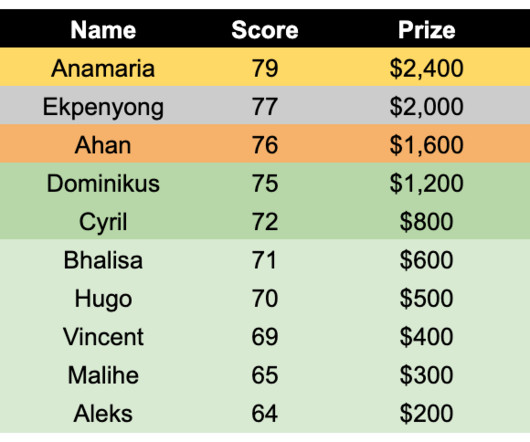
Michal Wierzbinski ¶ Place: 2nd Place Prize: $3,000 Hometown: Rabka-Zdroj (near the city of Cracow), Poland Username: xultaeculcis Social Media: GitHub , LinkedIn Background: ML Engineer specializing in building Deep Learning solutions for Geospatial industry in a cloud native fashion. What motivated you to compete in this challenge?
The growing application of Machine Learning also draws interest towards its subsets that add power to ML models. Key takeaways Feature engineering transforms raw data for ML, enhancing model performance and significance. EDA, imputation, encoding, scaling, extraction, outlier handling, and cross-validation ensure robust models.
Data Science projects require you perform different projects and track changes in your project using a version code. If you want to become an efficient DataScientist and grab that job role you’ve been looking for, you need to work on Github for Data Science projects.
Here are a few of the key concepts that you should know: Machine Learning (ML) This is a type of AI that allows computers to learn without being explicitly programmed. Machine Learning algorithms are trained on large amounts of data, and they can then use that data to make predictions or decisions about new data.
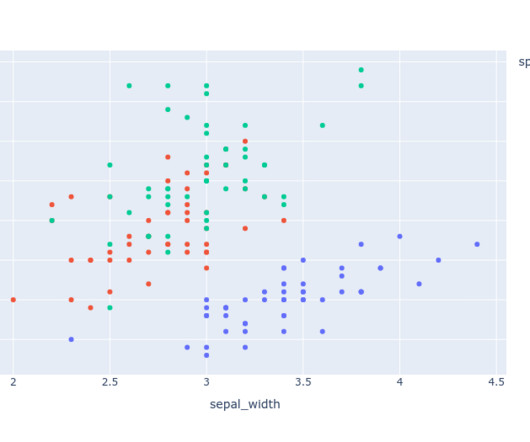
As a datascientist at Cars4U, I had to come up with a pricing model that can effectively predict the price of used cars and can help the business in devising profitable strategies using differential pricing. Bivariate EDA Contrary to intuition, Kilometers_Driven does not seem to have a relationship with the price.
Create DataGrids with image data using Kangas, and load and visualize image data from hugging face Photo by Genny Dimitrakopoulou on Unsplash Visualizing data to carry out a detailed EDA, especially for image data, is critical. We pay our contributors, and we don’t sell ads.
For instance, feature engineering and exploratory data analysis (EDA) often require the use of visualization libraries like Matplotlib and Seaborn. In the data science industry, effective communication and collaboration play a crucial role. Moreover, tools like Power BI and Tableau can produce remarkable results.
Build and deploy your own sentiment classification app using Python and Streamlit Source:Author Nowadays, working on tabular data is not the only thing in Machine Learning (ML). Data formats like image, video, text, etc., This approach is mostly referred to for small datasets where ML models can not be effective.
This is a straightforward and mostly clear-cut question — most of us can likely classify a dish as a dessert or not simply by reading its name, which makes it an excellent candidate for a simple ML model. Step 3: Train, Test, and Evaluate Model Once the data is processed and transformed, we can split it into a training set and a testing set.
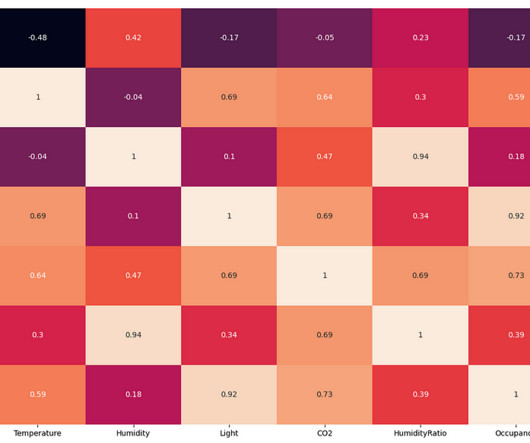
From the above EDA, it is clear that the room's temperature, light, and CO2 levels are good occupancy indicators. Editorially independent, Heartbeat is sponsored and published by Comet, an MLOps platform that enables datascientists & ML teams to track, compare, explain, & optimize their experiments.
ML practitioners are increasingly coming to appreciate that while foundation models like LLMs provide a fantastic foundation for AI applications, best results are achieved with additional data-centric development. We corrected these via prompt where possible and then later via additional labeled data for fine-tuning.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content