This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Neuron is the SDK used to run deeplearning workloads on Trainium and Inferentia based instances. High latency may indicate high user demand or inefficient datapipelines, which can slow down response times. This data makes sure models are being trained smoothly and reliably.
As such, the quality of their data can make or break the success of the company. This article will guide you through the concept of a dataquality framework, its essential components, and how to implement it effectively within your organization. What is a dataquality framework?
Harrison Chase, CEO and Co-founder of LangChain Michelle Yi and Amy Hodler Sinan Ozdemir, AI & LLM Expert | Author | Founder + CTO of LoopGenius Steven Pousty, PhD, Principal and Founder of Tech Raven Consulting Cameron Royce Turner, Founder and CEO of TRUIFY.AI
Dataquality control: Robust dataset labeling and annotation tools incorporate quality control mechanisms such as inter-annotator agreement analysis, review workflows, and data validation checks to ensure the accuracy and reliability of annotations. Data monitoring tools help monitor the quality of the data.
Key skills and qualifications for machine learning engineers include: Strong programming skills: Proficiency in programming languages such as Python, R, or Java is essential for implementing machine learning algorithms and building datapipelines.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
Zeta’s AI innovations over the past few years span 30 pending and issued patents, primarily related to the application of deeplearning and generative AI to marketing technology. It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing datapipelines.
Beyond architecture, engineers are finding value in other methods, such as quantization , chips designed specifically for inference, and fine-tuning , a deeplearning technique that involves adapting a pretrained model for specific use cases. In this context, dataquality often outweighs quantity.
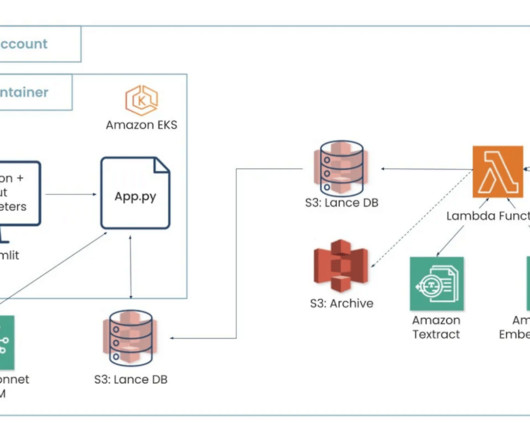
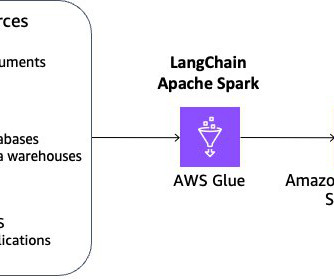
To help, phData designed and implemented AI-powered datapipelines built on the Snowflake AI Data Cloud , Fivetran, and Azure to automate invoice processing. phData’s Approach phData implemented Optical Character Recognition (OCR), which was performed using the open-source tool Paddle (Parallel Distributed DeepLearning).
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
LLM models are large deeplearning models that are trained on vast datasets, are adaptable to various tasks and specialize in NLP tasks. They are characterized by their enormous size, complexity, and the vast amount of data they process. Continuous monitoring of resources, data, and metrics.
This step includes: Identifying Data Sources: Determine where data will be sourced from (e.g., Ensuring Time Consistency: Ensure that the data is organized chronologically, as time order is crucial for time series analysis. databases, APIs, CSV files).
As computational power increased and data became more abundant, AI evolved to encompass machine learning and data analytics. This close relationship allowed AI to leverage vast amounts of data to develop more sophisticated models, giving rise to deeplearning techniques.
Olalekan said that most of the random people they talked to initially wanted a platform to handle dataquality better, but after the survey, he found out that this was the fifth most crucial need. And when the platform automates the entire process, it’ll likely produce and deploy a bad-quality model. Allegro.io
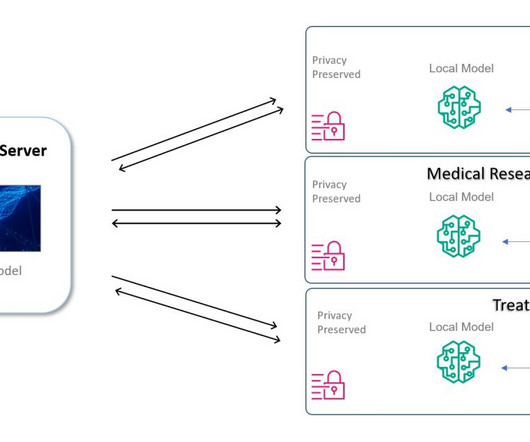
First, you need to address the data heterogeneity problem with medical imaging data arising from data being stored across different sites and participating organizations, known as a domain shift problem (also referred to as client shift in an FL system), as highlighted by Guan and Liu in the following paper.
Internally within Netflix’s engineering team, Meson was built to manage, orchestrate, schedule, and execute workflows within ML/Datapipelines. Meson managed the lifecycle of ML pipelines, providing functionality such as recommendations and content analysis, and leveraged the Single Leader Architecture.
Large language models (LLMs) are very large deep-learning models that are pre-trained on vast amounts of data. Datapipelines must seamlessly integrate new data at scale. Diverse data amplifies the need for customizable cleaning and transformation logic to handle the quirks of different sources.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content