This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
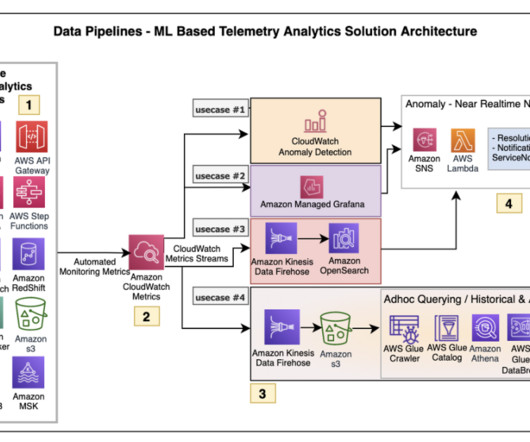
Datapipelines are essential in our increasingly data-driven world, enabling organizations to automate the flow of information from diverse sources to analytical platforms. What are datapipelines? Purpose of a datapipelineDatapipelines serve various essential functions within an organization.
Kafka is based on the idea of a distributed commit log, which stores and manages streams of information that can still work even […] The post Build a Scalable DataPipeline with Apache Kafka appeared first on Analytics Vidhya. It was made on LinkedIn and shared with the public in 2011.
Introduction Imagine yourself as a data professional tasked with creating an efficient datapipeline to streamline processes and generate real-time information. Sounds challenging, right? That’s where Mage AI comes in to ensure that the lenders operating online gain a competitive edge.
Datapipelines automatically fetch information from various disparate sources for further consolidation and transformation into high-performing data storage. There are a number of challenges in data storage , which datapipelines can help address. Choosing the right datapipeline solution.
Introduction Companies can access a large pool of data in the modern business environment, and using this data in real-time may produce insightful results that can spur corporate success. Real-time dashboards such as GCP provide strong data visualization and actionable information for decision-makers.
A datapipeline is a technical system that automates the flow of data from one source to another. While it has many benefits, an error in the pipeline can cause serious disruptions to your business. Here are some of the best practices for preventing errors in your datapipeline: 1. Monitor Your Data Sources.
The solution is designed to provide customers with a detailed, personalized explanation of their preferred features, empowering them to make informed decisions. Requested information is intelligently fetched from multiple sources such as company product metadata, sales transactions, OEM reports, and more to generate meaningful responses.
Accurate and secure data can help to streamline software engineering processes and lead to the creation of more powerful AI tools, but it has become a challenge to maintain the quality of the expansive volumes of data needed by the most advanced AI models. Featured image credit: Shubham Dhage/Unsplash
Many scenarios call for up-to-the-minute information. Enterprise technology is having a watershed moment; no longer do we access information once a week, or even once a day. Now, information is dynamic. Business success is based on how we use continuously changing data. What is a streaming datapipeline?
Let’s explore each of these components and its application in the sales domain: Synapse Data Engineering: Synapse Data Engineering provides a powerful Spark platform designed for large-scale data transformations through Lakehouse. Here, we changed the data types of columns and dealt with missing values.
The key to being truly data-driven is having access to accurate, complete, and reliable data. In fact, Gartner recently found that organizations believe […] The post How to Assess Data Quality Readiness for Modern DataPipelines appeared first on DATAVERSITY.
This approach not only enhances data diversity but also alleviates privacy concerns related to sensitive patient data. Image by author This approach not only increases data diversity but also addresses privacy concerns related to sharing sensitive patient information. Example prompt use case #3.
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
Datapipelines are like insurance. ETL processes are constantly toiling away behind the scenes, doing heavy lifting to connect the sources of data from the real world with the warehouses and lakes that make the data useful. You only know they exist when something goes wrong.
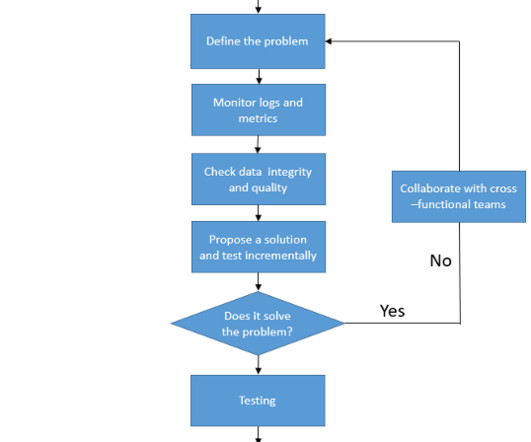
Establishing the foundation for scalable datapipelines Initiating the process of creating scalable datapipelines requires addressing common challenges such as data fragmentation, inconsistent quality and siloed team operations.
Datapipelines are a set of processes that move data from one place to another, typically from the source of data to a storage system. These processes involve data extraction from various sources, transformation to fit business or technical needs, and loading into a final destination for analysis or reporting.
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
In part one of this blog post, we described why there are many challenges for developers of datapipeline testing tools (complexities of technologies, large variety of data structures and formats, and the need to support diverse CI/CD pipelines).
Over the last few years, with the rapid growth of data, pipeline, AI/ML, and analytics, DataOps has become a noteworthy piece of day-to-day business New-age technologies are almost entirely running the world today. Among these technologies, big data has gained significant traction. This concept is …
Big datapipelines are the backbone of modern data processing, enabling organizations to collect, process, and analyze vast amounts of data in real-time. Issues such as data inconsistencies, performance bottlenecks, and failures are inevitable.In Validate data format and schema compatibility.
“Data is at the center of every application, process, and business decision,” wrote Swami Sivasubramanian, VP of Database, Analytics, and Machine Learning at AWS, and I couldn’t agree more. A common pattern customers use today is to build datapipelines to move data from Amazon Aurora to Amazon Redshift.
ETL pipelines are revolutionizing the way organizations manage data by transforming raw information into valuable insights. They serve as the backbone of data-driven decision-making, allowing businesses to harness the power of their data through a structured process that includes extraction, transformation, and loading.
Those who want to design universal datapipelines and ETL testing tools face a tough challenge because of the vastness and variety of technologies: Each datapipeline platform embodies a unique philosophy, architectural design, and set of operations.
Today’s datapipelines use transformations to convert raw data into meaningful insights. Yet, ensuring the accuracy and reliability of these transformations is no small feat – tools and methods to test the variety of data and transformation can be daunting.
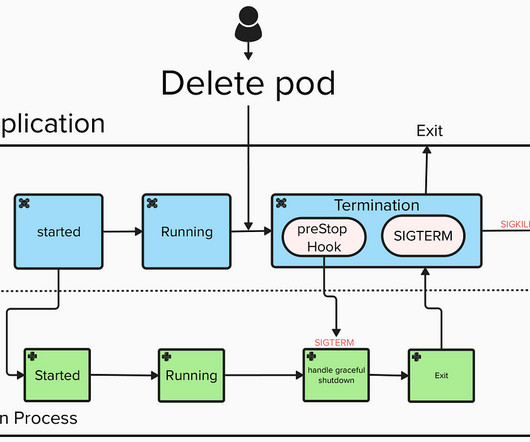
Graceful External Termination: Handling Pod Deletions in Kubernetes Data Ingestion and Streaming Jobs When running big-datapipelines in Kubernetes, especially streaming jobs, its easy to overlook how these jobs deal with termination. If not handled correctly, this can lead to locks, data issues, and a negative user experience.
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the datapipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a data warehouse.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
The development of a Machine Learning Model can be divided into three main stages: Building your ML datapipeline: This stage involves gathering data, cleaning it, and preparing it for modeling. This information can be used to inform the design of the model.
While speaking at AIMs event DES 2025, Manjunatha G, engineering and site leader at the 3M Global Technology Centre, laid out a practical path to integrate AI agents into data engineering workflows.
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. After ingesting the data, you create an agent with specific instructions: agent_instruction = """You are the Amazon Bedrock Agent.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Port: Redshift 5439. Database name: dev.
Home Table of Contents Adversarial Learning with Keras and TensorFlow (Part 2): Implementing the Neural Structured Learning (NSL) Framework and Building a DataPipeline Adversarial Learning with NSL CIFAR-10 Dataset Configuring Your Development Environment Need Help Configuring Your Development Environment? We open our config.py
Understanding the purpose of complex event processing CEP serves to monitor vast data streams from diverse sources, including but not limited to sensors, social media, and financial markets, facilitating enhanced decision-making. Real-time data management The importance of real-time data in todays analytics landscape cannot be overstated.
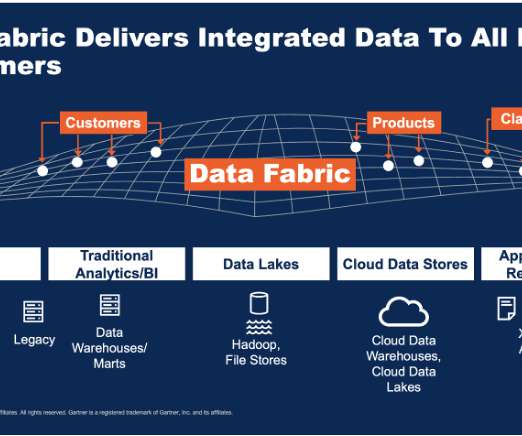
One of the key elements that builds a data fabric architecture is to weave integrated data from many different sources, transform and enrich data, and deliver it to downstream data consumers. As a part of datapipeline, Address Verification Interface (AVI) can remediate bad address data.
Data is one of the most critical assets of many organizations. Theyre constantly seeking ways to use their vast amounts of information to gain competitive advantages. This enables OMRON to extract meaningful patterns and trends from its vast data repositories, supporting more informed decision-making at all levels of the organization.
ERP (Enterprise Resource Planning) systems contain information about finance, supplier management, human resources and other operational processes, while CRM (Customer Relationship Management) systems provide data about customer relationships, marketing and sales activities. Copyright by DATANOMIQ.
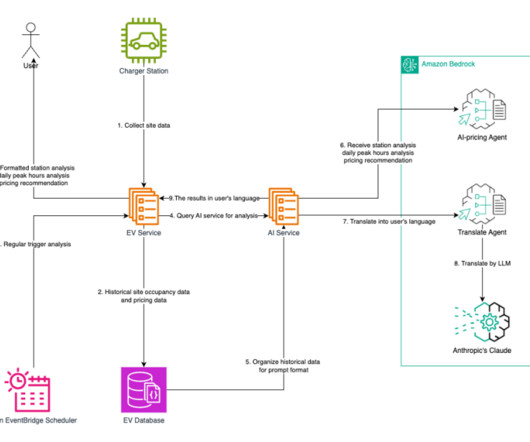
Traditional systems lack the capability to efficiently process vast amounts of real-time and historical data or provide personalized, station-level recommendations. This limits operators ability to make timely, informed decisionsresulting in higher electricity costs, underutilized assets, and a subpar customer experience.
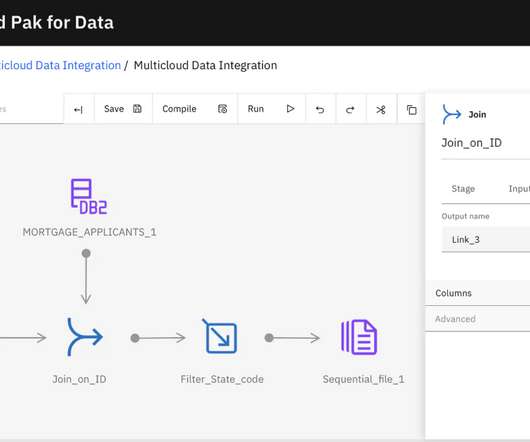
See how Preciselys Data Integration Solutions can help your business stream real-time application data from legacy systems to mission critical business applications and analytics platforms. These architectures prioritize: Real-time data availability: Ensuring that data is accessible and actionable the moment it is generated.
Implementing a data fabric architecture is the answer. What is a data fabric? Data fabric is defined by IBM as “an architecture that facilitates the end-to-end integration of various datapipelines and cloud environments through the use of intelligent and automated systems.”
Unstructured data that has been cleared to suit a plan, sort out into tables, and defined by relationships and types, is known as structured data. This is a vital disparity between data warehouses and data lakes. Data warehouses contain historical information that has been cleared to suit a relational plan.
Companies are spending a lot of money on data and analytics capabilities, creating more and more data products for people inside and outside the company. These products rely on a tangle of datapipelines, each a choreography of software executions transporting data from one place to another.
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. What Does a Data Engineer Do?
Throughout the course of history, the significance of creating and disseminating information has been immensely crucial. By applying statistical concepts such as central tendency, variability, and correlation, data scientists can gain insights into the underlying structure of data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content