This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
million in seed funding to transform how businesses preparedata for AI, promising to save datascientists from the task that consumes 80% of their time. Brooklyn-based Structify emerges from stealth with $4.1 Read More
Statistical analysis and hypothesis testing Statistical methods provide powerful tools for understanding data. An Applied DataScientist must have a solid understanding of statistics to interpret data correctly. Machine learning algorithms Machine learning forms the core of Applied Data Science.
These tools provide a visual interface for building machine learning pipelines, making the process easier and more efficient for datascientists. One of the main benefits of using drag-and-drop tools in machine learning pipelines is the ease of use. This is where drag-and-drop tools come in. H2O.ai H2O.ai
Deeplearning models built using Maximo Visual Inspection (MVI) are used for a wide range of applications, including image classification and object detection. These models train on large datasets and learn complex patterns that are difficult for humans to recognize. It is more specific as they train artificial neural networks.
Source: Author Introduction Deeplearning, a branch of machine learning inspired by biological neural networks, has become a key technique in artificial intelligence (AI) applications. Deeplearning methods use multi-layer artificial neural networks to extract intricate patterns from large data sets.
Similar to traditional Machine Learning Ops (MLOps), LLMOps necessitates a collaborative effort involving datascientists, DevOps engineers, and IT professionals. The scope of LLMOps within machine learning projects can vary widely, tailored to the specific needs of each project.
Summary: This blog provides a comprehensive roadmap for aspiring Azure DataScientists, outlining the essential skills, certifications, and steps to build a successful career in Data Science using Microsoft Azure. This roadmap aims to guide aspiring Azure DataScientists through the essential steps to build a successful career.
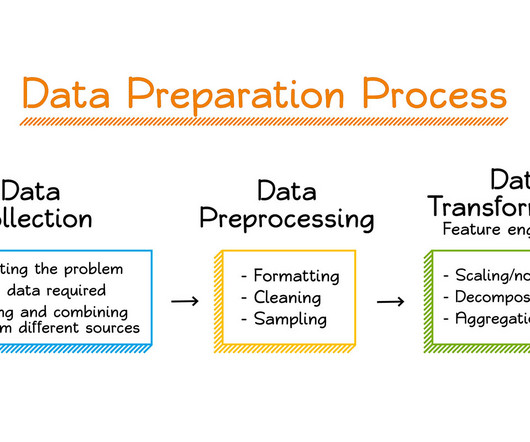
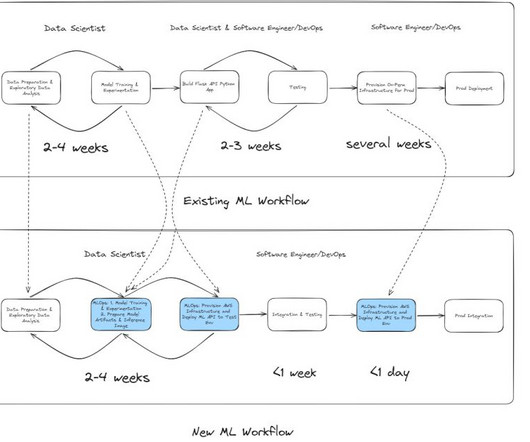
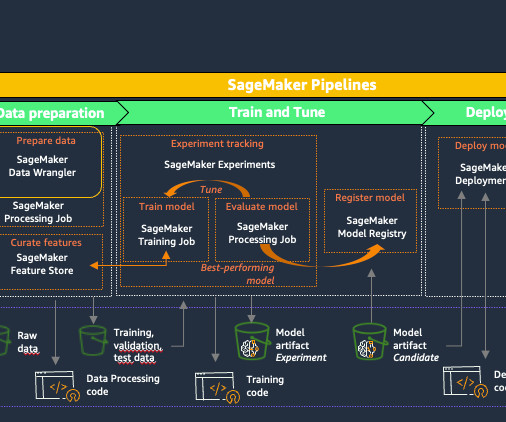
The process begins with datapreparation, followed by model training and tuning, and then model deployment and management. Datapreparation is essential for model training and is also the first phase in the MLOps lifecycle.
Summary: Demystify time complexity, the secret weapon for DataScientists. Explore practical examples, tools, and future trends to conquer big data challenges. Introduction to Time Complexity for DataScientists Time complexity refers to how the execution time of an algorithm scales in relation to the size of the input data.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization.
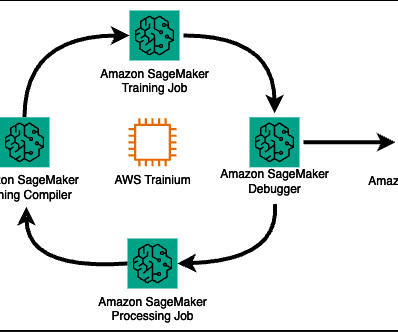
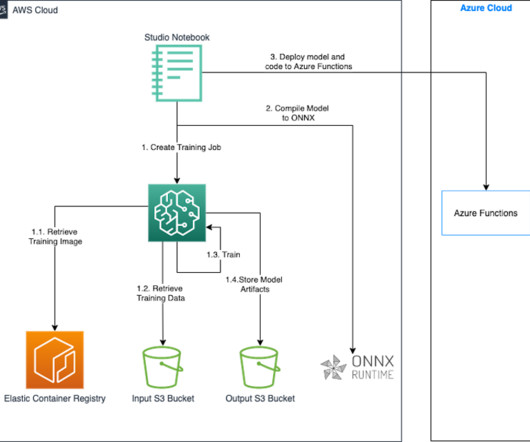
Trainium chips are purpose-built for deeplearning training of 100 billion and larger parameter models. Model training on Trainium is supported by the AWS Neuron SDK, which provides compiler, runtime, and profiling tools that unlock high-performance and cost-effective deeplearning acceleration.
DeepLearning, Machine Learning, and Automation. However, many datascientists and business analysts can’t readily lean on automated regression techniques like logistic regression and linear regression. From a predictive analytics standpoint, you can be surer of its utility.
It maintains your entire machine-learning model (from the creative processes to the execution). MLOps is a highly collaborative effort that aims to manipulate, automate, and generate knowledge through machine learning. First, we have datascientists who are in charge of creating and training machine learning models.
In an increasingly digital and rapidly changing world, BMW Group’s business and product development strategies rely heavily on data-driven decision-making. With that, the need for datascientists and machine learning (ML) engineers has grown significantly. JuMa automatically provisions a new AWS account for the workspace.
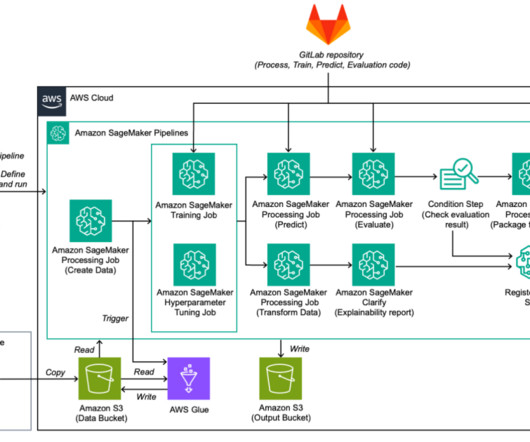
The following diagram shows the workflow for our email classifier project, but can also be generalized to other data science projects. Model deployment – After making sure that everything is running as expected, datascientists merge the develop branch into the primary branch. A test endpoint is deployed for testing purposes.
On the model training side, datascientists often face bottlenecks due to limited resources, forcing them to wait for infrastructure availability or reduce the scope of their experiments. Secure data management is enforced by isolating datasets within Amazon Simple Storage Service (Amazon S3) buckets.
Zeta’s AI innovations over the past few years span 30 pending and issued patents, primarily related to the application of deeplearning and generative AI to marketing technology. It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing data pipelines.
However, a new paradigm has entered the chat, as LLMs don’t follow the same rules and expectations of traditional machine learning models. As such, datascientists need to find a different approach for using MLOps to find structure and create a sense of order as LLMs are developed.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring. Check out the Kubeflow documentation.
Feature engineering activities frequently focus on single-table data transformations, leading to the infamous “yawn factor.” Let’s be honest — one-hot-encoding isn’t the most thrilling or challenging task on a datascientist’s to-do list. One might say that tabular data modeling is the original data-centric AI!
Allen Downey, PhD, Principal DataScientist at PyMCLabs Allen is the author of several booksincluding Think Python, Think Bayes, and Probably Overthinking Itand a blog about data science and Bayesian statistics. This years event is no different, and heres a rundown of 15 fan-favorite speakers who are returning onceagain.
Amazon SageMaker provides purpose-built tools for machine learning operations (MLOps) to help automate and standardize processes across the ML lifecycle. Improve the quality and time to market for deeplearning models in diagnostic medical imaging.
After some impressive advances over the past decade, largely thanks to the techniques of Machine Learning (ML) and DeepLearning , the technology seems to have taken a sudden leap forward. It helps facilitate the entire data and AI lifecycle, from datapreparation to model development, deployment and monitoring.
This post is co-written with Swagata Ashwani, Senior DataScientist at Boomi. The exact steps to replicate this process are outlined Train and deploy deeplearning models using JAX with Amazon SageMaker. Swagata Ashwani is a Senior DataScientist at Boomi with over 6+ years experience in Data Science.
Key concepts Amazon SageMaker Studio is a web-based, integrated development environment (IDE) for machine learning. SageMaker Studio allows datascientists, ML engineers, and data engineers to preparedata, build, train, and deploy ML models on one web interface. dummy_input = torch.randn(1, 1, 28, 28).to(device)
SageMaker pipeline steps The pipeline is divided into the following steps: Train and test datapreparation – Terabytes of raw data are copied to an S3 bucket, processed using AWS Glue jobs for Spark processing, resulting in data structured and formatted for compatibility.
Datascientists and developers can quickly prototype and experiment with various ML use cases, accelerating the development and deployment of ML applications. SageMaker Studio is an IDE that offers a web-based visual interface for performing the ML development steps, from datapreparation to model building, training, and deployment.
Customers increasingly want to use deeplearning approaches such as large language models (LLMs) to automate the extraction of data and insights. For many industries, data that is useful for machine learning (ML) may contain personally identifiable information (PII).
Because ML is becoming more integrated into daily business operations, data science teams are looking for faster, more efficient ways to manage ML initiatives, increase model accuracy and gain deeper insights. MLOps is the next evolution of data analysis and deeplearning.
RapidMiner RapidMiner, a renowned player in the realm of machine learning tools, offers an all-encompassing platform for a myriad of operations. Its functionalities span from deeplearning to text mining, datapreparation, and predictive analytics, ensuring a versatile utility for developers and datascientists alike.
With all the talk about new AI-powered tools and programs feeding the imagination of the internet, we often forget that datascientists don’t always have to do everything 100% themselves. PyCaret allows data professionals to build and deploy machine learning models easily and efficiently.
RPA uses a graphical user interface (GUI) to interact with applications and websites, while ML uses algorithms and statistical models to analyze data. On the other hand, ML requires a significant amount of datapreparation and model training before it can be deployed.
Here’s a breakdown of ten top sessions from this year’s conference that data professionals should consider. Topological DeepLearning Made Easy with TopoX with Dr. Mustafa Hajij Slides In these AI slides, Dr. Mustafa Hajij introduced TopoX, a comprehensive Python suite for topological deeplearning.
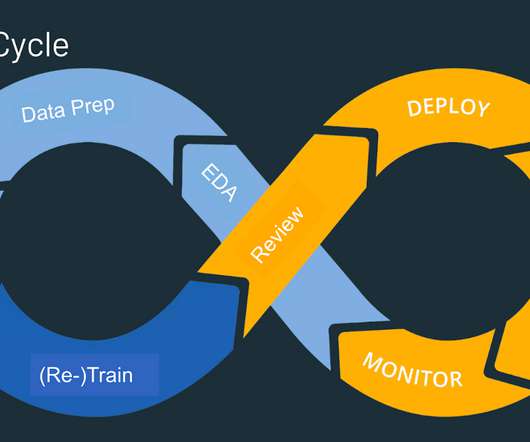
Understanding the MLOps Lifecycle The MLOps lifecycle consists of several critical stages, each with its unique challenges: Data Ingestion: Collecting data from various sources and ensuring it’s available for analysis. DataPreparation: Cleaning and transforming raw data to make it usable for machine learning.
Artificial intelligence platforms enable individuals to create, evaluate, implement and update machine learning (ML) and deeplearning models in a more scalable way. AI platform tools enable knowledge workers to analyze data, formulate predictions and execute tasks with greater speed and precision than they can manually.
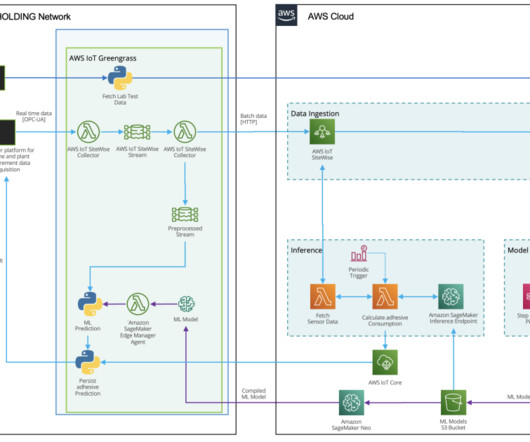
Data ingestion HAYAT HOLDING has a state-of-the art infrastructure for acquiring, recording, analyzing, and processing measurement data. Model training and optimization with SageMaker automatic model tuning Prior to the model training, a set of datapreparation activities are performed. Hayat” means “life” in Turkish.
These data owners are focused on providing access to their data to multiple business units or teams. Data science team – Datascientists need to focus on creating the best model based on predefined key performance indicators (KPIs) working in notebooks. The following figure illustrates their journey.
A DataBrew job extracts the data from the TR data warehouse for the users who are eligible to provide recommendations during renewal based on the current subscription plan and recent activity. Hesham Fahim is a Lead Machine Learning Engineer and Personalization Engine Architect at Thomson Reuters.
Machine Learning Frameworks Comet integrates with a wide range of machine learning frameworks, making it easy for teams to track and optimize their models regardless of the framework they use. Ludwig Ludwig is a machine learning framework for building and training deeplearning models without the need for writing code.
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
Note : Now, Start joining Data Science communities on social media platforms. These communities will help you to be updated in the field, because there are some experienced datascientists posting the stuff, or you can talk with them so they will also guide you in your journey.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deeplearning. TensorFlow and Keras: TensorFlow is an open-source platform for machine learning.
Amazon SageMaker is a fully managed machine learning (ML) service. With SageMaker, datascientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. All code for this post is available in the GitHub repo.
It leverages sentence transformers to embed the text data and fine-tunes the head layer to perform the classification task. SetFit's two-stage training process — src Few-Shot Training — DataPreparation As explained, we are all set to train the SetFit model with a handful of data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content