This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The market for datawarehouses is booming. While there is a lot of discussion about the merits of datawarehouses, not enough discussion centers around data lakes. We talked about enterprise datawarehouses in the past, so let’s contrast them with data lakes. DataWarehouse.
Datapipelines automatically fetch information from various disparate sources for further consolidation and transformation into high-performing data storage. There are a number of challenges in data storage , which datapipelines can help address. Choosing the right datapipeline solution.
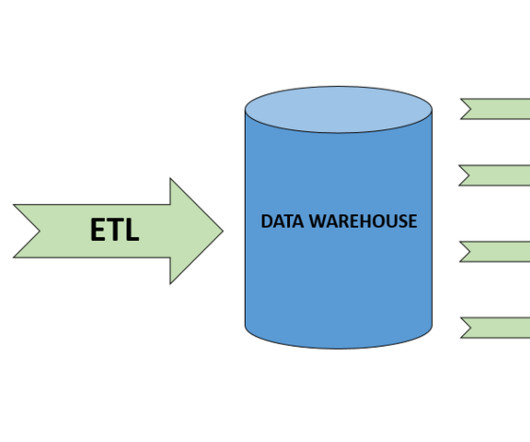
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
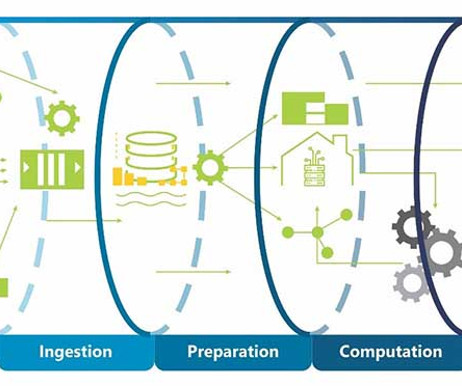
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports.
Accurate and secure data can help to streamline software engineering processes and lead to the creation of more powerful AI tools, but it has become a challenge to maintain the quality of the expansive volumes of data needed by the most advanced AI models. Featured image credit: Shubham Dhage/Unsplash
Introduction Companies can access a large pool of data in the modern business environment, and using this data in real-time may produce insightful results that can spur corporate success. Real-time dashboards such as GCP provide strong data visualization and actionable information for decision-makers.
It was only a few years ago that BI and data experts excitedly claimed that petabytes of unstructured data could be brought under control with datapipelines and orderly, efficient datawarehouses. But as big data continued to grow and the amount of stored information increased every […].
ETL pipelines are revolutionizing the way organizations manage data by transforming raw information into valuable insights. They serve as the backbone of data-driven decision-making, allowing businesses to harness the power of their data through a structured process that includes extraction, transformation, and loading.
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
In this post, we will be particularly interested in the impact that cloud computing left on the modern datawarehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Understanding the Basics What is a DataWarehouse?
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the datapipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a datawarehouse.
Suppose you’re in charge of maintaining a large set of datapipelines from cloud storage or streaming data into a datawarehouse. How can you ensure that your data meets expectations after every transformation? That’s where data quality testing comes in.
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
The emergence of advanced data storage technologies, such as cloud computing, data hubs, and data lakes, makes us question the role of traditional datawarehouses in modern data architecture. Datawarehouses were first introduced in the […] The post Are DataWarehouses Still Relevant?
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? Xoriant It is common to use ETL datapipeline and datapipeline interchangeably.
Data is one of the most critical assets of many organizations. Theyre constantly seeking ways to use their vast amounts of information to gain competitive advantages. This enables OMRON to extract meaningful patterns and trends from its vast data repositories, supporting more informed decision-making at all levels of the organization.
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. What Does a Data Engineer Do?
Big data engineers are essential in today’s data-driven landscape, transforming vast amounts of information into valuable insights. As businesses increasingly depend on big data to tailor their strategies and enhance decision-making, the role of these engineers becomes more crucial.
Data engineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and data engineers are responsible for designing and implementing the systems and infrastructure that make this possible.
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
The acronym ETL—Extract, Transform, Load—has long been the linchpin of modern data management, orchestrating the movement and manipulation of data across systems and databases. This methodology has been pivotal in data warehousing, setting the stage for analysis and informed decision-making.
As they grow in both their complexity and data production/consumption, a data governance strategy needs to be designed as part of your information architecture. What is a Cloud DataWarehouse? For example, most datawarehouse workloads peak during certain times, say during business hours.
Data is processed to generate information, which can be later used for creating better business strategies and increasing the company’s competitive edge. It’s obvious that you’ll want to use big data, but it’s not so obvious how you’re going to work with it. Preserve information: Keep your raw data raw.
Fivetran, a cloud-based automated data integration platform, has emerged as a leading choice among businesses looking for an easy and cost-effective way to unify their data from various sources. Fivetran is used by businesses to centralize data from various sources into a single, comprehensive datawarehouse.
With the explosive growth of big data over the past decade and the daily surge in data volumes, it’s essential to have a resilient system to manage the vast influx of information without failures. The success of any data initiative hinges on the robustness and flexibility of its big datapipeline.
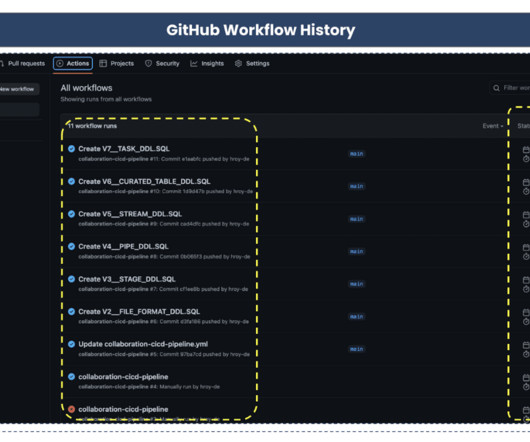
which play a crucial role in building end-to-end datapipelines, to be included in your CI/CD pipelines. These practices also establish a unified and reliable source of information for all changes, ensuring that the history of changes is readily accessible for auditing purposes.
While growing data enables companies to set baselines, benchmarks, and targets to keep moving ahead, it poses a question as to what actually causes it and what it means to your organization’s engineering team efficiency. What’s causing the data explosion? Big data analytics from 2022 show a dramatic surge in information consumption.
But good data—and actionable insights—are hard to get. Traditionally, organizations built complex datapipelines to replicate data. Those data architectures were brittle, complex, and time intensive to build and maintain, requiring data duplication and bloated datawarehouse investments.
But good data—and actionable insights—are hard to get. Traditionally, organizations built complex datapipelines to replicate data. Those data architectures were brittle, complex, and time intensive to build and maintain, requiring data duplication and bloated datawarehouse investments.
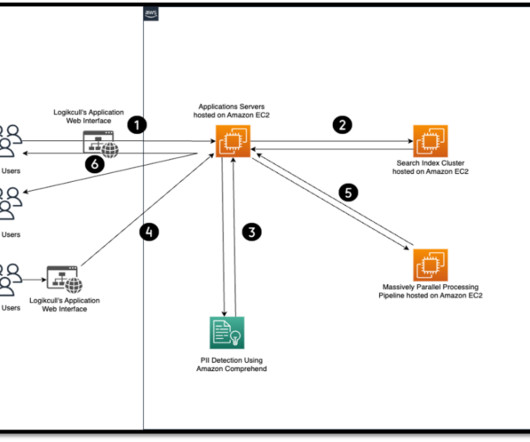
Today, personally identifiable information (PII) is everywhere. It refers to any data or information that can be used to identify a specific individual. It’s a critical component of modern data management and cybersecurity practices. PII is in emails, slack messages, videos, PDFs, and so on.
Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. It involves developing datapipelines that efficiently transport data from various sources to storage solutions and analytical tools. ETL is vital for ensuring data quality and integrity.
In July 2023, Matillion launched their fully SaaS platform called Data Productivity Cloud, aiming to create a future-ready, everyone-ready, and AI-ready environment that companies can easily adopt and start automating their datapipelines coding, low-coding, or even no-coding at all.
Run pandas at scale on your datawarehouse Most enterprise data teams store their data in a database or datawarehouse, such as Snowflake, BigQuery, or DuckDB. Ponder solves this problem by translating your pandas code to SQL that can be understood by your datawarehouse.
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development.
Automating myriad steps associated with pipelinedata processing, helps you convert the data from its raw shape and format to a meaningful set of information that is used to drive business decisions. In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing.
Data Quality Now that you’ve learned more about your data and cleaned it up, it’s time to ensure the quality of your data is up to par. With these data exploration tools, you can determine if your data is accurate, consistent, and reliable. You can watch it on demand here.
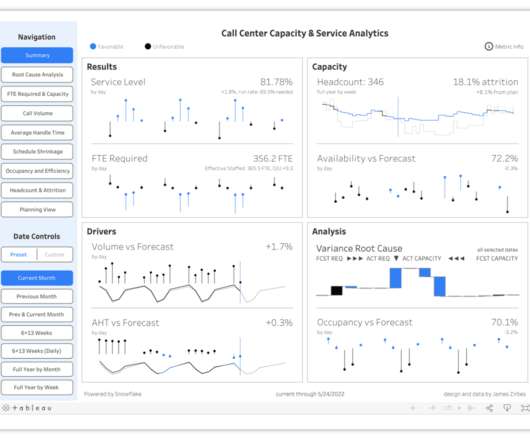
More and more businesses are looking to better leverage their outsourced call center data to make more data-driven decisions. To do this on your own, you would need to create a datawarehouse, optimize the reporting performance, and very clearly visualize the data. How Does Snowflake Help with Call Centers?
This process enables organisations to gather data from various sources, transform it into a usable format, and load it into datawarehouses or databases for analysis. Efficient management of ETL Data is essential for businesses seeking to leverage their information for strategic decision-making.
Today, companies are facing a continual need to store tremendous volumes of data. The demand for information repositories enabling business intelligence and analytics is growing exponentially, giving birth to cloud solutions. The platform enables quick, flexible, and convenient options for storing, processing, and analyzing data.
So let’s do a quick overview of the job of data engineer, and maybe you might find a new interest. Building and maintaining datapipelinesData integration is the process of combining data from multiple sources into a single, consistent view. Think of data engineers as the architects of the data ecosystem.
Introduction In todays data-driven world, organizations are overwhelmed with vast amounts of information. By 2025, global data volumes are expected to reach 181 zettabytes, according to IDC. This includes operations like data validation, data cleansing, data aggregation, and data normalization.
They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. This involves working closely with data analysts and data scientists to ensure that data is stored, processed, and analyzed efficiently to derive insights that inform decision-making.
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content