This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When it comes to data, there are two main types: data lakes and datawarehouses. What is a data lake? An enormous amount of raw data is stored in its original format in a data lake until it is required for analytics applications. Some NoSQL databases are also utilized as platforms for data lakes.
Summary : This guide provides an in-depth look at the top datawarehouse interview questions and answers essential for candidates in 2025. Covering key concepts, techniques, and best practices, it equips you with the knowledge needed to excel in interviews and demonstrates your expertise in data warehousing.
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to data architecture and structured data management that really hit its stride in the early 1990s.
By focusing on particular segments of data, Data marts enhance usability and foster agility in data handling, enabling businesses to respond swiftly to market changes. What is a data mart? This process extracts data from various sources, transforms it into a desired format, and loads it into the data mart.
When companies work with data that is untrustworthy for any reason, it can result in incorrect insights, skewed analysis, and reckless recommendations to become data integrity vs dataquality. Two terms can be used to describe the condition of data: data integrity and dataquality.
generally available on May 24, Alation introduces the Open DataQuality Initiative for the modern data stack, giving customers the freedom to choose the dataquality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and Data Governance application.
There was a time when most CIOs would never consider putting their crown jewels — AKA customer data and associated analytics — into the cloud. But today, there is a magic quadrant for cloud databases and warehouses comprising more than 20 vendors. Yet the cloud, according to Sacolick, doesn’t come cheap. “A Migrate What Matters.
Datawarehouse vs. data lake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a data lake vs. datawarehouse. It lacks many of the important qualities of a traditional database such as ACID compliance.
Summary: A datawarehouse is a central information hub that stores and organizes vast amounts of data from different sources within an organization. Unlike operational databases focused on daily tasks, datawarehouses are designed for analysis, enabling historical trend exploration and informed decision-making.
By understanding how to effectively ingest data, businesses can maximize their operational efficiency and leverage analytics for informed decision-making. What is data ingestion? Data ingestion refers to the process of obtaining and importing data for immediate use or storage in a database.
In this article, we will delve into the concept of data lakes, explore their differences from datawarehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. Before we address the questions, ‘ What is data version control ?’
Discover the nuanced dissimilarities between Data Lakes and DataWarehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are Data Lakes and DataWarehouses. It acts as a repository for storing all the data.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
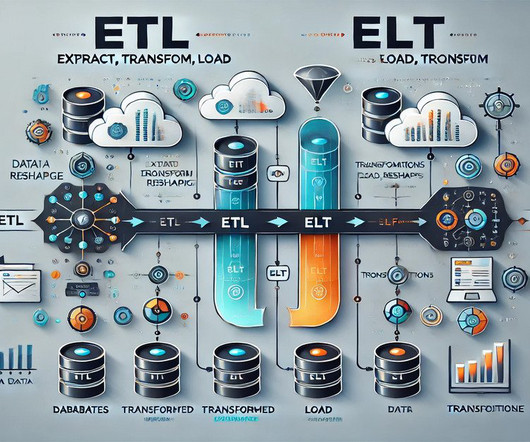
ETL is a three-step process that involves extracting data from various sources, transforming it into a consistent format, and loading it into a target database or datawarehouse. Extract The extraction phase involves retrieving data from diverse sources such as databases, spreadsheets, APIs, or other systems.
Datawarehouse (DW) testers with data integration QA skills are in demand. Datawarehouse disciplines and architectures are well established and often discussed in the press, books, and conferences. Each business often uses one or more data […]. Each business often uses one or more data […].
Dataquality plays a significant role in helping organizations strategize their policies that can keep them ahead of the crowd. Hence, companies need to adopt the right strategies that can help them filter the relevant data from the unwanted ones and get accurate and precise output.
Some of the challenges include discrepancies in the data, inaccurate data, corrupted data and security vulnerabilities. Adding to these headaches, it can be tricky for developers to identify the source of their inaccurate or corrupted data, which complicates efforts to maintain dataquality.
These stages ensure that data flows smoothly from its source to its final destination, typically a datawarehouse or a business intelligence tool. By facilitating a systematic approach to data management, ETL pipelines enhance the ability of organizations to analyze and leverage their data effectively.
A generative AI foundation can provide primitives such as models, vector databases, and guardrails as a service and higher-level services for defining AI workflows, agents and multi-agents, tools, and also a catalog to encourage reuse. Considerations here are choice of vector database, optimizing indexing pipelines, and retrieval strategies.
“Quality over Quantity” is a phrase we hear regularly in life, but when it comes to the world of data, we often fail to adhere to this rule. DataQuality Monitoring implements quality checks in operational data processes to ensure that the data meets pre-defined standards and business rules.
Understanding the data-driven philosophy Organizations excelling in business analytics view data as a vital asset and strive to leverage it for strategic competitive advantages. The effectiveness of business analytics heavily depends on dataquality, expert analysts, and an organizational commitment to data-driven decision-making.
There’s not much value in holding on to raw data without putting it to good use, yet as the cost of storage continues to decrease, organizations find it useful to collect raw data for additional processing. The raw data can be fed into a database or datawarehouse. If it’s not done right away, then later.
The extraction of raw data, transforming to a suitable format for business needs, and loading into a datawarehouse. Data transformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation. Microsoft Azure.
release enhances Tableau Data Management features to provide a trusted environment to prepare, analyze, engage, interact, and collaborate with data. Automate your Prep flows in a defined sequence, with automatic dataquality warnings for any failed runs. Enable dataquality warnings for email subscriptions to dashboards.
Without data engineering , companies would struggle to analyse information and make informed decisions. What Does a Data Engineer Do? A data engineer creates and manages the pipelines that transfer data from different sources to databases or cloud storage. How is Data Engineering Different from Data Science?
release enhances Tableau Data Management features to provide a trusted environment to prepare, analyze, engage, interact, and collaborate with data. Automate your Prep flows in a defined sequence, with automatic dataquality warnings for any failed runs. Enable dataquality warnings for email subscriptions to dashboards.
It is a crucial data integration process that involves moving data from multiple sources into a destination system, typically a datawarehouse. This process enables organisations to consolidate their data for analysis and reporting, facilitating better decision-making. ETL stands for Extract, Transform, and Load.
Getting all the data together, in one place, and integrated is generally the main goal of ourwork. When we need data, we ask our data producers to send us a database connection string, and we pull data out without any formal contract. And ultimately, when this upstream system changes, our pipelines break.
Without the right skillsets, no value can be created from data. New Big Data Concepts vs Cloud Delivered Databases? So, what has the emergence of cloud databases done to change big data? For starters, the cloud has made data more affordable. A key challenge of legacy approaches involved dataquality.
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, datawarehouses, and data lakes.
Cloud-based business intelligence (BI): Cloud-based BI tools enable organizations to access and analyze data from cloud-based sources and on-premises databases. Understand what insights you need to gain from your data to drive business growth and strategy. Ensure that data is clean, consistent, and up-to-date.
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. With these data exploration tools, you can determine if your data is accurate, consistent, and reliable.
Read Common Misconceptions About Master Data Management Most people think of MDM as a means of systematically matching and deduplicating records across multiple databases and applications, but modern MDM plays a far more meaningful role. An ERP does not do dataquality very well. MDM is another downstream datawarehouse.”
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into datawarehouses or databases for analysis.
The ability to effectively deploy AI into production rests upon the strength of an organization’s data strategy because AI is only as strong as the data that underpins it.
Online analytical processing (OLAP) database systems and artificial intelligence (AI) complement each other and can help enhance data analysis and decision-making when used in tandem. Defining OLAP today OLAP database systems have significantly evolved since their inception in the early 1990s.
Modernizing your data infrastructure to hybrid cloud for applications, analytics and gen AI Adopting multicloud and hybrid strategies is becoming mandatory, requiring databases that support flexible deployments across the hybrid cloud. This ensures you have a data foundation that grows with your data needs, wherever your data resides.
Summary: Data ingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances dataquality, enables real-time insights, and supports informed decision-making. Files: Data stored in flat files, CSVs, or Excel sheets.
To harness this data effectively, businesses rely on ETL (Extract, Transform, Load) tools to extract, transform, and load data into centralized systems like datawarehouses. The importance of ETL tools is underscored by their ability to handle diverse data sources, from relational databases to cloud-based services.
However, analysis of data may involve partiality or incorrect insights in case the dataquality is not adequate. Accordingly, the need for Data Profiling in ETL becomes important for ensuring higher dataquality as per business requirements. Evaluate the accuracy and completeness of the data.
A data lake is a centralized repository containing extensive storage for raw, unfiltered data coming into a company’s data storage system. This data can be structured, semi-structured, or unstructured and comes from various sources such as databases, IoT devices, log files, etc.
Collecting, storing, and processing large datasets Data engineers are also responsible for collecting, storing, and processing large volumes of data. This involves working with various data storage technologies, such as databases and datawarehouses, and ensuring that the data is easily accessible and can be analyzed efficiently.
Schema Integration Schema integration deals with reconciling data stored in different database schemas or structures. It involves mapping and transforming data elements to align with a unified schema. It ensures that the integrated data is available for analysis and reporting.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content