This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
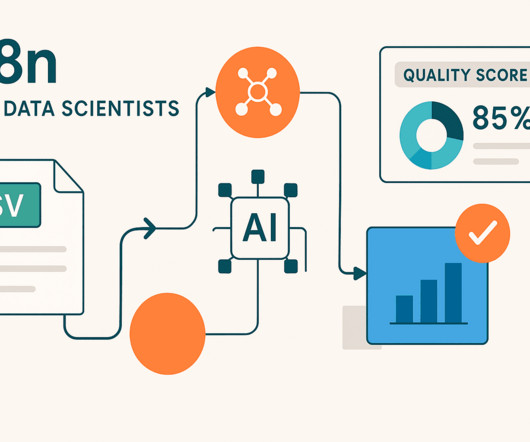
By Cornellius Yudha Wijaya , KDnuggets Technical Content Specialist on July 17, 2025 in Data Science Image by Author | Ideogram Data is the asset that drives our work as data professionals. Thus, securing suitable data is crucial for any data professional, and datapipelines are the systems designed for this purpose.
By Josep Ferrer , KDnuggets AI Content Specialist on July 15, 2025 in Data Science Image by Author Delivering the right data at the right time is a primary need for any organization in the data-driven society. But lets be honest: creating a reliable, scalable, and maintainable datapipeline is not an easy task.
Datapipelines are essential in our increasingly data-driven world, enabling organizations to automate the flow of information from diverse sources to analytical platforms. What are datapipelines? Purpose of a datapipelineDatapipelines serve various essential functions within an organization.
As a data scientist, you can access your BigQuery Sandbox from a Colab notebook. With just a few lines of authentication code, you can run SQL queries right from a notebook and pull the results into a Python DataFrame for analysis. MemoryError exceptions are all too common, forcing you to downsample your data early on.
From UI improvements to more advanced workflow control, check out the latest in Databricks’ native data orchestration solution and discover how data engineers can streamline their end-to-end datapipeline experience. More controlled and efficient data flows Our orchestrator is constantly being enhanced with new features.
Get a Demo Login Try Databricks Blog / Platform / Article What’s New with Azure Databricks: Unified Governance, Open Formats, and AI-Native Workloads Explore the latest Azure Databricks capabilities designed to help organizations simplify governance, modernize datapipelines, and power AI-native applications on a secure, open platform.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 10 Python Math & Statistical Analysis One-Liners Python makes common math and stats tasks super (..)
For most organizations, this gap remains stubbornly wide, with business teams trapped in endless cycles—decoding metric definitions and hunting for the correct data sources to manually craft each SQL query. Amazon’s Worldwide Returns & ReCommerce (WWRR) organization faced this challenge at scale.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 10 Surprising Things You Can Do with Python’s collections Module This tutorial explores ten practical (..)
🔗 Link to the code on GitHub Why Data Cleaning Pipelines? Think of datapipelines like assembly lines in manufacturing. Wrapping Up Datapipelines arent just about cleaning individual datasets. Each step performs a specific function, and the output from one step becomes the input for the next.
By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: Next post => Latest Posts 8 Ways to Scale your Data Science Workloads Vibe Coding Something Useful with Repl.it
Generative AI: A Self-Study Roadmap Get the FREE ebook The Great Big Natural Language Processing Primer and The Complete Collection of Data Science Cheat Sheets along with the leading newsletter on Data Science, Machine Learning, AI & Analytics straight to your inbox.
Top Posts 7 Python Web Development Frameworks for Data Scientists Build Your Own Simple DataPipeline with Python and Docker 10 GitHub Repositories for Machine Learning Projects 10 Python One-Liners for JSON Parsing and Processing What Does Python’s __slots__ Actually Do?
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 10 Free Online Courses to Master Python in 2025 How can you master Python for free?
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter The Lifecycle of Feature Engineering: From Raw Data to Model-Ready Inputs This article explains how (..)
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter What Does Python’s __slots__ Actually Do?
In Part 1 of this series, we explored how Amazon’s Worldwide Returns & ReCommerce (WWRR) organization built the Returns & ReCommerce Data Assist (RRDA)—a generative AI solution that transforms natural language questions into validated SQL queries using Amazon Bedrock Agents.
They have structured data such as sales transactions and revenue metrics stored in databases, alongside unstructured data such as customer reviews and marketing reports collected from various channels. Use Amazon Athena SQL queries to provide insights.
Instead of sweating the syntax, you describe the “ vibe ” of what you want—be it a datapipeline, a web app, or an analytics automation script—and frameworks like Replit, GitHub Copilot, Gemini Code Assist, and others do the heavy lifting. Learn more at Gemini Code Assist. Yes, with proper validation, testing, and reviews.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Choose Delete stack.
By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: Latest Posts Benefits of Using LiteLLM for Your LLM Apps 5 Fun Generative AI Projects for Absolute Beginners 8 Ways to Scale your Data Science Workloads Vibe Coding Something Useful with Repl.it
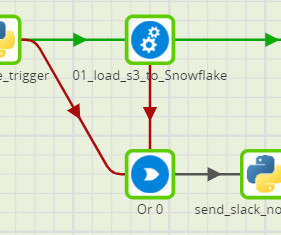
Scheduled Analysis Replace the Manual Trigger with a Schedule Trigger to automatically analyze datasets at regular intervals, perfect for monitoring data sources that update frequently. This proactive approach helps you identify datapipeline issues before they impact downstream analysis or model performance.
Knowledge-intensive analytical applications retrieve context from both structured tabular data and unstructured, text-free documents for effective decision-making. Large language models (LLMs) have made it significantly easier to prototype such retrieval and reasoning datapipelines.
Databricks recently announced Lakeflow Connect in Jobs, which enables you to create ingestion pipelines within Lakeflow Jobs. We have also continued innovating for customers who want more customization options and use our existing ingestion solution, Auto Loader.
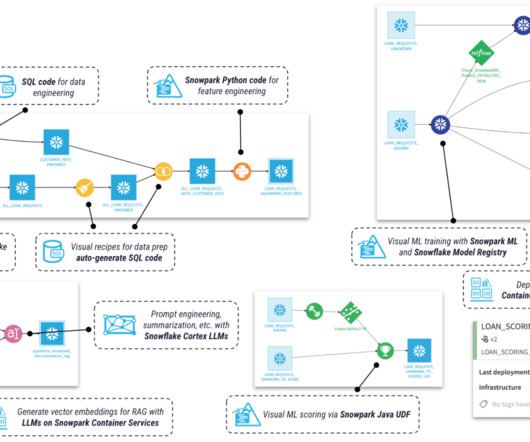
We also introduced Lakeflow Declarative Pipelines’ new IDE for data engineering (shown above), built from the ground up to streamline pipeline development with features like code-DAG pairing, contextual previews, and AI-assisted authoring. Preview coming soon.
Feeding data for analytics Integrated data is essential for populating data warehouses, data lakes, and lakehouses, ensuring that analysts have access to complete datasets for their work. Data integration tools and techniques The landscape of data integration is constantly evolving, driven by technological advancements.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 5 Fun Generative AI Projects for Absolute Beginners New to generative AI?
A Complete Guide to Matplotlib: From Basics to Advanced Plots The Basics of Debugging Python Problems Get the FREE ebook The Great Big Natural Language Processing Primer and The Complete Collection of Data Science Cheat Sheets along with the leading newsletter on Data Science, Machine Learning, AI & Analytics straight to your inbox.
Responsibilities of a data engineer The responsibilities of a data engineer can be extensive. They are primarily tasked with the creation and maintenance of robust datapipelines that ensure seamless data flow from source to destination.
A provisioned or serverless Amazon Redshift data warehouse. Basic knowledge of a SQL query editor. Implementation steps Load data to the Amazon Redshift cluster Connect to your Amazon Redshift cluster using Query Editor v2. For this post we’ll use a provisioned Amazon Redshift cluster. A SageMaker domain.
With all this packaged into a well-governed platform, Snowflake continues to set the standard for data warehousing and beyond. Snowflake supports data sharing and collaboration across organizations without the need for complex datapipelines.
Based on the customer query and context, the system dynamically generates text-to-SQL queries, summarizes knowledge base results using semantic search , and creates personalized vehicle brochures based on the customers preferences. This seamless process is facilitated by Retrieval Augmentation Generation (RAG) and a text-to-SQL framework.
This following diagram illustrates the enhanced data extract, transform, and load (ETL) pipeline interaction with Amazon Bedrock. To achieve the desired accuracy in KPI calculations, the datapipeline was refined to achieve consistent and precise performance, which leads to meaningful insights.
The agent can generate SQL queries using natural language questions using a database schema DDL (data definition language for SQL) and execute them against a database instance for the database tier. Make sure to add a semicolon after the end of the SQL statement generated. Create, invoke, test, and deploy the agent.
This tool democratizes data access across the organization, enabling even nontechnical users to gain valuable insights. A standout application is the SQL-to-natural language capability, which translates complex SQL queries into plain English and vice versa, bridging the gap between technical and business teams.
What we like most about Openflow is that it simplifies data ingestion from multiple sources and accelerates Snowflake customers’ success by eliminating the need for third-party ingestion tools, enabling quick prototyping, and supporting reusable datapipelines. Multiple tables can be loaded iteratively in parallel.
Intuitive Workflow Design Workflows should be easy to follow and visually organized, much like clean, well-structured SQL or Python code. WHERE d.name = 'Sales'; Matillion is designed as a no/low-code ELT tool, so lets leave the SQL deep dive for another time and focus on making workflows as clean and intuitive as possible!
Key Skills for Data Science: A data scientist typically needs a blend of skills: Mathematics and Statistics: To understand the theoretical underpinnings of models. Programming: Often in languages like Python or R, using libraries for data manipulation, analysis, and machine learning.
However, if the tool supposes an option where we can write our custom programming code to implement features that cannot be achieved using the drag-and-drop components, it broadens the horizon of what we can do with our datapipelines. JV_STAGING_TBL} Here is what the outline of the pipeline looks like. Contact phData Today!
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the datapipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a data warehouse. Thus, it has only a minimal footprint.
This standard simplifies pipeline development across batch and streaming workloads. Years of real-world experience have shaped this flexible, Spark-native approach for both batch and streaming pipelines. that evolution continues with major advances in streaming, Python, SQL, and semi-structured data.
To establish trust between the data producers and data consumers, SageMaker Catalog also integrates the data quality metrics and data lineage events to track and drive transparency in datapipelines. Create a SageMaker Unified Studio domain and three projects using the SQL analytics project profile.
SQL and MongoDB SQL remains critical for structured data management, while MongoDB caters to NoSQL database needs, which is essential for modern and flexible data applications. Next Steps: Transition into data engineering (PySpark, ETL) or machine learning (TensorFlow, PyTorch). Most Sought-After Skills 1.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content