
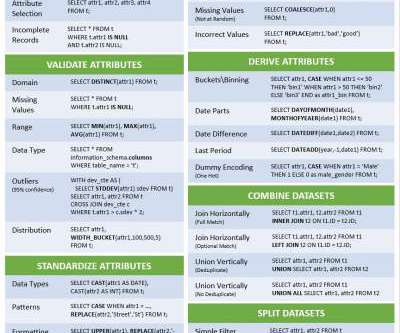
Data Preparation with SQL Cheatsheet
KDnuggets
JUNE 27, 2022
If your raw data is in a SQL-based data lake, why spend the time and money to export the data into a new platform for data prep?
KDnuggets
JUNE 27, 2022
If your raw data is in a SQL-based data lake, why spend the time and money to export the data into a new platform for data prep?

KDnuggets
JULY 20, 2022
14 Essential Git Commands for Data Scientists • Statistics and Probability for Data Science • 20 Basic Linux Commands for Data Science Beginners • 3 Ways Understanding Bayes Theorem Will Improve Your Data Science • Learn MLOps with This Free Course • Primary Supervised Learning Algorithms Used in Machine Learning • Data Preparation with SQL Cheatsheet. (..)
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

IBM Data Science in Practice
JANUARY 2, 2025
By creating microsegments, businesses can be alerted to surprises, such as sudden deviations or emerging trends, empowering them to respond proactively and make data-driven decisions. SQL AssetCreation For each selected value, the system dynamically generates a separate SQL asset. For this example, choose MaritalStatus.

AWS Machine Learning Blog
APRIL 16, 2024
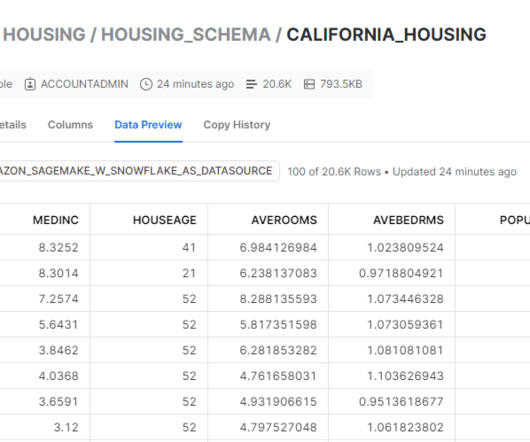
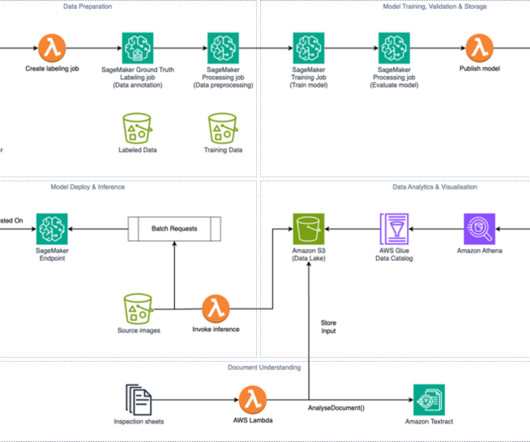
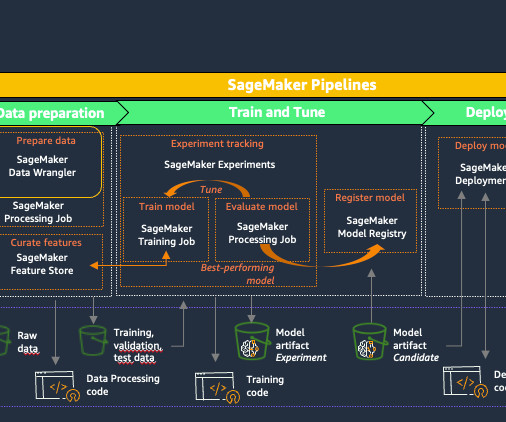
In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them. They then use SQL to explore, analyze, visualize, and integrate data from various sources before using it in their ML training and inference.
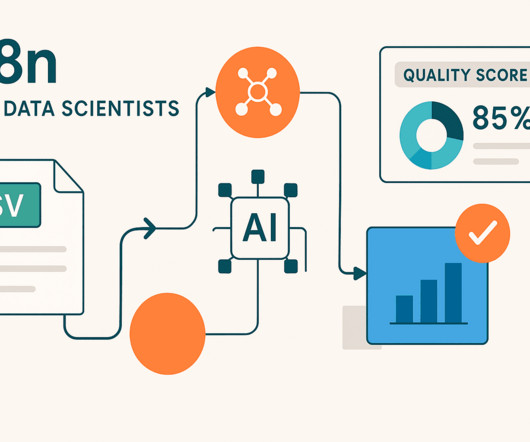
KDnuggets
JUNE 26, 2025
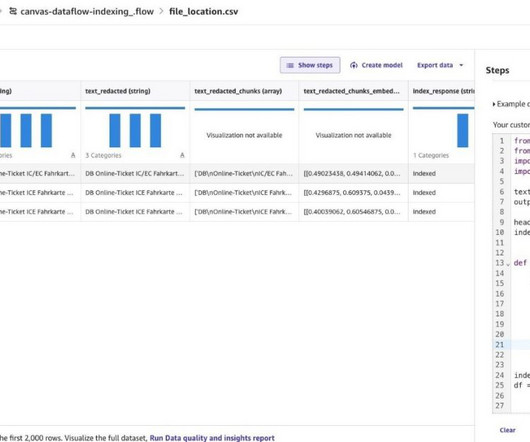
The workflow adapts automatically to any CSV structure, allowing you to quickly assess multiple datasets and prioritize your data preparation efforts. Next Steps 1. Email Integration Add a Send Email node to automatically deliver reports to stakeholders by connecting it after the HTML node.

AWS Machine Learning Blog
OCTOBER 28, 2024
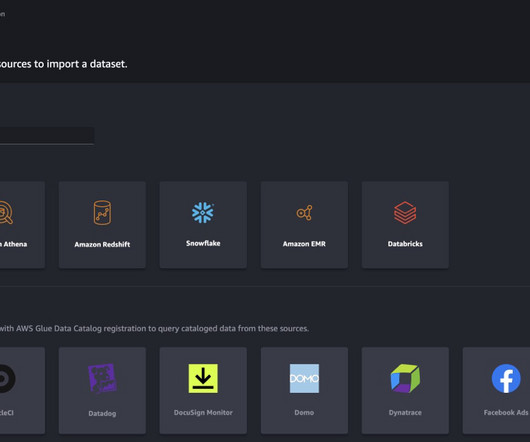
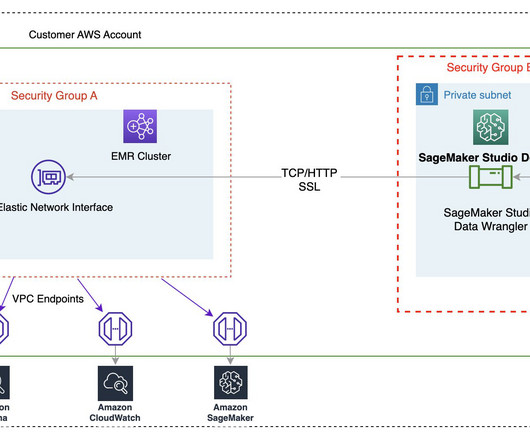
This minimizes the complexity and overhead associated with moving data between cloud environments, enabling organizations to access and utilize their disparate data assets for ML projects. You can use SageMaker Canvas to build the initial data preparation routine and generate accurate predictions without writing code.
Analytics Vidhya
MARCH 13, 2023
It is intended to assist organizations in simplifying the big data and analytics process by providing a consistent experience for data preparation, administration, and discovery. Introduction Microsoft Azure Synapse Analytics is a robust cloud-based analytics solution offered as part of the Azure platform.

Expert insights. Personalized for you.




























Let's personalize your content