

Looking Ahead: The Future of Data Preparation for Generative AI
Data Science Blog
AUGUST 22, 2024
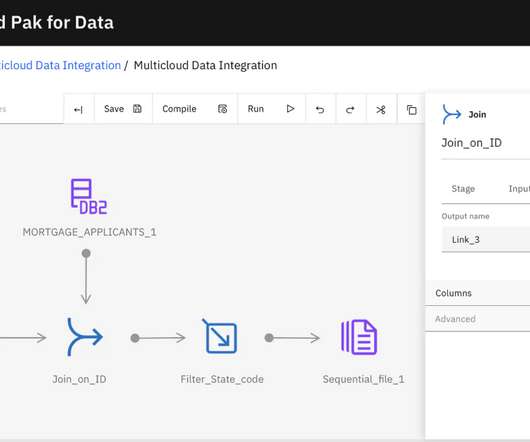
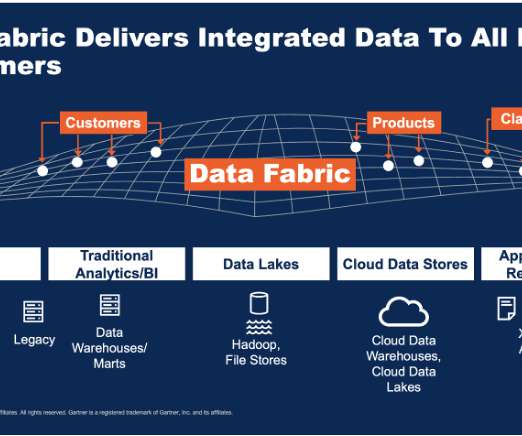
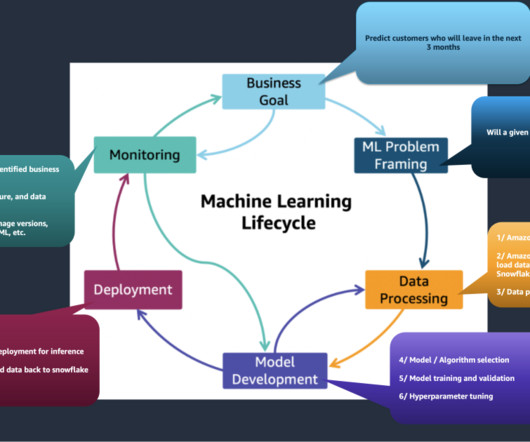
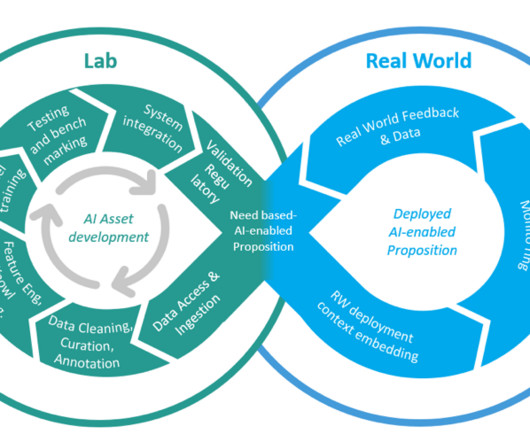
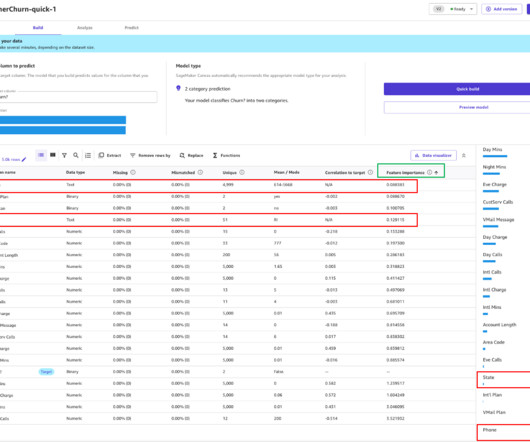
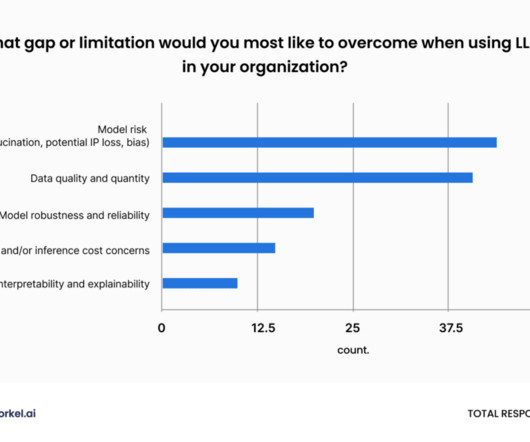
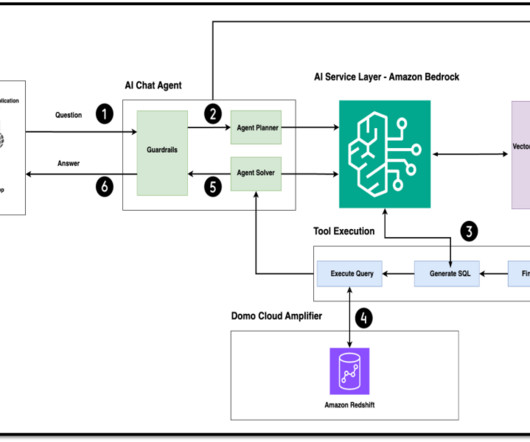
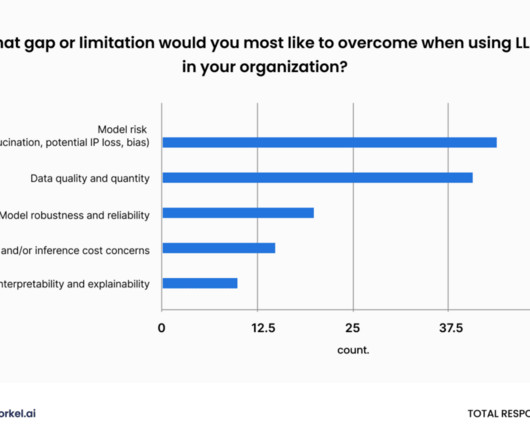
Businesses need to understand the trends in data preparation to adapt and succeed. If you input poor-quality data into an AI system, the results will be poor. This principle highlights the need for careful data preparation, ensuring that the input data is accurate, consistent, and relevant.






































Let's personalize your content