This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
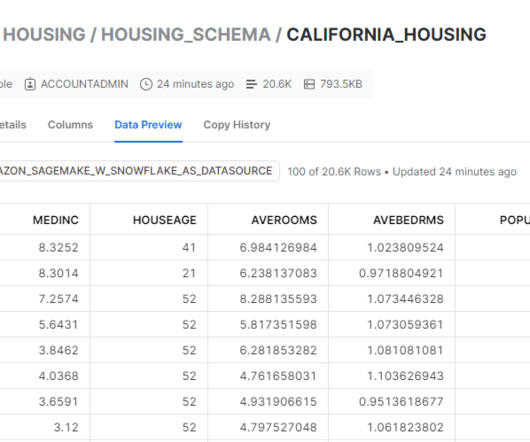
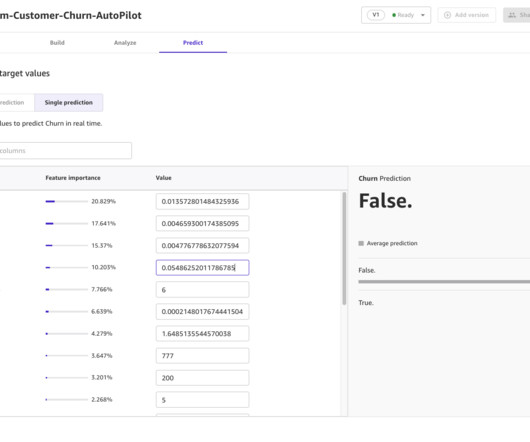
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler. You can download the dataset loans-part-1.csv
Amazon SageMaker Data Wrangler provides a visual interface to streamline and accelerate datapreparation for machine learning (ML), which is often the most time-consuming and tedious task in ML projects. Charles holds an MS in Supply Chain Management and a PhD in DataScience.
Conventional ML development cycles take weeks to many months and requires sparse datascience understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and datascience team’s bandwidth and datapreparation activities.
In such situations, it may be desirable to have the data accessible to SageMaker in the ephemeral storage media attached to the ephemeral training instances without the intermediate storage of data in Amazon S3. We add this data to Snowflake as a new table. Launch a SageMaker Training job for training the ML model.
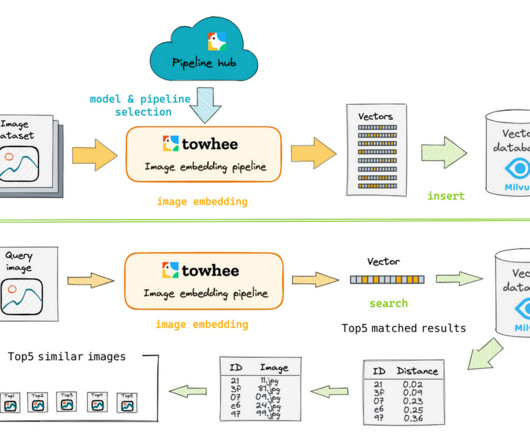
DataPreparation Here we use a subset of the ImageNet dataset (100 classes). You can follow command below to download the data. Data Insert This step uses an Insert Pipeline to insert image embeddings into Milvus collection. Search pipeline Preprocess the query image following the same steps as datapreparation.
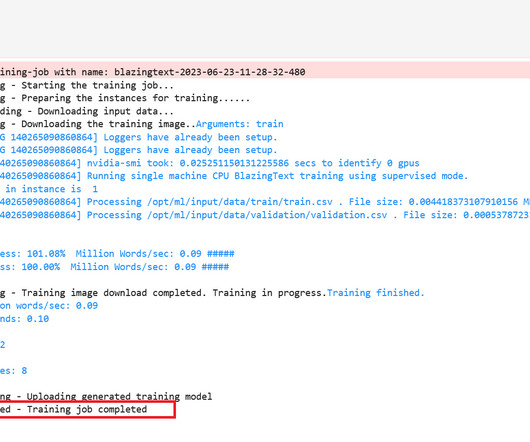
We walk you through the following steps to set up our spam detector model: Download the sample dataset from the GitHub repo. Load the data in an Amazon SageMaker Studio notebook. Prepare the data for the model. Download the dataset Download the email_dataset.csv from GitHub and upload the file to the S3 bucket.
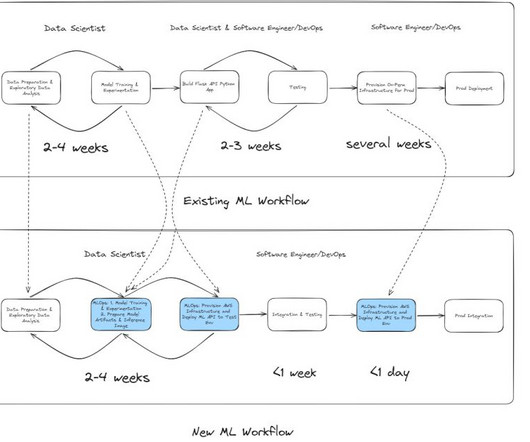
Legacy workflow: On-premises ML development and deployment When the datascience team needed to build a new fraud detection model, the development process typically took 24 weeks. The legacy ML workflow presented several challenges, particularly in the time-intensive model development and deployment processes.
With Canvas, you can take ML mainstream throughout your organization so business analysts without datascience or ML experience can use accurate ML predictions to make data-driven decisions. This means empowering business analysts to use ML on their own, without depending on datascience teams.
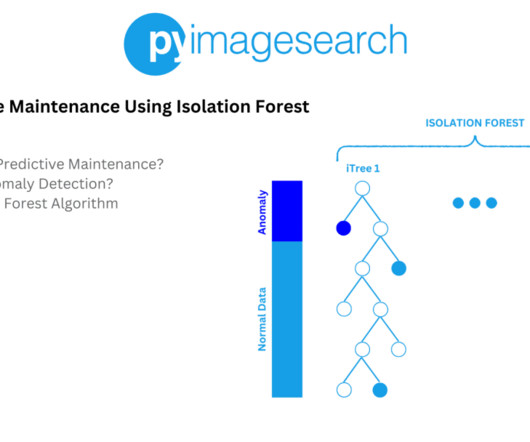
Figure 3: Isolation Forest isolates anomalies by randomly selecting a feature and splitting the data (source: DataScience Demystified ). Figure 4: Isolation Tree is a binary tree structure built by recursively partitioning the data (source: DataScience Demystified ). temperature, pressure, vibration, etc.)
SageMaker Studio allows data scientists, ML engineers, and data engineers to preparedata, build, train, and deploy ML models on one web interface. The code snippets in the following sections have been tested in the SageMaker Studio notebook environment using the DataScience 3.0 image and Python 3.0
Snowflake is a cloud data platform that provides data solutions for data warehousing to datascience. Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. You can either download the report or view it online.
Download the Machine Learning Project Checklist. Download Now. Machine learning and AI empower organizations to analyze data, discover insights, and drive decision making from troves of data. Evaluate the computing resources and development environment that the datascience team will need. Download Now.
Prepare the dataset for fine-tuning We use the low-resource language Marathi for the fine-tuning task. Using the Hugging Face datasets library, you can download and split the Common Voice dataset into training and testing datasets. The source code associated with this implementation can be found on GitHub.
Meta Llama3 8B is a gated model on Hugging Face, which means that users must be granted access before they’re allowed to download and customize the model. QLoRA quantizes a pretrained language model to 4 bits and attaches smaller low-rank adapters (LoRA), which are fine-tuned with our training data.
Studio provides all the tools you need to take your models from datapreparation to experimentation to production while boosting your productivity. Check that the SageMaker image selected is a Conda-supported first-party kernel image such as “DataScience.” Choose Open Launcher.
You can watch the full video of this session here and download the slideshere. Common Pitfalls in LLM Development Neglecting DataPreparation: Poorly prepareddata leads to subpar evaluation and iterations, reducing generalizability and stakeholder confidence. For instance: DataPreparation: GoogleSheets.
This integration of model development and sharing creates a tighter collaboration between business and datascience teams and lowers time to value. Business teams can use existing models built by their data scientists or other departments to solve a business problem instead of rebuilding new models in outside environments.
Each step of the workflow is developed in a different notebook, which are then converted into independent notebook jobs steps and connected as a pipeline: Preprocessing – Download the public SST2 dataset from Amazon Simple Storage Service (Amazon S3) and create a CSV file for the notebook in Step 2 to run.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
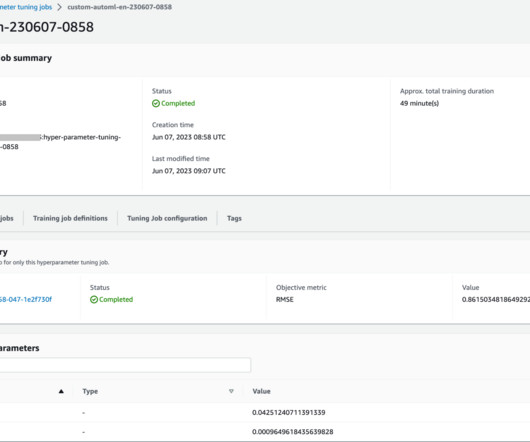
AutoML has grown into a more widely applicable means of automating a wide array of machine learning tasks, including datapreparation, model selection, feature selection, and engineering, as well as hyperparameter tuning. Download Now. INDUSTRY ANALYST REPORT. Omdia Universe: Selecting an Enterprise MLOps Platform, 2021.
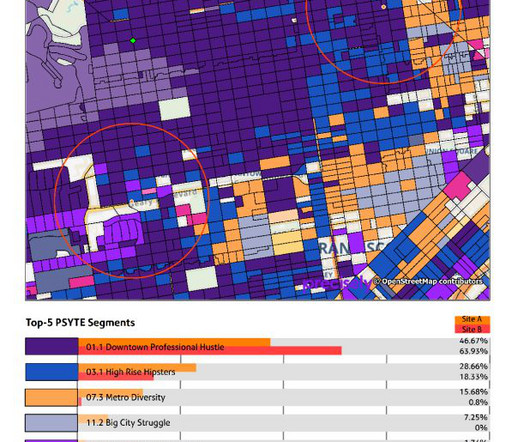
This is where location intelligence (LI) shines – answering those key questions and unlocking insights that inform smarter data-driven decision-making. Download Trending Now: Location Intelligence Drivers Spatial analytics tools aren’t new to the marketplace – in fact, some have been around for decades. Start your free trial now.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring. Check out the Metaflow Docs. neptune.ai
Hugging Face Hub – If your SageMaker Studio domain has access to download models from the Hugging Face Hub , you can use the AutoModelForCausalLM class from huggingface/transformers to automatically download models and pin them to your local GPUs. The model weights will be stored in your local machine’s cache. resource('s3').
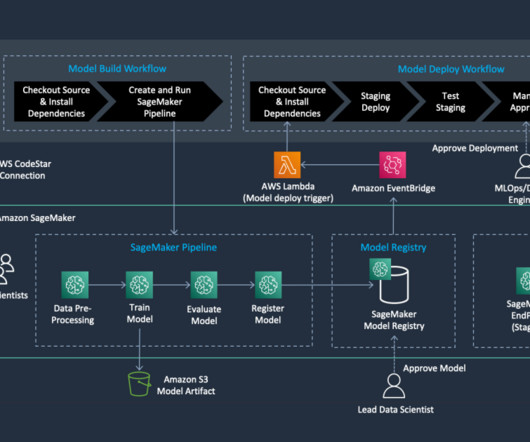
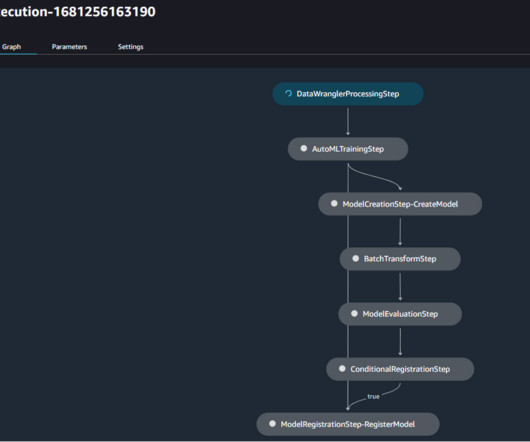
We create an automated model build pipeline that includes steps for datapreparation, model training, model evaluation, and registration of the trained model in the SageMaker Model Registry. Download the template.yml file to your computer. Upload the template you downloaded. Choose Create a new portfolio. Choose Review.
It plays a crucial role in every model’s development process and allows data scientists to focus on the most promising ML techniques. Additionally, AutoML provides a baseline model performance that can serve as a reference point for the datascience team. He is most passionate about MlOps and traditional datascience.
For Prepare template , select Template is ready. Choose Choose File and navigate to the location on your computer where the CloudFormation template was downloaded and choose the file. If you are prompted to choose a kernel, choose DataScience as the image and Python 3 as the kernel, then choose Select.
Figure 1: LLaVA architecture Preparedata When it comes to fine-tuning the LLaVA model for specific tasks or domains, datapreparation is of paramount importance because having high-quality, comprehensive annotations enables the model to learn rich representations and achieve human-level performance on complex visual reasoning challenges.
We selected the model with the most downloads at the time of this writing. 0, 1, 2 Reference architecture In this post, we use Amazon SageMaker Data Wrangler to ask a uniform set of visual questions for thousands of photos in the dataset. The next figure offers a view of how the full-scale data transformation job is run.
Jump Right To The Downloads Section Understanding Anomaly Detection: Concepts, Types, and Algorithms What Is Anomaly Detection? Anomaly detection ( Figure 2 ) is a critical technique in data analysis used to identify data points, events, or observations that deviate significantly from the norm.
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
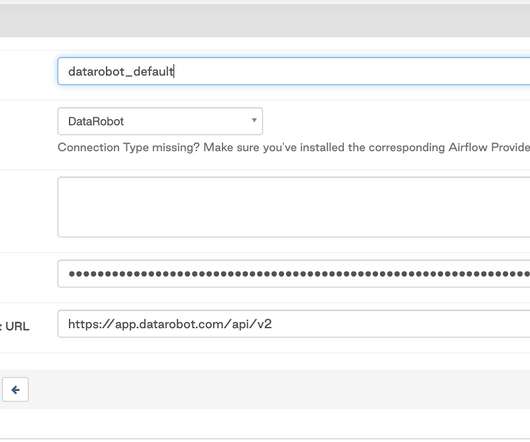
To make it available, download the DAG file from the repository to the dags/ directory in your project (browse GitHub tags to download to the same source code version as your installed DataRobot provider) and refresh the page. Multipersona DataScience and Machine Learning (DSML) Platforms. Download now.
Users can download datasets in formats like CSV and ARFF. How to Access and Use Datasets from the UCI Repository The UCI Machine Learning Repository offers easy access to hundreds of datasets, making it an invaluable resource for data scientists, Machine Learning practitioners, and researchers. CSV, ARFF) to begin the download.
Train a recommendation model in SageMaker Studio using training data that was prepared using SageMaker Data Wrangler. The real-time inference call data is first passed to the SageMaker Data Wrangler container in the inference pipeline, where it is preprocessed and passed to the trained model for product recommendation.
DataPreparation You will use the Ants and Bees classification dataset available on Kaggle. To download it, you will use the Kaggle package. Create your API keys on your Account’s Settings page and it will download a JSON file. Open it, copy the username and key, and set the environment variables as shown below.
Step 1: Clone Repository and Download Requirements To begin with, you need to clone the official YoloV7 repository as follows: $ git clone [link] Note: If you do not have Git installed in your system, then you can download and install it from here and then run the above command, or you can download the code in zip format from here.
Solution overview In this solution, we start with datapreparation, where the raw datasets can be stored in an Amazon Simple Storage Service (Amazon S3) bucket. We provide a Jupyter notebook to preprocess the raw data and use the Amazon Titan Multimodal Embeddings model to convert the image and text into embedding vectors.
Alteryx provides organizations with an opportunity to automate access to data, analytics , datascience, and process automation all in one, end-to-end platform. Its capabilities can be split into the following topics: automating inputs & outputs, datapreparation, data enrichment, and datascience.
Talo Thomson, Content Marketing Manager, Alation: You two are data scientists. Why will other data people be interested in these case studies? Andrea Levy, Technical Lead, DataScience & Analytics, Alation: First of all: impact! Get the latest data cataloging news and trends in your inbox.
MLOps is a set of principles and practices that combine software engineering, datascience, and DevOps to ensure that ML models are deployed and managed effectively in production. MLOps encompasses the entire ML lifecycle, from datapreparation to model deployment and monitoring. This is where MLOps comes in.
However, if there’s one thing we’ve learned from years of successful cloud data implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account. Download a free PDF by filling out the form. How Can phData Help?
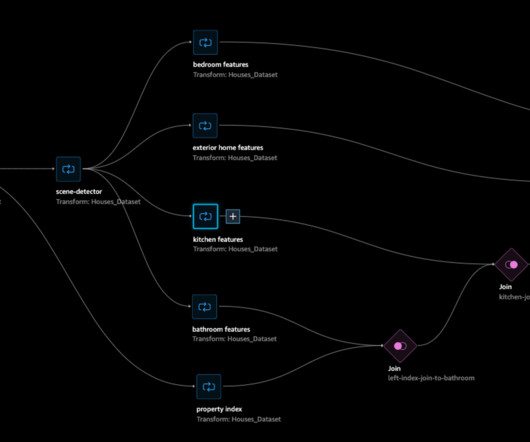
Data Wrangler provides an end-to-end solution to import, prepare, transform, featurize, and analyze data. You can integrate a Data Wrangler datapreparation flow into your ML workflows to simplify and streamline data preprocessing and feature engineering using little to no coding.
Data preprocessing Text data can come from diverse sources and exist in a wide variety of formats such as PDF, HTML, JSON, and Microsoft Office documents such as Word, Excel, and PowerPoint. Its rare to already have access to text data that can be readily processed and fed into an LLM for training. Graham Horwood is Sr.
Pixlr Pixlr s AI-powered online editor offers advanced image manipulation without requiring software downloads. These AI-powered platforms enhance decision-making, automate reporting, and simplify complex data operations. Its great for social media graphics, ads, and quick visual touch-ups.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content