This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
10 Cheat Sheets You Need To Ace Data Science Interview • 3 Valuable Skills That Have Doubled My Income as a DataScientist • How to Select Rows and Columns in Pandas Using [ ],loc, iloc,at and.iat • The Complete Free PyTorch Course for DeepLearning • DecisionTree Algorithm, Explained.
Also: DeepLearning for NLP: Creating a Chatbot with Keras!; Understanding DecisionTrees for Classification in Python; How to Become More Marketable as a DataScientist; Is Kaggle Learn a Faster Data Science Education?
Deeplearning models are typically highly complex. While many traditional machine learning models make do with just a couple of hundreds of parameters, deeplearning models have millions or billions of parameters. The reasons for this range from wrongly connected model components to misconfigured optimizers.
The job market for datascientists is booming. In fact, the demand for data experts is expected to grow by 36% between 2021 and 2031, significantly higher than the average for all occupations. This is great news for anyone who is interested in a career in data science. According to the U.S.
Statistical analysis and hypothesis testing Statistical methods provide powerful tools for understanding data. An Applied DataScientist must have a solid understanding of statistics to interpret data correctly. Machine learning algorithms Machine learning forms the core of Applied Data Science.
But how can machine learning practitioners improve the reliability of their models, particularly when dealing with tabular data? Why Gradient Boosting Continues to Dominate Tabular DataProblems Machine learning has seen the rise of deeplearning models, particularly for unstructured data such as images and text.
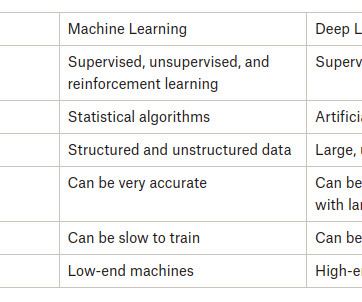
A key component of artificial intelligence is training algorithms to make predictions or judgments based on data. This process is known as machine learning or deeplearning. Two of the most well-known subfields of AI are machine learning and deeplearning. What is DeepLearning?
A cheat sheet for DataScientists is a concise reference guide, summarizing key concepts, formulas, and best practices in Data Analysis, statistics, and Machine Learning. What are Cheat Sheets in Data Science? It includes data collection, data cleaning, data analysis, and interpretation.
Deeplearning for feature extraction, ensemble models, and more Photo by DeepMind on Unsplash The advent of deeplearning has been a game-changer in machine learning, paving the way for the creation of complex models capable of feats previously thought impossible.
Data Sourcing. Fundamental to any aspect of data science, it’s difficult to develop accurate predictions or craft a decisiontree if you’re garnering insights from inadequate data sources. DeepLearning, Machine Learning, and Automation.
Heres what we noticed from analyzing this data, highlighting whats remained the same over the years, and what additions help make the modern datascientist in2025. Data Science Of course, a datascientist should know data science! Joking aside, this does infer particular skills.
Currently pursuing graduate studies at NYU's center for data science. Alejandro Sáez: DataScientist with consulting experience in the banking and energy industries currently pursuing graduate studies at NYU's center for data science. Her primary interests lie in theoretical machine learning.
Photo by Andy Kelly on Unsplash Choosing a machine learning (ML) or deeplearning (DL) algorithm for application is one of the major issues for artificial intelligence (AI) engineers and also datascientists. Here I wan to clarify this issue.
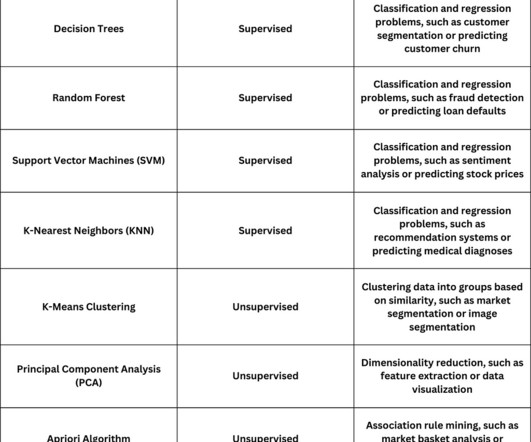
Supervised machine learning Supervised machine learning is a type of machine learning where the model is trained on a labeled dataset (i.e., They’re also part of a family of generative learning algorithms that model the input distribution of a given class or/category. the target or outcome variable is known).
To help you stay ahead of the curve, ODSC APAC this August 22nd-23rd will feature expert-led training sessions in both data science fundamentals and cutting-edge tools and frameworks. Check out a few of them below. Finally, you’ll explore how to handle missing values and training and validating your models using PySpark.
Summary: Inductive bias in Machine Learning refers to the assumptions guiding models in generalising from limited data. By managing inductive bias effectively, datascientists can improve predictions, ensuring models are robust and well-suited for real-world applications.
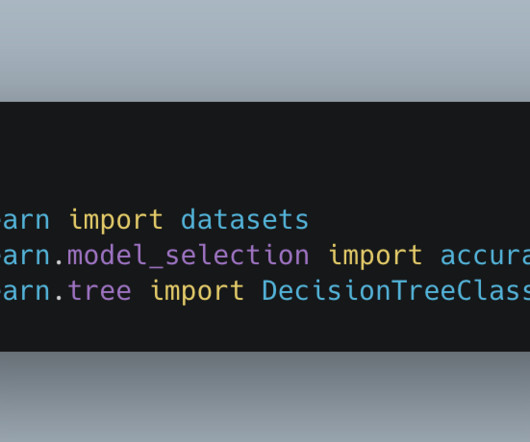
Before continuing, revisit the lesson on decisiontrees if you need help understanding what they are. We can compare the performance of the Bagging Classifier and a single DecisionTree Classifier now that we know the baseline accuracy for the test dataset. Bagging is a development of this idea.
As datasets grow, scalable data ingestion and storage become critical. Techniques such as parallel data processing and distributed data storage systems, like Hadoop or cloud-native solutions, allow datascientists to ingest and store large volumes of data effectively.
Sentence transformers are powerful deeplearning models that convert sentences into high-quality, fixed-length embeddings, capturing their semantic meaning. About the Authors Kara Yang is a DataScientist at AWS Professional Services in the San Francisco Bay Area, with extensive experience in AI/ML.
A lot goes into learning a new skill, regardless of how in-depth it is. Getting started with natural language processing (NLP) is no exception, as you need to be savvy in machine learning, deeplearning, language, and more.
It processes enormous amounts of data a human wouldn’t be able to work through in a lifetime and evolves as more data is processed. Challenges of data science Across most companies, finding, cleaning and preparing the proper data for analysis can take up to 80% of a datascientist’s day.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deeplearning. TensorFlow and Keras: TensorFlow is an open-source platform for machine learning.
Hey guys, in this blog we will see some of the most asked Data Science Interview Questions by interviewers in [year]. Data science has become an integral part of many industries, and as a result, the demand for skilled datascientists is soaring. Overfitting: The model performs well only for the sample training data.
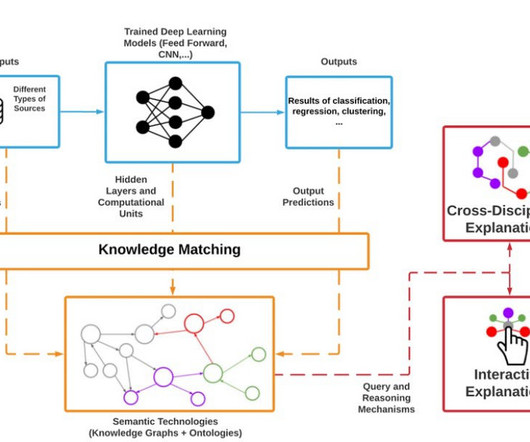
Through the explainability of AI systems, it becomes easier to build trust, ensure accountability, and enable humans to comprehend and validate the decisions made by these models. For example, explainability is crucial if a healthcare professional uses a deeplearning model for medical diagnoses. References Castillo, D.
It offers quick access to key functions and concepts, including data preprocessing, supervised and unsupervised learning techniques, and model evaluation. This resource is invaluable for DataScientists and Machine Learning practitioners, streamlining their workflow and aiding in model development.
The main difference being that while KNN makes assumptions based on data points that are closest together, LOF uses the points that are furthest apart to draw its conclusions. Unsupervised learning Unsupervised learning techniques do not require labeled data and can handle more complex data sets.
It’s a cloud-based platform that provides data visualization, collaboration tools, and advanced tracking and reporting ( Comet-ML , 2023). The platform’s goal is to make machine learning more accessible and efficient for researchers, datascientists, and machine learning practitioners.
Scikit-learn A machine learning powerhouse, Scikit-learn provides a vast collection of algorithms and tools, making it a go-to library for many datascientists. Scikit-learn is also open-source, which makes it a popular choice for both academic and commercial use. And did any of your favorites make it in?
Machine Learning and Neural Networks (1990s-2000s): Machine Learning (ML) became a focal point, enabling systems to learn from data and improve performance without explicit programming. Techniques such as decisiontrees, support vector machines, and neural networks gained popularity.
Introduction Boosting is a powerful Machine Learning ensemble technique that combines multiple weak learners, typically decisiontrees, to form a strong predictive model. Lets explore the mathematical foundation, unique enhancements, and tree-pruning strategies that make XGBoost a standout algorithm. Lower values (e.g.,
Selecting an Algorithm Choosing the correct Machine Learning algorithm is vital to the success of your model. For example, linear regression is typically used to predict continuous variables, while decisiontrees are great for classification and regression tasks. Decisiontrees are easy to interpret but prone to overfitting.
For example, in neural networks, data is represented as matrices, and operations like matrix multiplication transform inputs through layers, adjusting weights during training. Without linear algebra, understanding the mechanics of DeepLearning and optimisation would be nearly impossible.
Data Science is the art and science of extracting valuable information from data. It encompasses data collection, cleaning, analysis, and interpretation to uncover patterns, trends, and insights that can drive decision-making and innovation.
Although MLOps is an abbreviation for ML and operations, don’t let it confuse you as it can allow collaborations among datascientists, DevOps engineers, and IT teams. Model Training Frameworks This stage involves the process of creating and optimizing the predictive models with labeled and unlabeled data. What is MLOps?
Suppose, you are a datascientist working closely with stakeholders or customers, even explaining the model performance and feature selection of a Deeplearning model is quite a task. When it comes to implementing any ML model, the most difficult question asked is how do you explain it. How do we deal with this?
AutoGluon is easy-to-use AutoML tool that uses automatic data processing, hyperparameter tuning, and model ensemble. The best baseline was achieved with a weighted ensemble of gradient boosted decisiontree models. Our model surpassed the AutoGluon baseline model by 121% in recall at 80% precision.
Data Science involves extracting insights from structured and unstructured data using statistical methods, data mining, and visualisation techniques. AI, particularly Machine Learning and DeepLearning uses these insights to develop intelligent models that can predict outcomes, automate processes, and adapt to new information.
Students should learn how to leverage Machine Learning algorithms to extract insights from large datasets. Key topics include: Supervised Learning Understanding algorithms such as linear regression, decisiontrees, and support vector machines, and their applications in Big Data.
Hyperparameters are the configuration variables of a machine learning algorithm that are set prior to training, such as learning rate, number of hidden layers, number of neurons per layer, regularization parameter, and batch size, among others. Boosting can help to improve the accuracy and generalization of the final model.
This is done using machine learning algorithms, such as decisiontrees, support vector machines, or neural networks, which are trained on annotated text data. Classification: Each phrase is then classified into specific named entity categories, such as a person, organization, location, date, or numerical expression.
Hands-on Project Why customer churn matters and how to predict it with machine learning, explained step-by-step Photo by Gabrielle Ribeiro on Unsplash Introduction In today’s competitive business environment, retaining customers is essential to a company’s success. Our project uses Comet ML to: 1.
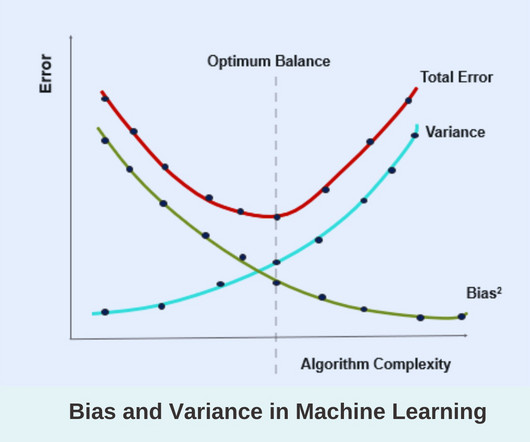
The concepts of bias and variance in Machine Learning are two crucial aspects in the realm of statistical modelling and machine learning. Understanding these concepts is paramount for any datascientist, machine learning engineer, or researcher striving to build robust and accurate models.
Classification is one of the most widely applied areas in Machine Learning. As DataScientists, we all have worked on an ML classification model. A Multiclass Classification is a class of problems where a given data point is classified into one of the classes from a given list. Horizontal Scaling using multi-batch input.
Python packages such as Scikit-learn assist fundamental machine learning algorithms such as classification and regression, whereas Keras, Caffe, and TensorFlow enable deeplearning. quanteda: An R package for the quantitative analysis of textual data ”, Journal of Open Source Software.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content