This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Exploratory data analysis (EDA) is a critical component of data science that allows analysts to delve into datasets to unearth the underlying patterns and relationships within. EDA serves as a bridge between raw data and actionable insights, making it essential in any data-driven project.
Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from datapreparation to pipeline production. Exploratory Data Analysis (EDA) Data collection: The first step in LLMOps is to collect the data that will be used to train the LLM. What are the benefits of LLMOps?
By analyzing the sentiment of users towards certain products, services, or topics, sentiment analysis provides valuable insights that empower businesses and organizations to make informed decisions, gauge public opinion, and improve customer experiences. Noise in data can arise due to data collection errors, system glitches, or human errors.
Today’s question is, “What does a data scientist do.” ” Step into the realm of data science, where numbers dance like fireflies and patterns emerge from the chaos of information. In this blog post, we’re embarking on a thrilling expedition to demystify the enigmatic role of data scientists.
This practice vastly enhances the speed of my datapreparation for machine learning projects. All you need to do is import them to where they are needed, like below - my-project/ - EDA-demo.ipynb - spark_utils.py # then in EDA-demo.ipynbimport spark_utils as sut I plan to share these helpful pySpark functions in a series of articles.
Before conducting any formal statistical analysis, it’s important to conduct exploratory data analysis (EDA) to better understand the data and identify any patterns or relationships. EDA is an approach that involves using graphical and numerical methods to summarize and visualize the data. Thank you for reading!
It considers precision and recall, providing a more informative evaluation metric that reflects the model’s ability to correctly classify positive instances and avoid false positives and false negatives. Datapreparation, feature engineering, and feature impact analysis are techniques that are essential to model building.
Cross-functional barriers, characterized by limited communication and collaboration between teams, can also impede modernization efforts by hindering information sharing. As a leader in ecommerce solutions, they are committed to meeting the high standards of data privacy and regulatory compliance such as CPPA and PCI.
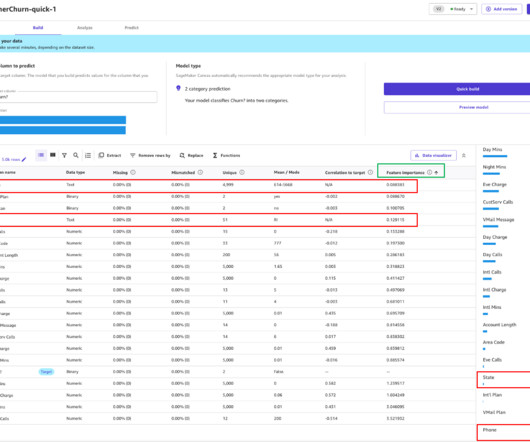
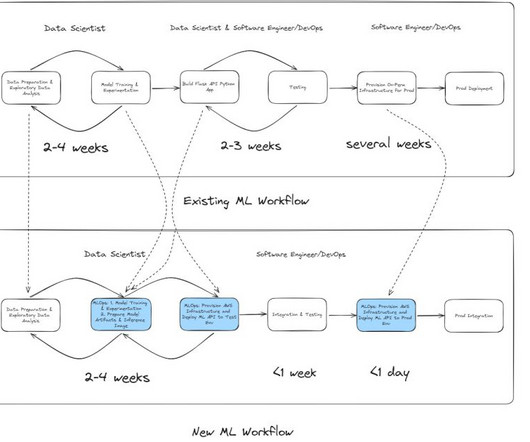
Email classification project diagram The workflow consists of the following components: Model experimentation – Data scientists use Amazon SageMaker Studio to carry out the first steps in the data science lifecycle: exploratory data analysis (EDA), data cleaning and preparation, and building prototype models.
These figures underscore the significance of comprehending data methodologies for anyone navigating the digital landscape. Understanding Data Science Data Science involves analysing and interpreting complex data sets to uncover valuable insights that can inform decision-making and solve real-world problems.
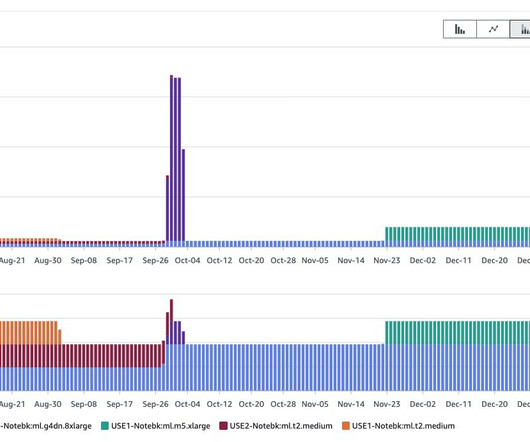
For more information about using Athena, refer to Querying Cost and Usage Reports using Amazon Athena. More information and example queries can be found in the AWS CUR Query Library. You can also feed AWS CUR data into Amazon QuickSight , where you can slice and dice it any way you’d like for reporting or visualization purposes.
Computer Vision This is a field of computer science that deals with the extraction of information from images and videos. DataPreparation for AI Projects Datapreparation is critical in any AI project, laying the foundation for accurate and reliable model outcomes.
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
The simplicity of the code allows users to quickly visualise trends in their data without complicated syntax, making it a powerful tool for beginners and professionals alike. Seaborn Seaborn, a Python visualisation library built on Matplotlib, provides a high-level interface for creating attractive and informative statistical graphics.
For Data Analysis you can focus on such topics as Feature Engineering , Data Wrangling , and EDA which is also known as Exploratory Data Analysis. First learn the basics of Feature Engineering, and EDA then take some different-different data sheets (data frames) and apply all the techniques you have learned to date.
The inferSchema parameter is set to True to infer the data types of the columns, and header is set to True to use the first row as headers. For a comprehensive understanding of the practical applications, including a detailed code walkthrough from datapreparation to model deployment, please join us at the ODSC APAC conference 2023.
Did any past research or previous competitions inform your approach? What has been published about information sharing and inter-sectoral collaboration? The early days of the effort were spent on EDA and exchanging ideas with other members of the community. Do you have any advice for those just getting started in data science?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content