This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Are you curious about the latest advancements in the data tech industry? In that case, we invite you to check out DataHour, a series of webinars led by experts in the field. Perhaps you’re hoping to advance your career or transition into this field.
The blog is based on the webinar Deploying Gen AI in Production with NVIDIA NIM & MLRun with Amit Bleiweiss, Senior Data Scientist at NVIDIA, and Yaron Haviv, co-founder and CTO and Guy Lecker, ML Engineering Team Lead at Iguazio (acquired by McKinsey). You can watch the entire webinar here.
You can easily: Store and process data using S3 and RedShift Create datapipelines with AWS Glue Deploy models through API Gateway Monitor performance with CloudWatch Manage access control with IAM This integrated ecosystem makes it easier to build end-to-end machine learning solutions.
As a proud member of the Connect with Confluent program , we help organizations going through digital transformation and IT infrastructure modernization break down data silos and power their streaming datapipelines with trusted data.
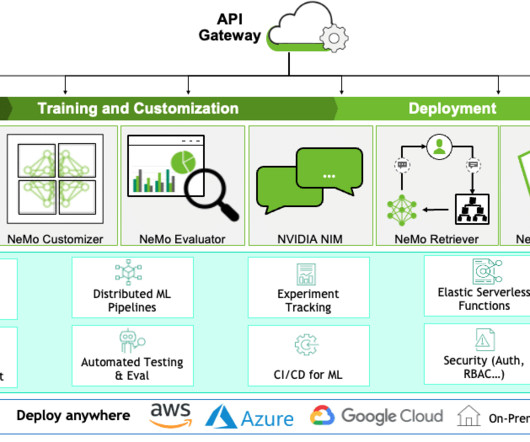
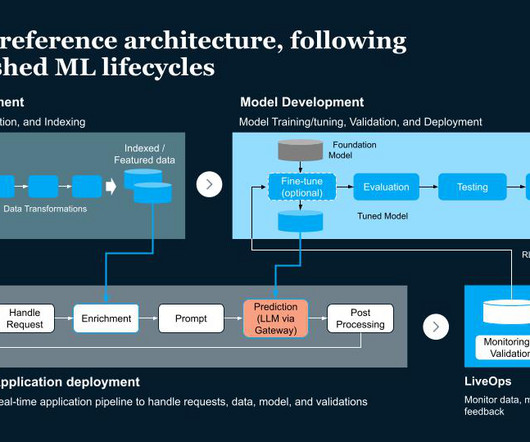
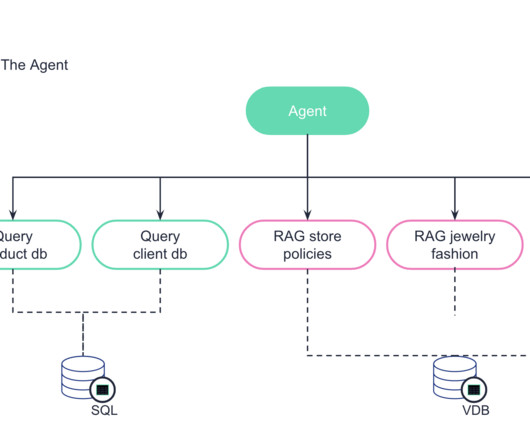
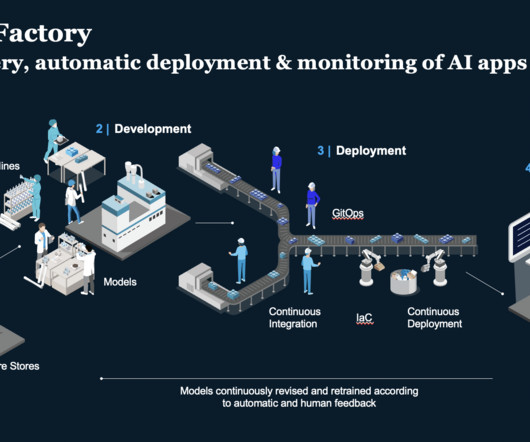
The 4 Gen AI Architecture Pipelines The four pipelines are: 1. The DataPipeline The datapipeline is the foundation of any AI system. It's responsible for collecting and ingesting the data from various external sources, processing it and managing the data.
Every company today is being asked to do more with less, and leaders need access to fresh, trusted KPIs and data-driven insights to manage their businesses, keep ahead of the competition, and provide unparalleled customer experiences. . But good data—and actionable insights—are hard to get. Optimize recruiting pipelines.
Every company today is being asked to do more with less, and leaders need access to fresh, trusted KPIs and data-driven insights to manage their businesses, keep ahead of the competition, and provide unparalleled customer experiences. . But good data—and actionable insights—are hard to get. Optimize recruiting pipelines.
To learn more, watch the webinar “Implementing Gen AI for Financial Services” with Larry Lerner, Partner & Global Lead - Banking and Securities Analytics, McKinsey & Company, and Yaron Haviv, Co-founder and CTO, Iguazio (acquired by McKinsey), which this blog post is based on. View the entire webinar here. Read more here.
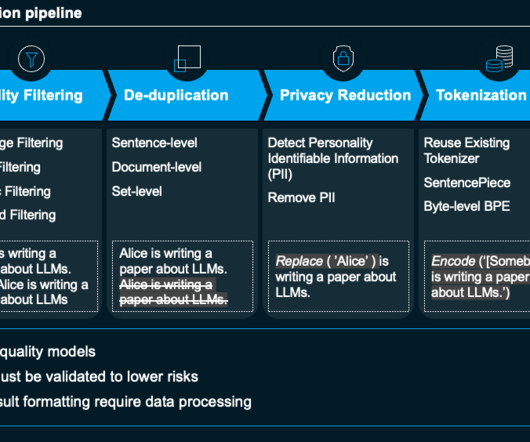
The integrated solution allows customers to streamline data processing and storage, ensuring Gen AI applications reach production while eliminating risks, improving performance and enhancing governance. Iguazio capabilities: Structured and unstructured datapipelines for processing, versioning and loading documents.
Every organization wants to better serve its customers, and that goal is often achieved through data. DataPipeline Capabilities This team’s scope is massive because the datapipelines are huge and there are many different capabilities embedded in them. You don’t have to write ETL jobs.” Invest in automation.
.” This user interface not only brings Apache Flink to anyone that can add business value, but it also allows for experimentation that has the potential to drive innovation speed up your data analytics and datapipelines. Hungry for more?
Here are five data quality best practices which business leaders should focus. Think holistically: Address the entire datapipelineData quality should not simply be focused on finding and fixing existing problems within static data. Waiting until later risks sending a bogus “lead” to inside sales for follow up.
In a recent webinar, AI Mastery 2025: Skills to Stay Ahead in the Next Wave, hosted by Sheamus McGovern, founder of ODSC and a venture partner at Cortical Ventures, shared invaluable insights into the evolving AI landscape. LLM Engineers: With job postings far exceeding the current talent pool, this role has become one of the hottest inAI.
In a recent webinar hosted by Fintech Nexus, Doug Lopp, CTO of Bend by FNBO, remarked on the role of technology in today’s financial services organizations: “Business and technology are starting to align much more closely than they ever have before, to the point where they are indistinguishable. Real-time data is the goal.
Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication. Standard data science practices could also be contributing to this issue. With all the attention on generative AI, tabular data isn’t getting the attention it deserves.
Now, everyone can see the data… even Dancer, who’s fighting his way off the naughty list after spiking the reindeer trough with eggnog in the ‘80s. Get the most out of their Snowflake data cloud. Did anyone else catch Frizzle and Sparkle on our joint webinars this quarter? Boost collective data literacy and showcase experts.
Every company today is being asked to do more with less, and leaders need access to fresh, trusted KPIs and data-driven insights to manage their businesses, keep ahead of the competition, and provide unparalleled customer experiences. But good data—and actionable insights—are hard to get. What is Salesforce Data Cloud for Tableau?
As the algorithms we use have gotten more robust and we have increased our compute power through new technologies, we haven’t made nearly as much progress on the data part of our jobs. Because of this, I’m always looking for ways to automate and improve our datapipelines. So why should we use datapipelines?
Data from an ERP or MDM system could come in as raw, with technical names that match the source, and have some limited data definitions but no data quality aspects. These reports (combined with updates to the data governance roadmap, and your progress narrative) tell a great story. Curious to hear from the author?
Participate in webinars, attend conferences, and join relevant professional communities. Build a portfolio: Develop a portfolio of BI projects that showcase your skills and demonstrate your ability to deliver actionable insights through effective data visualization and reporting.
But a lot of what we’re talking about here is trying to build datapipelines that are going to run. Look at our events page to sign up for research webinars, product overviews, and case studies. The post McKinsey QuantumBlack on automating data quality remediation with AI appeared first on Snorkel AI.
This section explores popular software and frameworks for Data Analysis and modelling is designed to cater to the diverse needs of Data Scientists: Azure Data Factory This cloud-based data integration service enables the creation of data-driven workflows for orchestrating and automating data movement and transformation.
For more details, watch the webinar this blog post is based on. The webinar hosts Eli Stein, Partner and Modern Marketing Capabilities Leader from McKinsey, Ze’ev Rispler, ML Engineer, from Iguazio (acquired by McKinsey), and myself. Watch the entire webinar here.
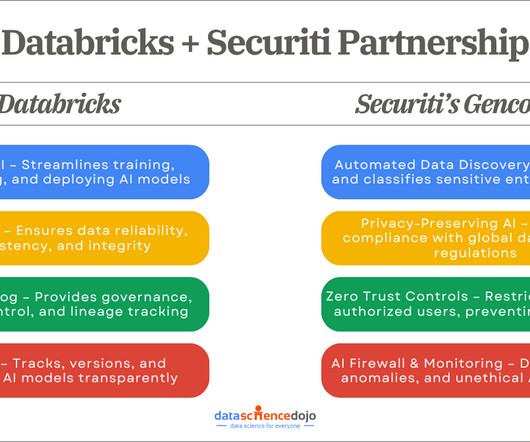
The partnership between Databricks and Gencore AI enables enterprises to develop AI applications with robust security measures, optimized datapipelines, and comprehensive governance. Optimized DataPipelines for AI Readiness AI models are only as good as the data they process.
To see the complete conversation and dive into their insights, watch the webinar here. See the webinar for more Gartner trends. Quality, Scalability and Continuous Delivery Implementing modularity with LLM, data, and API abstractions to ensure flexibility Implementing tests for models, prompts, application logic, etc.
Must-Have Skills for Data Engineers: Cloud Platforms : Expertise in AWS, Azure, and Google Cloud Platform (GCP) is vital for managing and deploying cloud-based data infrastructure. Database Management : It is crucial to have knowledge of both relational (e.g., MySQL, PostgreSQL) and non-relational (e.g., MongoDB, Cassandra) databases.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content